
Memcache(MC)系列(一)Memcache介紹、使用、儲存、演算法、優化
寫在前面:前不久在工作中被問到關於MC一致雜湊的問題,由於時隔太久幾乎忘記,特前來惡補一下MC,以下是前幾年在工作中學習MC時的一些資料,來歷不明,特整理一下,希望對大家的學習也能有所幫助。
1、memcached 介紹
1.1 memcached 是什麼?
memcached 是以LiveJournal旗下Danga Interactive 公司的Brad Fitzpatric 為首開發的一款軟體。現在已成為mixi、hatena、Facebook、Vox、LiveJournal 等眾多服務中提高Web
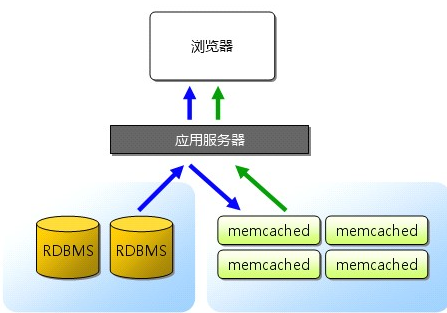
應用擴充套件性的重要因素。許多Web 應用都將資料儲存到RDBMS 中,應用伺服器從中讀取資料並在瀏覽器中顯示。但隨著資料量的增大、訪問的集中,就會出現RDBMS 的負擔加重、資料庫響應惡化、網站顯示延遲等重大影響。這時就該memcached 大顯身手了。memcached 是高效能的分散式記憶體快取伺服器。一般的使用目的是,通過快取資料庫查詢結果,減少資料庫訪問次數,以提高動態Web 應用的速度、提高可擴充套件性。
內建記憶體儲存方式
為了提高效能,memcached 中儲存的資料都儲存在memcached 內建的記憶體儲存空間中。由於資料僅存在於記憶體中,因此重啟memcached、重啟作業系統會導致全部資料消失。另外,內容容量達到指定值之後,就基於LRU(Least Recently Used)演算法自動刪除不使用的快取。memcached 本身是為快取而設計的伺服器,因此並沒有過多考慮資料的永久性問題
memcached 不互相通訊的分散式
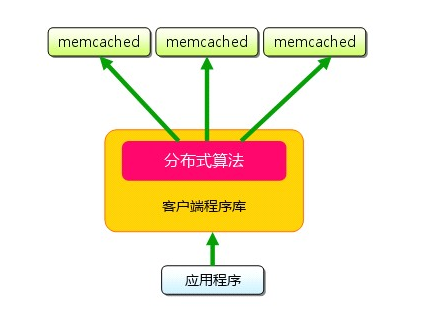
memcached 儘管是“分散式”快取伺服器,但伺服器端並沒有分散式功能。各個memcached 不會互相通訊以共享資訊。那麼,怎樣進行分散式呢?這完全取決於客戶端的實現。
2.2 memcached 啟動
memcached 啟動的命令在安裝目錄的bin 二級目錄下,如/home/test/app/memcahced-1.4.2/bin/memcached -p 11222 -m 128–d
常用的一些啟動選項介紹選項說明
-p 偵聽的埠,預設為11211
-m 使用記憶體大小,預設的64m
-d 作為daemon 在後臺啟動
-vv 用very vrebose 模式啟動,除錯資訊和錯誤輸出到控制檯
-l 偵聽的地址,預設為所有可以訪問的地址
-M 用於在記憶體溢位的時候,返回一個錯誤,禁止自動的移出數
據,替代的是返回一個error
-P Pid 檔案存在的路徑,僅限加上-d 引數是用
-c 最大同時的連線數,預設為1024
其它的一些選項,可以通過–h 命令來進行檢視
2.3命令列訪問memcached
下面假設memcached 啟動時的-p 引數為11311,命令操作在啟動memcached
本機首先telnet 連線到memcached 伺服器
telnet 127.0.0.1 11311
telnet 成功之後,大概會顯示下面的資訊
Trying 127.0.0.1...
Connected to localhost.localdomain (127.0.0.1).
Escape character is '^]'.
