
CDH+Storm+Spark (on yarm 模式)叢集部署
一、CDH部署環境:主機5臺,普通使用者stream免密; 本地yum源已配置,
1、環境準備
防火牆、selinux的狀態disable、root免密、控制代碼數(每個主機上能開啟的檔案數)、/etc/hosts--分發(ansible工具批量分發);
2、做一個CM的yum源:
① 裝http的rpm包,yum -install http(開啟80埠)
② CM和CDH包放在war.wwwhtml/
③ yum -install mysql-server安裝mysql;單機版
④ 建庫;cm,am,rm
⑤ 下載jdbc驅動,建軟連結,連結到usr/shell/java/mysql-connector-java.jar
⑥ JDK(CM的yum有):yum -install oracle--7個
⑦ 安裝CM(有7個rpm):yum -install cloder-manager-server--1個
⑧ 資料庫初始化:mysql的指令,不需要進入mysql命令列;CDH的命令;
⑨ CMS啟動,7180埠開啟網頁;
3、CM註冊
安裝agent,10臺一起裝(預設,同時安裝的個數):10-20分鐘
② 安裝CDH包:繼續按鈕:30分左右;
③ 分角色:
4、ansible的安裝:
yum install epel-release
yum install ansible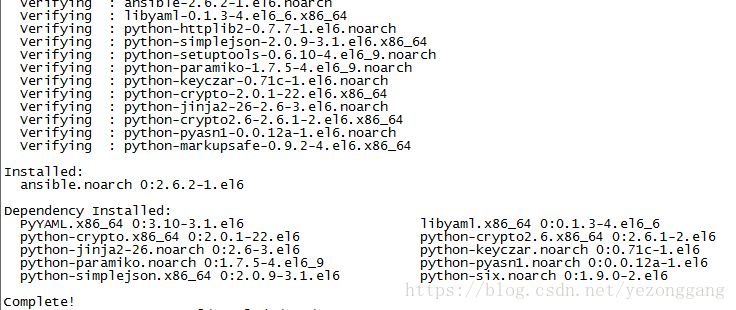
# 檢查主機連線 # ansible test -m ping # 執行遠端命令 # ansible all -m command -a 'uptime' # 執行主控端指令碼 # ansible all -m script -a '/etc/ansible/script/test.sh' # 執行遠端主機的指令碼 # ansible all -m shell -a 'ps aux|grep zabbix' # 類似shell # ansible all -m raw -a "ps aux|grep zabbix|awk '{print \$2}'" # 建立軟連結 # ansible all -m file -a "src=/etc/resolv.conf dest=/tmp/resolv.conf state=link" # 刪除軟連結 # ansible all -m file -a "path=/tmp/resolv.conf state=absent" # 複製檔案到遠端伺服器 # ansible all -m copy -a "src=/etc/ansible/ansible.cfg dest=/tmp/ansible.cfg owner=root group=root mode=0644" # 指定主機 #ansible -i /etc/ansible/hosts all -m copy -a "src=test.conf dest=/etc/test.conf owner=root group=root mode=0644"
其中,第二個引數為使用者組,在/etc/ansible/hosts中有新增各個組;
ansible -stream -m command -a 'mkdir /home/stream/zk' 為在stream的home下批量新建使用者;
ansible -stream -m copy -a 'src=/home/stream/test.sh dest=/home/stream/' 複製本地的test.sh檔案到其他主機上
二、storm部署
1、jdk安裝及環境變數配置,略
2、zk叢集部署,略
3、storm檔案的分發和叢集部署,略
storm的配置檔案修改如下:
#配置zk的地址和埠和storm存放在zookeeper裡目錄 storm.zookeeper.server: - “192.168.159.145” - “192.168.159.144” - “192.168.159.143” storm.zookeeper.port: 21810 storm.zookeeper.root: /storm_new10 #storm主節點的地址 web頁面的埠 nimbus.host: “192.168.159.145” ui.port: 8989 #每個worker使用的記憶體 worker.heap.memory.mb: 512 storm.local.dir: "/home/zyzx/apache-storm-0.9.5/data" #配置工作節點上的程序埠。你配置一個埠,意味著工作節點上啟動一個worker,在實際的生產環境中,我們需要根據實際的物理配置以及每個節點上的負載情況來配置這個埠的數量。在這裡每個節點我象徵性的配置5個埠。 supervisor.slots.ports: - 6700 - 6701 - 6702 - 6703 - 6700 nimbus.thrift.max_buffer_size: 204876 worker.childopts: “-Xmx1024m” 啟動:nohup storm niumbus & nohup storm suprivisor &
三、spark部署
目前Apache Spark支援三種分散式部署方式,分別是standalone、spark on mesos和 spark on YARN,其中,第一種類似於MapReduce 1.0所採用的模式,內部實現了容錯性和資源管理,後兩種則是未來發展的趨勢,部分容錯性和資源管理交由統一的資源管理系統完成:讓Spark執行在一個通用的資源管理系統之上,這樣可以與其他計算框架,比如MapReduce,公用一個叢集資源,最大的好處是降低運維成本和提高資源利用率(資源按需分配);
Standalone模式
