
常見資料多副本一致性方案
在分散式系統中,選擇採用多副本方案,就要面對資料一致性問題;資料一致性主要是指在多副本的情況下,如何保證各個副本間資料的一致性。資料的一致性是一個很難解決的問題,受CAP【C:一致性,A:可用性:,P:分割槽容忍性】原則的限制,同時只能滿足其中兩項指標。對於一致性我們需要根據不同的業務場景進行選擇。
以資料為中心的一致性模型
1.嚴格一致性(strict consistency):對於資料項x的任何讀操作將返回最近一次對x進行寫操作的結果所對應的值。嚴格一致性是限制性最強的模型,但是在分散式系統中實現這種模型代價太大,所以在實際系統中運用有限。
2.順序一致性:任何執行結果都是相同的,就好像所有程序對資料儲存的讀、寫操作是按某種序列順序執行的,並且每個程序的操作按照程式所制定的順序出現在這個序列中。也就是說,任何讀、寫操作的交叉都是可接受的,但是所有程序都看到相同的操作交叉。順序一致性由Lamport(1979)在解決多處理器系統的共享儲存器時首次提出的。
3.因果一致性:所有程序必須以相同的順序看到具有潛在因果關係的寫操作。不同機器上的程序可以以不同的順序看到併發的寫操作(Hutto和Ahamad 1990)。