各種狀態(stats)
STAT <name> <value>\r\n
如:stats命令,則返回以下資訊:
stats
STAT pid 26804
STAT uptime 182783
STAT time 1404973716
STAT version 1.4.13
STAT libevent 2.0.11-stable
STAT pointer_size 64
STAT rusage_user 2.320647
STAT rusage_system 5.411177
STAT curr_connections 34
STAT total_connections 558
STAT connection_structures 37
STAT reserved_fds 20
STAT cmd_get 127292
STAT cmd_set 60056
STAT cmd_flush 145
STAT cmd_touch 0
STAT get_hits 83811
STAT get_misses 43481
STAT delete_misses 15970
STAT delete_hits 11992
STAT incr_misses 0
STAT incr_hits 0
STAT decr_misses 0
STAT decr_hits 0
STAT cas_misses 0
STAT cas_hits 0
STAT cas_badval 0
STAT touch_hits 0
STAT touch_misses 0
STAT auth_cmds 0
STAT auth_errors 0
STAT bytes_read 14300156
STAT bytes_written 11507140
STAT limit_maxbytes 134217728 # 分配給memcache的記憶體大小(位元組)
STAT accepting_conns 1
STAT listen_disabled_num 0
STAT threads 4
STAT conn_yields 0
STAT hash_power_level 16
STAT hash_bytes 524288
STAT hash_is_expanding 0
STAT expired_unfetched 16884
STAT evicted_unfetched 0
STAT bytes 609350 # 當前伺服器儲存items佔用的位元組數
STAT curr_items 4668 # 伺服器當前儲存的items數量
STAT total_items 60056
STAT evictions 0 # 分配給memcache的空間用滿後需要刪除舊的items數,踢出。
STAT reclaimed 27160 #回收再利用,已過期的資料條目來儲存新資料。
END
儲存命令(set ,add ,replace)
客戶端會發送一行像這樣的命令:
<command name> <key> <flags> <exptime> <bytes>\r\n
如:
set key1 0 600 5\r\nvalue\r\n
add key2 0 500 2\r\n
replace key1 0 600 6\r\nvalue1\r\n
詳細的命令說明,可以見附錄的memcached 中英文協議內容
讀取命令(get)
命令如下:get <key>*\r\n
- <key>* 表示一個或多個鍵值,由空格隔開的字串
如:
get key1
VALUE key1 0 7
value12
刪除命令(delete)
命令如:delete <key> <time>\r\n
<key> 是客戶端希望伺服器刪除的內容的鍵名
- <time> 是一個單位為秒的時間(或代表直到某一刻的Unix時間),在該時間內伺服器會拒絕對於此鍵名的“add”和“replace”命令。此時內容被放入delete佇列,無法再通過“get”得到該內容,也無法是用“add”和“replace”命令(但是“set”命令可用)。直到指定時間,這些內容被最終從伺服器的記憶體中徹底清除
<time>引數是可選的,預設為0(表示內容會立刻清除,並且隨後的儲存命令均可用
如:delete key1
退出命令(quit)
如:quit
4、理解memcached 的記憶體儲存
4.1Slab Allocation 機制:整理記憶體以便重複使用
最近的memcached 預設情況下采用了名為Slab Allocator 的機制分配、管理記憶體。在該機制出現以前,記憶體的分配是通過對所有記錄簡單地進行malloc和free 來進行的。但是,這種方式會導致記憶體碎片,加重作業系統記憶體管理器的負擔,最壞的情況下,會導致作業系統比memcached 程序本身還慢。Slab Allocator 就是為解決該問題而誕生的
Slab Allocation 的原理相當簡單。將分配的記憶體分割成各種尺寸的塊
(chunk),並把尺寸相同的塊分成組(chunk 的集合)

而且,slab allocator 還有重複使用已分配的記憶體的目的。也就是說,分配到的記憶體不會釋放,而是重複利用。
Slab Allocation 的主要術語
Page
分配給Slab 的記憶體空間,預設是1MB。分配給Slab 之後根據slab 的大小切分成chunk。
Chunk
用於快取記錄的記憶體空間。
Slab Class
特定大小的chunk 的組
4.2 在Slab中快取記錄的原理
memcached 根據收到的資料的大小,選擇最適合資料大小的slab,memcached 中儲存著slab 內空閒chunk 的列表,根據該列表選擇chunk,然
後將資料緩存於其中

4.3 Slab Allocator 的缺點
由於分配的是特定長度的記憶體,因此無法有效利用分配的記憶體。例如,將100 位元組的資料快取到128 位元組的chunk 中,剩餘的28位元組就浪費了