即獨立模式,自帶完整的服務,可單獨部署到一個叢集中,無需依賴任何其他資源管理系統。從一定程度上說,該模式是其他兩種的基礎。借鑑Spark開發模式,我們可以得到一種開發新型計算框架的一般思路:先設計出它的standalone模式,為了快速開發,起初不需要考慮服務(比如master/slave)的容錯性,之後再開發相應的wrapper,將stanlone模式下的服務原封不動的部署到資源管理系統yarn或者mesos上,由資源管理系統負責服務本身的容錯。目前Spark在standalone模式下是沒有任何單點故障問題的,這是藉助zookeeper實現的,思想類似於Hbase master單點故障解決方案。將Spark standalone與MapReduce比較,會發現它們兩個在架構上是完全一致的:
1) 都是由master/slaves服務組成的,且起初master均存在單點故障,後來均通過zookeeper解決(Apache MRv1的JobTracker仍存在單點問題,但CDH版本得到了解決);
2) 各個節點上的資源被抽象成粗粒度的slot,有多少slot就能同時執行多少task。不同的是,MapReduce將slot分為map slot和reduce slot,它們分別只能供Map Task和Reduce Task使用,而不能共享,這是MapReduce資源利率低效的原因之一,而Spark則更優化一些,它不區分slot型別,只有一種slot,可以供各種型別的Task使用,這種方式可以提高資源利用率,但是不夠靈活,不能為不同型別的Task定製slot資源。總之,這兩種方式各有優缺點。
Spark On Mesos模式
這是很多公司採用的模式,官方推薦這種模式(當然,原因之一是血緣關係)。正是由於Spark開發之初就考慮到支援Mesos,因此,目前而言,Spark執行在Mesos上會比執行在YARN上更加靈活,更加自然。目前在Spark On Mesos環境中,使用者可選擇兩種排程模式之一執行自己的應用程式(可參考Andrew Xia的“Mesos Scheduling Mode on Spark”):
1) 粗粒度模式(Coarse-grained Mode):每個應用程式的執行環境由一個Dirver和若干個Executor組成,其中,每個Executor佔用若干資源,內部可執行多個Task(對應多少個“slot”)。應用程式的各個任務正式執行之前,需要將執行環境中的資源全部申請好,且執行過程中要一直佔用這些資源,即使不用,最後程式執行結束後,回收這些資源。舉個例子,比如你提交應用程式時,指定使用5個executor執行你的應用程式,每個executor佔用5GB記憶體和5個CPU,每個executor內部設定了5個slot,則Mesos需要先為executor分配資源並啟動它們,之後開始排程任務。另外,在程式執行過程中,mesos的master和slave並不知道executor內部各個task的執行情況,executor直接將任務狀態通過內部的通訊機制彙報給Driver,從一定程度上可以認為,每個應用程式利用mesos搭建了一個虛擬叢集自己使用。
2) 細粒度模式(Fine-grained Mode):鑑於粗粒度模式會造成大量資源浪費,Spark On Mesos還提供了另外一種排程模式:細粒度模式,這種模式類似於現在的雲端計算,思想是按需分配。與粗粒度模式一樣,應用程式啟動時,先會啟動executor,但每個executor佔用資源僅僅是自己執行所需的資源,不需要考慮將來要執行的任務,之後,mesos會為每個executor動態分配資源,每分配一些,便可以執行一個新任務,單個Task執行完之後可以馬上釋放對應的資源。每個Task會彙報狀態給Mesos slave和Mesos Master,便於更加細粒度管理和容錯,這種排程模式類似於MapReduce排程模式,每個Task完全獨立,優點是便於資源控制和隔離,但缺點也很明顯,短作業執行延遲大。
Spark On YARN模式
這是一種很有前景的部署模式。但限於YARN自身的發展,目前僅支援粗粒度模式(Coarse-grained Mode)。這是由於YARN上的Container資源是不可以動態伸縮的,一旦Container啟動之後,可使用的資源不能再發生變化,不過這個已經在YARN計劃中了。
spark on yarn 的支援兩種模式:
1) yarn-cluster:適用於生產環境;
2) yarn-client:適用於互動、除錯,希望立即看到app的輸出
yarn-cluster和yarn-client的區別在於yarn appMaster,每個yarn app例項有一個appMaster程序,是為app啟動的第一個container;負責從ResourceManager請求資源,獲取到資源後,告訴NodeManager為其啟動container。yarn-cluster和yarn-client模式內部實現還是有很大的區別。如果你需要用於生產環境,那麼請選擇yarn-cluster;而如果你僅僅是Debug程式,可以選擇yarn-client。
這三種分散式部署方式各有利弊,通常需要根據實際情況決定採用哪種方案。進行方案選擇時,往往要考慮公司的技術路線(採用Hadoop生態系統還是其他生態系統)、相關技術人才儲備等。上面涉及到Spark的許多部署模式,究竟哪種模式好這個很難說,需要根據你的需求,如果你只是測試Spark Application,你可以選擇local模式。而如果你資料量不是很多,Standalone 是個不錯的選擇。當你需要統一管理叢集資源(Hadoop、Spark等),那麼你可以選擇Yarn或者mesos,但是這樣維護成本就會變高。
· 從對比上看,mesos似乎是Spark更好的選擇,也是被官方推薦的
· 但如果你同時執行hadoop和Spark,從相容性上考慮,Yarn是更好的選擇。 · 如果你不僅運行了hadoop,spark。還在資源管理上運行了docker,Mesos更加通用。
· Standalone對於小規模計算叢集更適合!
四、hadoop分佈模式部署
spark的資料需要儲存在hdfs上,而且spark的on yarn是最好的使用方式,因此在部署spark之前需要部署hadoop叢集,含有hdfs和yarn元件;