假設P1和P2是有因果關係的兩個程序,例如P2的寫操作信賴於P1的寫操作,那麼P1和P2對x的修改順序,在P3和P4看來一定是一樣的。但如果P1和P2沒有關係,那麼P1和P2對x的修改順序,在P3和P4看來可以是不一樣的。
以客戶為中心的一致性模型
1.最終一致性:最終一致性指的是在一段時間內沒有資料更新操作的話,那麼所有的副本將逐漸成為一致的。例如OpenStack Swift就是採用這種模型。以一次寫多次讀的情況下,這種模型可以工作得比較好。
2.單調讀:如果一個程序讀取資料項x的值,那麼該程序對x執行的任何後續讀操作將總是得到第一次讀取的那個值或更新的值
3.單調寫:一個程序對資料x執行的寫操作必須在該程序對x執行任何後續寫操作之前完成。
4.寫後讀:一個程序對資料x執行一次寫操作的結果總是會被該程序對x執行的後續讀操作看見。
5.讀後寫:同一個程序對資料項x執行的讀操作之後的寫操作,保證發生在與x讀取值相同或比之更新的值上。
多副本情況下的讀寫一致性:
- 一主多從:只讀副本保證強一致性
- 對等副本:W+R>N保證繪畫一致性
- 提高可靠性: 增加副本數、提高副本修復速度
在實現資料一致性的方案中主要有以下幾種:
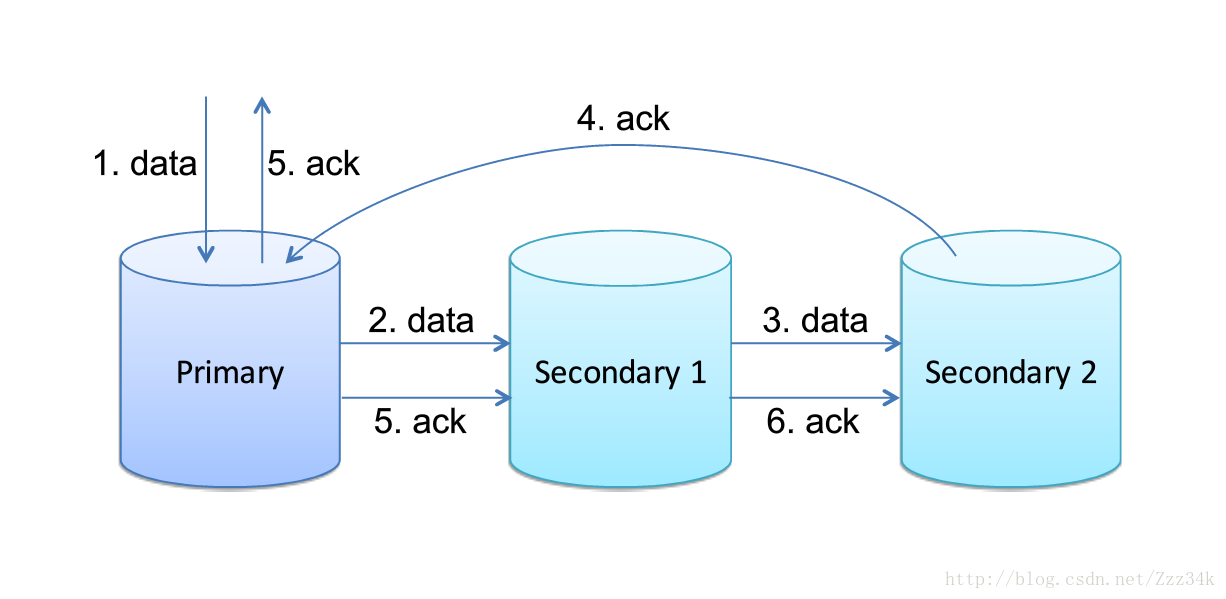