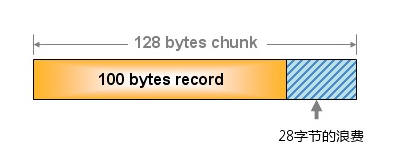
對於該問題目前還沒有完美的解決方案,但在文件中記載了比較有效的解決方案。就是說,如果預先知道客戶端傳送的資料的公用大小,或者僅快取大小相同的資料的情況下,只要使用適合資料大小的組的列表,就可以減少浪費。但是很遺憾,現在還不能進行任何調優,只能期待以後的版本了。但是,我們可以調節slab class 的大小的差別。接下來說明growth factor 選項。
4.4 使用Growth Factor進行調優
memcached 在啟動時指定Growth Factor 因子(通過f 選項),就可以在某種程度上控制slab 之間的差異。預設值為1.25。但是,在該選項出現之前,這個因子曾經固定為2,稱為“powers of 2”策略。
下面是啟動後的verbose 輸出:
slab class 1: chunk size 128 perslab 8192
slab class 2: chunk size 256 perslab 4096
slab class 3: chunk size 512 perslab 2048
slab class 4: chunk size 1024 perslab 1024
slab class 5: chunk size 2048 perslab 512
slab class 6: chunk size 4096 perslab 256
slab class 7: chunk size 8192 perslab 128
slab class 8: chunk size 16384 perslab 64
slab class 9: chunk size 32768 perslab 32
slab class 10: chunk size 65536 perslab 16
slab class 11: chunk size 131072 perslab 8
slab class 12: chunk size 262144 perslab 4
slab class 13: chunk size 524288 perslab 2
可見,從128 位元組的組開始,組的大小依次增大為原來的2 倍。這樣設定的問題是,slab 之間的差別比較大,有些情況下就相當浪費記憶體。因此,為儘量減少記憶體浪費,兩年前追加了growth factor 這個選項來看看現在的預設設定(f=1.25)時的輸出(篇幅所限,這裡只寫到第10 組):
slab class 1: chunk size 88 perslab 11915
slab class 2: chunk size 112 perslab 9362
slab class 3: chunk size 144 perslab 7281
slab class 4: chunk size 184 perslab 5698
slab class 5: chunk size 232 perslab 4519
slab class 6: chunk size 296 perslab 3542
slab class 7: chunk size 376 perslab 2788
slab class 8: chunk size 472 perslab 2221
slab class 9: chunk size 592 perslab 1771
slab class 10: chunk size 744 perslab 1409
可見,組間差距比因子為2 時小得多,更適合快取幾百位元組的記錄。從上面的輸出結果來看,可能會覺得有些計算誤差,這些誤差是為了保持位元組數的對齊而故意設定的。將memcached 引入產品,或是直接使用預設值進行部署時,最好是重新計算一下資料的預期平均長度,調整growth factor,以獲得最恰當的設定。記憶體是珍貴的資源,浪費就太可惜了。
5、memcached 刪除機制
memcached 是快取,不需要永久的儲存到伺服器上,本章介紹memcache 的刪除機制
5.1 memcached 在資料刪除方面有效的利用資源
Memcached 不會釋放已經分配的記憶體,記錄過期之後,客戶端無法再看到這一條記錄,其儲存空間就可以利用。
Lazy Expiration
memcached 內部不會監視記錄是否過期,而是在get 時檢視記錄的時間戳,檢查記錄是否過期。這種技術被稱為lazy(惰性)expiration。因此,memcached不會在過期監視上耗費CPU 時間
5.2 LRU:從快取中有效刪除資料的原理
memcached 會優先使用已超時的記錄的空間,但即使如此,也會發生追加新記錄時空間不足的情況,此時就要使用名為Least Recently Used(LRU)機制來分配空間。顧名思義,這是刪除“最近最少使用”的記錄的機制。因此,當memcached 的記憶體空間不足時(無法從slab class 獲取到新的空間時),就從最近未被使用的記錄中搜索,並將其空間分配給新的記錄。從快取的實用角度來看,該模型十分理想。不過,有些情況下LRU 機制反倒會造成麻煩。memcached 啟動時通過“M”引數可以禁止LRU,如下所示:
$ memcached -M –m 1024
啟動時必須注意的是,小寫的“m”選項是用來指定最大記憶體大小的。不指定具體數值則使用預設值64MB。
指定“M”引數啟動後,記憶體用盡時memcached 會返回錯誤。話說回來,memcached 畢竟不是儲存器,而是快取,所以推薦使用LRU
6、memcached 的分散式演算法
6.1memcached 的分散式
memcached 雖然稱為“分散式”快取伺服器,但伺服器端並沒有“分散式”功能。memcached 的分散式,則是完全由客戶端程式庫實現的。這種分散式是memcached 的最大特點
memcached 的分散式是什麼意思?