Hadoop目錄結構
bin:Hadoop最基本的管理指令碼和使用指令碼的目錄,這些指令碼是sbin目錄下管理
指令碼的基礎實現,使用者可以直接使用這些指令碼管理和使用Hadoopetc:Hadoop配置檔案所在的目錄,包括core-site,xml、hdfs-site.xml、mapredsite.xml等include:對外提供的程式設計庫標頭檔案(具體動態庫和靜態庫在lib目錄中),這些頭
檔案均是用C++定義的,通常用於C++程式訪問HDFS或者編寫MapReduce程式lib:該目錄包含了Hadoop對外提供的程式設計動態庫和靜態庫,與include目錄中的
標頭檔案結合使用libexec:各個服務對用的shell配置檔案所在的目錄,可用於配置日誌輸出、啟動
引數(比如JVM引數)等基本資訊sbin:Hadoop管理指令碼所在的目錄,主要包含HDFS和YARN中各類服務的啟動/關
閉指令碼share:Hadoop各個模組編譯後的jar包所在的目錄

Hadoop的配置檔案
配置檔案介紹,在Hadoop中,Common、HDFS和MapReduce各有對應的配置檔案,用於儲存對應模組中可配置的引數。這些配置檔案均為XML格式且由兩部分構成:系統預設配置檔案和管理員自定義配置檔案。其中,系統預設配置檔案分別是core-default.xml、hdfs-default.xml和mapred-default.xml,它們包含了所有可配置屬性的預設值。而管理員自定義配置檔案分別是core-site.xml、hdfs-site.xml和mapred-site.xml。它們由管理員設定,主要用於定義一些新的配置屬性或者覆蓋系統預設配置檔案中的預設值。通常這些配置一旦確定,便不能被修改(如果想修改,需重新啟動Hadoop)。需要注意的是,core-default.xml和core-site.xml屬於公共基礎庫的配置檔案,預設情況下,Hadoop總會優先載入它們。
預設配置檔案:core-default.xml、hdfs-default.xml、mapred-default.xml、yarn-default.xml
特定配置檔案:core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml特定的配置項覆蓋預設中相同的配置項
預設檔案是隻讀的,可以從classpath中的jar檔案中直接獲取該檔案,在特定大量的變數,通過定義和修改可以滿足控制Hadoop配置的需要;
| 配置檔案 | 描述 |
| core-default.xml | 預設的核心Hadoop屬性配置檔案,該配置檔案在hadoop-common-2.7.3.jar中 |
| hdfs-default.xml | 預設的HDFS屬性配置檔案,該配置檔案在hadooop-hdfs-2.7.3.jar中 |
| mapred-default.xml | 預設的MapReduce屬性配置檔案,該配置檔案在hadoop-mapreduce-2.7.3.jar中 |
| yarn-default.xml | 預設的YARN屬性配置檔案,該配置檔案在hadoop-yarn-common-2.7.3.jar中 |

Hadoop叢集特定配置檔案:
| 配置檔案 | 描述 |
| core-site.xml | 特定的通用Hadoop屬性配置檔案,該配置檔案會覆蓋core-default.xml中相同配置項 |
| hdfs-site.xml | 特定的通用HDFS屬性配置檔案,該配置檔案會覆蓋hdfs-default.xml中相同配置項 |
| mapred-site.xml | 特定的通用MapReduce屬性配置檔案,該配置檔案會覆蓋mapred-default.xml中相同配置項 |
| yarn-site.xml | 特定的通用YARN屬性配置檔案,該配置檔案會覆蓋yarn-default.xml中相同配置項 |
配置Hadoop守護程序
| 指令碼 | 描述 |
| hadoop-ev.sh | 設定Java主目錄 |
| yarn-env.sh | 設定不同日誌檔案位置 |
| mapred-env.sh | 設定用於各種守護程序的JVM選項 |
守護程序配置變數:
| 守護程序 | 環境變數 |
| 名稱節點 | HADOOP_NAMEN_OPTS |
| 資料節點 | HADOOP_DATANODE_OPTS |
| 輔助名稱節點 | HADOOP_SECONDARYNAMENODE_OPTS |
| 資源管理器 | YARN_RESOURCEMANAGER_OPTS |
| 節點管理器 | YARN_NODEMANAGER_OPTS |
etc/hadoop/hadoop-env.sh
該指令碼是hadoop所有元件啟動時都需要讀取指令碼,設定hadoop的環境變數,設定JAVA_HOME和HADOOP_HOME及其使用者等;
etc/hadoop/core-site.xml
| 屬性 | 描述 |
| hadoop-tmp-dir | 其他所有領書目錄的根目錄,預設值:/tmp/hadoop-${user.name} |
| fs.defaultFS | 在沒有特殊配置的情況下,HDFS客戶端使用的預設路徑字首由該屬性配置 |
| io.file.buffer-size | 該屬性指定了檔案流的緩衝大小,這個換錯那個的大小應該是硬體頁面大小的整數倍,它決定了資料讀取和寫入操作過程中緩衝了多少資料,預設值4096 |
| io.byte.per.checksum | Hadoop徐彤在資料寫入時會計算校驗和,並在讀取資料是進行校驗,這個過程對使用者透明。該引數定義了多大的資料量進行一次校驗和計算,預設值512位元組 |
| io.compression.codecs | 一個由逗號分隔的可用壓縮編碼類的列表,用於壓縮\解壓縮資料 |
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.1.100:900</value>