採用鏈式請求,只有所有的副本都儲存成功,才能返回成功;
優點:能夠保證資料的強一致性
缺點:效能較差,整個更新過程依賴於所有節點的成功
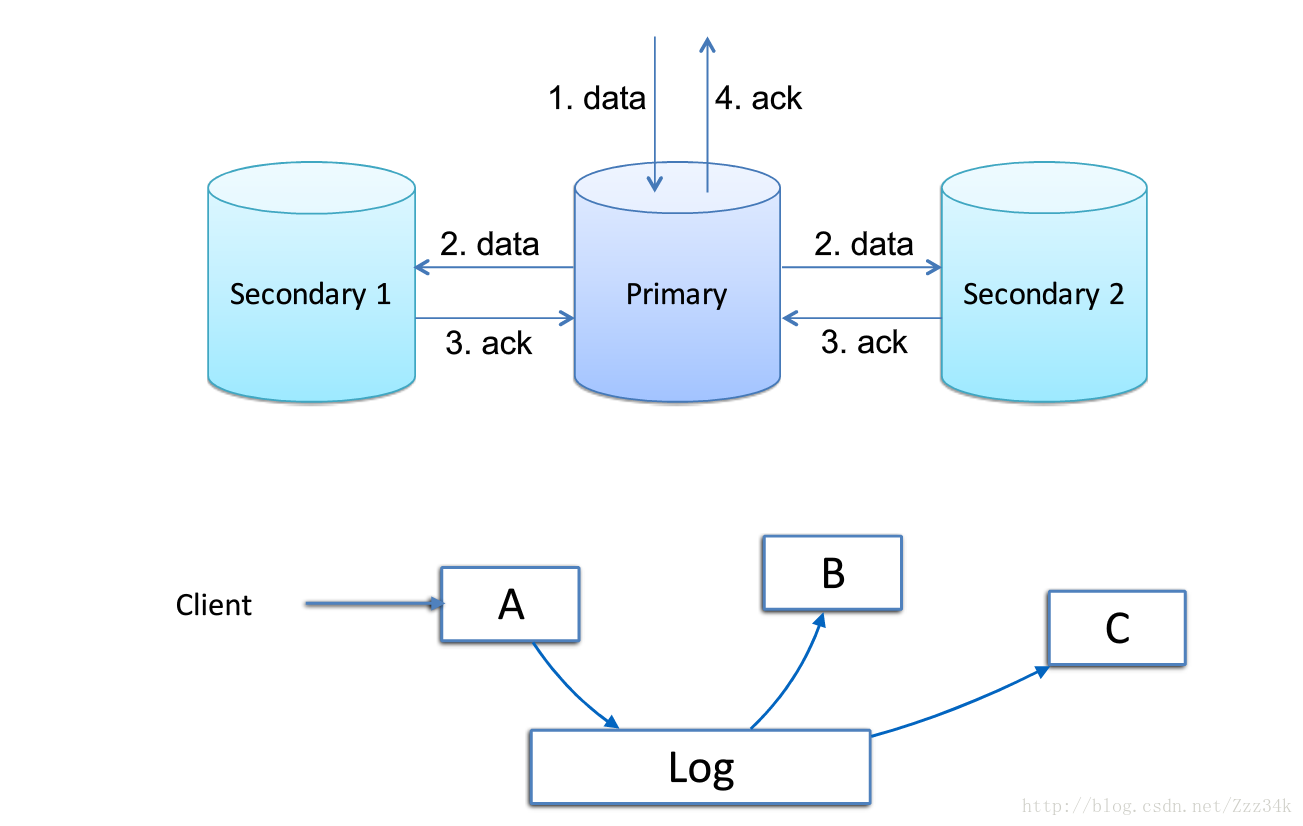
採用多扇出的方式,主節點儲存成功,然後同時向多個副本傳送資料;
優點:效能較好,時間取決於主節點的儲存時間和副本中最長的儲存時間
確定:嚴重依賴主節點,高扇出,資料量大時對網路有壓力
所以可以採用下圖的方案,採用資料庫採用的方式,先寫日誌再執行同步操作
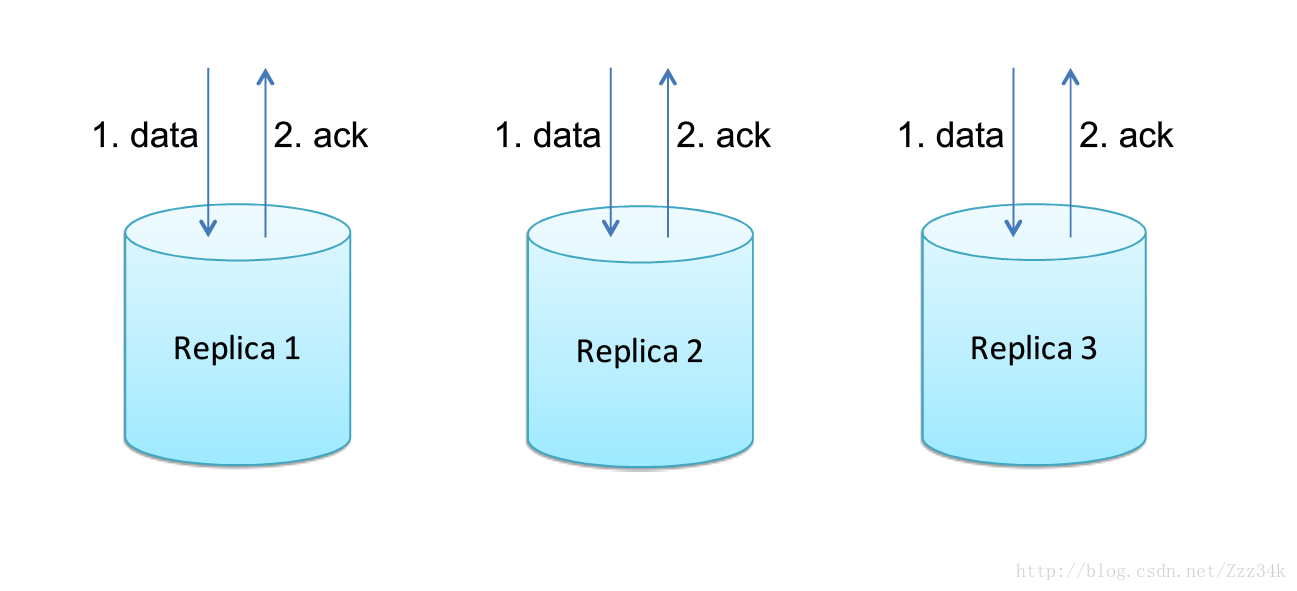
由client負責向各個服務並行傳送資料;
優點:速度最快,受限於最慢節點;可以採用變通的方案(如果節點中超過一定的閥值的數量已經成功,就認為成功)
缺點:client端扇出很大,如果資料量不是很大,這確實是不錯的方案
實際使用過程中每種方案都是可以變通的,根據實際業務場景以及對資料一致性的要求來確定自己的方案。
在分散式系統的設計和開發中,工程師們有一個通病,起碼大多數人都會犯的錯,就是過度設計;在資料一致性方案中,不同的需求對方案的影響很大,過度設計和開發會造成資源的浪費。