下面假設memcached 伺服器有node1~node3 三臺,應用程式要儲存鍵名為“tokyo”、“kanagawa”、“chiba”、“saitama”、“gunma”的資料
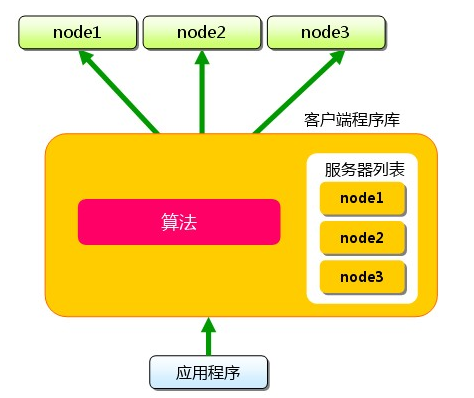
首先向memcached 中新增“tokyo”。將“tokyo”傳給客戶端程式庫後,客戶端實現的演算法就會根據“鍵”來決定儲存資料的memcached 伺服器。伺服器選定後,即命令它儲存“tokyo”及其值
同樣,“kanagawa”、“chiba”、“saitama”、“gunma”都是先選擇伺服器再保接下來獲取儲存的資料。獲取時也要將要獲取的鍵“tokyo”傳遞給函式庫。函式庫通過與資料儲存時相同的演算法,根據“鍵”選擇伺服器。使用的演算法相同,就能選中與儲存時相同的伺服器,然後傳送get 命令。只要資料沒有因為某些原因被刪除,就能獲得儲存的值。
這樣,將不同的鍵儲存到不同的伺服器上,就實現了memcached 的分散式。memcached 伺服器增多後,鍵就會分散,即使一臺memcached 伺服器發生故障無法連線,也不會影響其他的快取,系統依然能繼續執行。
6.2 餘數分散式演算法
就是“根據伺服器臺數的餘數進行分散”。求得鍵的整數雜湊值,再除以伺服器臺數,根據其餘數來選擇伺服器
餘數演算法的缺點
餘數計算的方法簡單,資料的分散性也相當優秀,但也有其缺點。那就是當新增或移除伺服器時,快取重組的代價相當巨大。新增伺服器後,餘數就會產生鉅變,這樣就無法獲取與儲存時相同的伺服器,從而影響快取的命中。
6.3Consistent Hashing(一致雜湊)
知識補充:雜湊演算法,即雜湊函式。將任意長度的二進位制值對映為較短的固定長度的二進位制值,這個小的二進位制值稱為雜湊值。雜湊值是一段資料唯一且極其緊湊的數值表示形式。如果雜湊一段明文而且哪怕只更改該段落的一個字母,隨後的雜湊都將產生不同的值。要找到雜湊為同一個值的兩個不同的輸入,在計算上是不可能的,所以資料的雜湊值可以檢驗資料的完整性。一般用於快速查詢和加密演算法。(常見的有MD5,SHA-1)
Consistent Hashing 的簡單說明
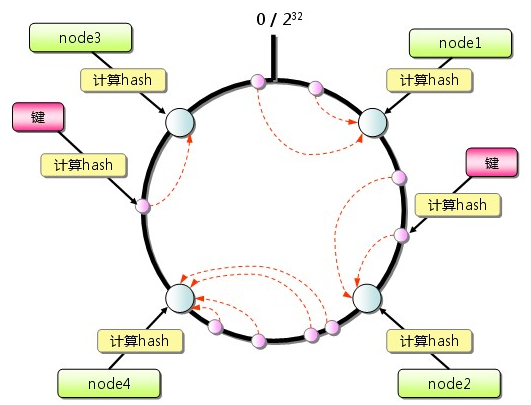
Consistent Hashing 如下所示:首先求出memcached 伺服器(節點)的雜湊值(一般的方法可以使用 cache 機器的 IP 地址或者機器名作為 hash 輸入。),並將其配置到0~232 的圓(continuum)上。然後用同樣的方法求出儲存資料的鍵的雜湊值,並對映到圓上。然後從資料對映到的位置開始順時針查詢,將資料儲存到找到的第一個伺服器上。如果超過232仍然找不到伺服器,就會儲存到第一臺memcached 伺服器上。