<description>192.168.1.100為伺服器IP地址,其實也可以使用主機名</description>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
<description>該屬性值單位為KB,131072KB即為預設的64M</description>
</property>
</configuration>etc/hadoop/hdfs-site.xml
hdfs-*.xml檔案集用於配置HDFS系統的執行時屬性和各個資料節點上檔案的物理儲存相關的屬性
配置nameNode
| 引數 | 屬性值 | 解釋 |
| dfs.namenode.name.dir | 在本地檔案系統所在的NameNode的儲存空間和持續化處理日誌 | 如果這是一個以逗號分隔的目錄列表,然 後將名稱表被複制的所有目錄,以備不時 需。 |
| dfs.namenode.hosts/ dfs.namenode.hosts.exclude |
Datanodes permitted/excluded列表 | 如有必要,可以使用這些檔案來控制允許 資料節點的列表 |
| dfs.blocksize | 268435456 | 大型的檔案系統HDFS塊大小為256MB |
| dfs.namenode.handler.count | 100 | 設定更多的namenode執行緒,處理從 datanode發出的大量RPC請求 |
範例如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>分片數量,偽分散式將其配置成1即可</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/namenode</value>
<description>名稱空間和事務在本地檔案系統永久儲存的路徑</description>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>datanode1, datanode2</value>
<description>datanode1, datanode2分別對應DataNode所在伺服器主機名</description>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
<description>大檔案系統HDFS塊大小為256M,預設值為64M</description>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
<description>更多的NameNode伺服器執行緒處理來自DataNodes的RPCS</description>
</property>
</configuration>配置nameNode
| 引數 | 屬性值 | 解釋 |
| dfs.datanode.data.dir | 逗號分隔的一個DataNode上,它應該儲存它的塊的本地檔案系統的路徑列表 | 如果這是一個以逗號分隔的目錄列表,那麼資料將被儲存在所有命名的目錄,通常在不同的裝置。 |
<configuration>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/datanode</value>
<description>DataNode在本地檔案系統中存放塊的路徑</description>
</property>
</configuration>etc/hadoop/yarn-site.xml
- 配置ResourceManager
| 引數 | 屬性值 | 解釋 |
| yarn.resourcemanager.address | 客戶端對ResourceManager主機通過 host:port 提交作業 | host:port |
| yarn.resourcemanager.scheduler.address | ApplicationMasters 通過ResourceManager主機訪問host:port跟蹤排程程式獲資源 | host:port |
| yarn.resourcemanager.resource-tracker.address | NodeManagers通過ResourceManager主機訪問host:port | host:port |
| yarn.resourcemanager.admin.address | 管理命令通過ResourceManager主機訪問host:port | host:port |
| yarn.resourcemanager.webapp.address | ResourceManager web頁面host:port. | host:port |
| yarn.resourcemanager.scheduler.class | ResourceManager 排程類(Scheduler class) | CapacityScheduler(推薦),FairScheduler(也推薦),orFifoScheduler |
| yarn.scheduler.minimum-allocation-mb | 每個容器記憶體最低限額分配到的資源管理器要求 | 以MB為單位 |
| yarn.scheduler.maximum-allocation-mb | 資源管理器分配給每個容器的記憶體最大限制 | 以MB為單位 |
| yarn.resourcemanager.nodes.include-path/ yarn.resourcemanager.nodes.exclude-path |
NodeManagers的permitted/excluded列表 | 如有必要,可使用這些檔案來控制允許NodeManagers列表 |
範例如下:
<configuration>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.1.100:8081</value>
