
Hadoop中reduce端shuffle過程及原始碼解析
一、概要描述
在Child的main函式中通過TaskUmbilicalProtocol協議,從TaskTracker獲得需要執行的Task,並呼叫Task的run方法來執行。在ReduceTask而Task的run方法會通過java反射機制構造Reducer,Reducer.Context,然後呼叫構造的Reducer的run方法執行reduce操作。不同於map任務,在執行reduce任務前,需要把map的輸出從map執行的tasktracker上拷貝到reducer執行的tasktracker上。
Reduce需要叢集上若干個map任務的輸出作為其特殊的分割槽檔案。每個map任務完成的時間可能不同,因此只要有一個任務完成,reduce任務就開始複製其輸出。這就是reduce任務的複製階段。其實是啟動若干個MapOutputCopier執行緒來複制完所有map輸出。在複製完成後reduce任務進入排序階段。這個階段將由LocalFSMerger或InMemFSMergeThread合併map輸出,維持其順序排序。【即對有序的幾個檔案進行歸併,採用歸併排序】在reduce階段,對已排序輸出的每個鍵都要呼叫reduce函式,此階段的輸出直接寫到檔案系統,一般為HDFS上。(如果採用HDFS,由於tasktracker節點也是DataNoe,所以第一個塊副本將被寫到本地磁碟。 即資料本地化)
二、 流程描述
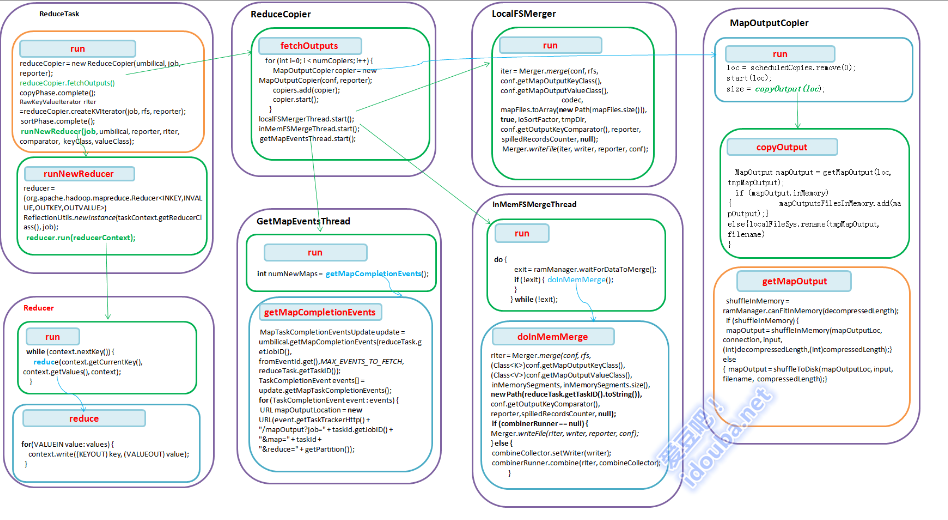
1.在ReduceTak中 構建ReduceCopier物件,呼叫其fetchOutputs方法。
2. 在ReduceCopier的fetchOutputs方法中分別構造幾個獨立的執行緒。相互配合,並分別獨立的完成任務。
2.1 GetMapEventsThread執行緒通過RPC詢問TaskTracker,對每個完成的Event,獲取maptask所在的伺服器地址,即MapTask輸出的地址,構造URL,加入到mapLocations,供copier執行緒獲取。
2.2構造並啟動若干個MapOutputCopier執行緒,通過http協議,把map的輸出從遠端伺服器拷貝的本地,如果可以放在記憶體中,則儲存在記憶體中呼叫,否則儲存在本地檔案。
2.3LocalFSMerger對磁碟上的map 輸出進行歸併。
2.4nMemFSMergeThread對記憶體中的map輸出進行歸併。
3.根據拷貝到的map輸出構造一個raw keyvalue的迭代器,作為reduce的輸入。
4. 呼叫runNewReducer方法中根據配置的Reducer類構造一個Reducer例項和執行的上下文。並呼叫reducer的run方法來執行到使用者定義的reduce操作。
5.在Reducer的run方法中從上下文中取出一個key和該key對應的Value集合(Iterable型別),呼叫reducer的reduce方法進行處理。
6. Recuer的reduce方法是使用者定義的處理資料的方法,也是使用者唯一需要定義的方法。
三、程式碼詳細
ReduceTask的run方法。
@SuppressWarnings("unchecked")
public void run(JobConf job, final TaskUmbilicalProtocol umbilical)
throws IOException, InterruptedException, ClassNotFoundException {
job.setBoolean("mapred.skip.on", isSkipping());
if (isMapOrReduce()) {
copyPhase = getProgress().addPhase("copy" ReduceTask的runNewReducer方法。根據配置構造reducer以及其執行的上下文,呼叫reducer的reduce方法。
Java
@SuppressWarnings("unchecked")
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewReducer(JobConf job,
final TaskUmbilicalProtocol umbilical,
final TaskReporter reporter,
RawKeyValueIterator rIter,
RawComparator<INKEY> comparator,
Class<INKEY> keyClass,
Class<INVALUE> valueClass
) throws IOException,InterruptedException,
ClassNotFoundException {
//1. 構造TaskContext
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.TaskAttemptContext(job, getTaskID());
//2. 根據配置的Reducer類構造一個Reducer例項
org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE> reducer = (org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getReducerClass(), job);
//3. 構造RecordWriter
org.apache.hadoop.mapreduce.RecordWriter<OUTKEY,OUTVALUE> output =
(org.apache.hadoop.mapreduce.RecordWriter<OUTKEY,OUTVALUE>)
outputFormat.getRecordWriter(taskContext);
job.setBoolean("mapred.skip.on", isSkipping());
//4. 構造Context,是Reducer執行的上下文
org.apache.hadoop.mapreduce.Reducer.Context
reducerContext = createReduceContext(reducer, job, getTaskID(),
rIter, reduceInputValueCounter,
output, committer,
reporter, comparator, keyClass,
valueClass);
reducer.run(reducerContext);
output.close(reducerContext);
}抽象類Reducer的run方法。從上下文中取出一個key和該key對應的Value集合(Iterable型別),呼叫reducer的reduce方法進行處理。
3
4
5
6
7
public void run(Context context) throws IOException, InterruptedException {
setup(context);
while (context.nextKey()) {
reduce(context.getCurrentKey(), context.getValues(), context);
}
cleanup(context);
}Reducer類的reduce,是使用者一般會覆蓋來執行reduce處理邏輯的方法。
@SuppressWarnings("unchecked")
protected void reduce(KEYIN key, Iterable<VALUEIN> values, Context context
) throws IOException, InterruptedException {
for(VALUEIN value: values) {
context.write((KEYOUT) key, (VALUEOUT) value);
}