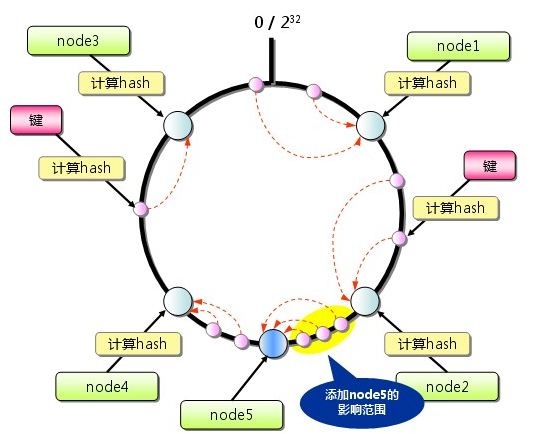
從上圖的狀態中新增一臺memcached 伺服器。餘數分散式演算法由於儲存鍵的伺服器會發生巨大變化,而影響快取的命中率,但Consistent Hashing中,只有在continuum 上增加伺服器的地點逆時針方向的第一臺伺服器上的鍵會受到影響
Consistent hashing 的基本思想就是將物件和 cache 都對映到同一個 hash 數值空間中,並且使用相同的 hash 演算法。
現在 cache 和物件都已經通過同一個 hash 演算法對映到 hash 數值空間中了,接下來要考慮的就是如何將物件對映到 cache 上面了。
在這個環形空間中,如果沿著順時針方向從物件的 key 值出發,直到遇見一個 cache ,那麼就將該物件儲存在這個 cache 上,因為物件和 cache 的 hash 值是固定的,因此這個 cache 必然是唯一和確定的。這樣不就找到了物件和 cache 的對映方法了嗎?
Consistent Hashing:新增伺服器
因此,Consistent Hashing 最大限度地抑制了鍵的重新分佈。而且,有的Consistent Hashing 的實現方法還採用了虛擬節點的思想。使用一般的hash函式的話,伺服器的對映地點的分佈非常不均勻。因此,使用虛擬節點的思想,為每個物理節點(伺服器)在continuum上分配100~200 個點。這樣就能抑制分佈不均勻,最大限度地減小伺服器增減時的快取重新分佈。
儲存命令
<command name> <key> <flags> <exptime> <bytes>\r\n
- <command name> 是set, add,或者repalce
- <key> 是接下來的客戶端所要求儲存的資料的鍵值
- <flags> 是在取回內容時,與資料和傳送塊一同儲存伺服器上的任意16位無符號整形(用十進位制來書寫)。客戶端可以用它作為“位域”來儲存一些特定的資訊;它對伺服器是不透明的。
- <exptime> 是終止時間。如果為0,該項永不過期(雖然它可能被刪除,以便為其他快取專案騰出位置)。如果非0(Unix 時間戳或當前時刻的秒偏移),到達終止時間後,客戶端無法再獲得這項內容。
- <bytes> 是隨後的資料區塊的位元組長度,不包括用於分野的“\r\n”。它可以是0(這時後面跟隨一個空的資料區塊)。
- <data block> 是大段的8位資料,其長度由前面的命令列中的<bytes>指定。
• set 意思是“儲存此資料”
• add 意思是“儲存此資料,只在伺服器*未*保留此鍵值的資料時”
• replace 意思是“儲存此資料,只在伺服器*曾*保留此鍵值的資料時”
傳送命令列和資料區塊以後,客戶端等待回覆,可能的回覆如下:
- "STORED\r\n"表明成功.