<description>IP地址192.168.1.100也可替換為主機名</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.1.100:8082</value>
<description>IP地址192.168.1.100也可替換為主機名</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.1.100:8083</value>
<description>IP地址192.168.1.100也可替換為主機名</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.1.100:8084</value>
<description>IP地址192.168.1.100也可替換為主機名</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.1.100:8085</value>
<description>IP地址192.168.1.100也可替換為主機名</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>FairScheduler</value>
<description>常用類:CapacityScheduler、FairScheduler、orFifoScheduler</description>
</property>
<property>
<name>yarn.scheduler.minimum</name>
<value>100</value>
<description>單位:MB</description>
</property>
<property>
<name>yarn.scheduler.maximum</name>
<value>256</value>
<description>單位:MB</description>
</property>
<property>
<name>yarn.resourcemanager.nodes.include-path</name>
<value>nodeManager1, nodeManager2</value>
<description>nodeManager1, nodeManager2分別對應伺服器主機名</description>
</property>
</configuration>- 配置NodeManager
| 引數 | 屬性值 | 解釋 |
| yarn.nodemanager.resource.memory-mb | givenNodeManager即資源的可用實體記憶體,以MB為單位 | 定義在節點管理器總的可用資源,以提供給執行容器 |
| yarn.nodemanager.vmem-pmem-ratio | 最大比率為一些任務的虛擬記憶體使用量可能會超過實體記憶體率 | 每個任務的虛擬記憶體的使用可以通過這個比例超過了實體記憶體的限制。虛擬記憶體的使用上的節點管理器任務的總量可以通過這個比率超過其實體記憶體的使用 |
| yarn.nodemanager.local-dirs | 資料寫入本地檔案系統路徑的列表用逗號分隔 | 多條儲存路徑可以提高磁碟的讀寫速度 |
| yarn.nodemanager.log-dirs | 本地檔案系統日誌路徑的列表逗號分隔 | 多條儲存路徑可以提高磁碟的讀寫速度 |
| yarn.nodemanager.log.retain-seconds | 10800 | 如果日誌聚合被禁用。預設的時間(以秒為單位)保留在節點管理器只適用日誌檔案 |
| yarn.nodemanager.remote-app-log-dir | logs | HDFS目錄下的應用程式日誌移動應用上完成。需要設定相應的許可權。僅適用日誌聚合功能 |
| yarn.nodemanager.remote-app-log-dir-suffix | logs | 字尾追加到遠端日誌目錄。日誌將被彙總到yarn.nodemanager.remoteapplogdir/{user}/${thisParam} 僅適用日誌聚合功能。 |
<configuration>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>256</value>
<description>單位為MB</description>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>90</value>
<description>百分比</description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/usr/local/hadoop/tmp/nodemanager</value>
<description>列表用逗號分隔</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/usr/local/hadoop/tmp/nodemanager/logs</value>
<description>列表用逗號分隔</description>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
<description>單位為S</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce-shuffle</value>
<description>Shuffle service 需要加以設定的MapReduce的應用程式服務</description>
</property>
</configuration>etc/hadoop/mapred-site.xml
mapred-site.xml是提高Hadoop MapReduce效能的關鍵配置檔案,這個配置檔案保護了與CPU、記憶體、磁碟I/O和網路相關的引數。
- 配置mapreduce
| 引數 | 屬性值 | 解釋 |
| mapreduce.framework.name | yarn | 執行框架設定為 Hadoop YARN. |
| mapreduce.map.memory.mb | 1536 | 對maps更大的資源限制的. |
| mapreduce.map.java.opts | -Xmx2014M | maps中對jvm child設定更大的堆大小 |
| mapreduce.reduce.memory.mb | 3072 | 設定 reduces對於較大的資源限制 |
| mapreduce.reduce.java.opts | -Xmx2560M | reduces對 jvm child設定更大的堆大小 |
| mapreduce.task.io.sort.mb | 512 | 更高的記憶體限制,而對資料進行排序的效率 |
| mapreduce.task.io.sort.factor | 100 | 在檔案排序中更多的流合併為一次 |
| mapreduce.reduce.shuffle.parallelcopies | 50 | 通過reduces從很多的map中讀取較多的平行 副本 |
<configuration>
<property>
<name> mapreduce.framework.name</name>
<value>yarn</value>
<description>執行框架設定為Hadoop YARN</description>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1536</value>
<description>對maps更大的資源限制的</description>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx2014M</value>
<description>maps中對jvm child設定更大的堆大小</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>3072</value>
<description>設定 reduces對於較大的資源限制</description>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx2560M</value>
<description>reduces對 jvm child設定更大的堆大小</description>
</property>
<property>
<name>mapreduce.task.io.sort</name>
<value>512</value>
<description>更高的記憶體限制,而對資料進行排序的效率</description>
</property>
<property>
<name>mapreduce.task.io.sort.factor</name>
<value>100</value>
<description>在檔案排序中更多的流合併為一次</description>
</property>
<property>
<name>mapreduce.reduce.shuffle.parallelcopies</name>
<value>50</value>
<description>通過reduces從很多的map中讀取較多的平行副本</description>
</property>
</configuration>- 配置mapreduce的JobHistory伺服器
| 引數 | 屬性值 | 解釋 |
| maprecude.jobhistory.address | MapReduce JobHistory Server host:port | 預設埠號 10020 |
| mapreduce.jobhistory.webapp.address | MapReduce JobHistory Server Web UIhost:port | 預設埠號 19888 |
| mapreduce.jobhistory.intermediate-done-dir | /mrhistory/tmp | 在歷史檔案被寫入由MapReduce作業 |
| mapreduce.jobhistory.done-dir | /mrhistory/done | 目錄中的歷史檔案是由MR JobHistory Server管理 |
<configuration>
<property>
<name> mapreduce.jobhistory.address</name>
<value>192.168.1.100:10200</value>
<description>IP地址192.168.1.100可替換為主機名</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>192.168.1.100:19888</value>
<description>IP地址192.168.1.100可替換為主機名</description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/usr/local/hadoop/mrhistory/tmp</value>
<description>在歷史檔案被寫入由MapReduce作業</description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/usr/local/hadoop/mrhistory/done</value>
<description>目錄中的歷史檔案是由MR JobHistoryServer管理</description>
</property>
</configuration>