- "NOT_STORED\r\n"表明資料沒有被儲存,但不是因為發生錯誤。這通常意味著add或replace 命令的條件不成立,或者,專案已經位列刪除佇列(參考後文的“delete”命令)。
取回命令
get <key>*\r\n
- <key>* 表示一個或多個鍵值,由空格隔開的字串這行命令以後,客戶端的等待0個或多個專案,每項都會收到一行文字,然後跟著資料區塊。所有專案傳送完畢後,伺服器傳送以下字串:"END\r\n"來指示迴應完畢,伺服器用以下形式傳送每項內容:
VALUE <key> <flags> <bytes>\r\n
<data block>\r\n
- <key> 是所傳送的鍵名
- <flags> 是儲存命令所設定的記號
- <bytes> 是隨後資料塊的長度,*不包括* 它的界定符“\r\n”
- <data block> 是傳送的資料
如果在取回請求中傳送了一些鍵名,而伺服器沒有送回專案列表,這意味著伺服器沒這些鍵名(可能因為它們從未被儲存,或者為給其他內容騰出空間而被刪除,或者到期,或者被已客戶端刪除)。
刪除
delete <key> <time>\r\n
- <key> 是客戶端希望伺服器刪除的內容的鍵名
- <time> 是一個單位為秒的時間(或代表直到某一刻的Unix時間),在該時間內伺服器會拒絕對於此鍵名的“add”和“replace”命令。此時內容被放入delete佇列,無法再通過“get”得到該內容,也無法是用“add”和“replace”命令(但是“set”命令可用)。直到指定時間,這些內容被最終從伺服器的記憶體中徹底清除。<time>引數是可選的,預設為0(表示內容會立刻清除,並且隨後的儲存命令均可用)。
此命令有一行迴應:- "DELETED\r\n"表示執行成功
- "NOT_FOUND\r\n"表示沒有找到這項內容
增加/減少
命令“incr”和“decr”被用來修改資料,當一些內容需要替換、增加或減少時。這些資料必須是十進位制的32位無符號整新。如果不是,則當作0 來處理。修改的內容必須存在,當使用“incr”/“decr”命令修改不存在的內容時,不會被當作0處理,而是操作失敗。
客戶端傳送命令列:
incr <key> <value>\r\n或decr <key> <value>\r\n
- <key> 是客戶端希望修改的內容的建名
- <value> 是客戶端要增加/減少的總數。
回覆為以下集中情形:
- "NOT_FOUND\r\n"指示該項內容的值,不存在。
- <value>\r\n ,<value>是增加/減少。
注意"decr"命令發生下溢:如果客戶端嘗試減少的結果小於0 時,結果會是0。"incr" 命令不會發生溢位。
狀態
命令"stats" 被用於查詢伺服器的執行狀態和其他內部資料。有兩種格式。不帶引數的:
stats\r\n
這會在隨後輸出各項狀態、設定值和文件。另一種格式帶有一些引數:
stats <args>\r\n
通過<args>,伺服器傳回各種內部資料。因為隨時可能發生變動,本文不提供引數的種類及其傳回資料。
各種狀態
受到無引數的"stats"命令後,伺服器傳送多行內容,如下:
STAT <name> <value>\r\n
伺服器用以下一行來終止這個清單:END\r\n,在每行狀態中,<name> 是狀態的名字,<value>使狀態的資料。以下清單,是所有的狀態名稱,資料型別,和資料代表的含義。
在“型別”一列中,"32u"表示32 位無符號整型,"64u"表示64 位無符號整型,"32u:32u"表示用冒號隔開的兩個32 位無符號整型。
名稱 | 型別 | 含義 |
pid | 32u | 伺服器程序ID |
uptime | 32u | 伺服器執行時間,單位秒 |
time | 32u | 伺服器當前的UNIX時間 |
version | string | 伺服器的版本號 |
rusage_user | 32u | 該程序累計的使用者時間(秒:微妙) |
rusage_system | 32u | 該程序累計的系統時間(秒:微妙) |
curr_items | 32u | 伺服器當前儲存的內容數量 |
total_items | 32u | 伺服器啟動以來儲存過的內容總數 |
bytes | 64u | 伺服器當前儲存內容所佔用的位元組數 |
curr_connections | 32u | 連線數 |
total_connections | 32u | 伺服器執行以來接受的連線總數 |
connection_structures | 32u | 伺服器分配的連線結構的數量 |
cmd_get | 32u | 取回請求總數 |
cmd_set | 32u | 儲存請求總數 |
get_hits | 32u | 請求成功的總次數 |
get_misses | 32u | 請求失敗的總次數 |
bytes_read | 64u | 伺服器從網路讀取到的總位元組數 |
bytes_written | 64u | 伺服器向網路傳送的總位元組數 |
limit_maxbytes | 32u | 伺服器在儲存時被允許使用的位元組總數 |
如果不想每次通過輸入stats來檢視memcache狀態,可以通過echo "stats" |nc ip port 來檢視,例如:echo "stats" | nc 127.0.0.1 9023。