
Solr 全文搜尋服務
Solr
全文搜尋服務
1 Solr介紹
1.1 什麼是solr
Solr 是Apache下的一個頂級開源專案,採用Java開發,它是基於Lucene的全文搜尋伺服器。Solr可以獨立執行在Jetty、Tomcat等這些Servlet容器中。
Solr提供了比Lucene更為豐富的查詢語言,同時實現了可配置、可擴充套件,並對索引、搜尋效能進行了優化。
使用Solr 進行建立索引和搜尋索引的實現方法很簡單,如下:
*建立索引:客戶端(可以是瀏覽器可以是Java程式)用 POST 方法向 Solr 伺服器傳送一個描述 Field 及其內容的 XML 文件,Solr伺服器
*搜尋索引:客戶端(可以是瀏覽器可以是Java程式)用 GET方法向 Solr 伺服器傳送請求,然後對Solr伺服器返回Xml、json等格式的查詢結果進行解析,組織頁面佈局。Solr不提供構建頁面UI的功能,但是Solr提供了一個管理介面,通過管理介面可以查詢Solr的配置和執行情況。
1.2 Solr和Lucene的區別
Lucene是一個開放原始碼的全文檢索引擎工具包,它不是一個完整的全文檢索應用。Lucene僅提供了完整的查詢引擎和索引引擎,目的是為軟體開發人員提供一個簡單易用的工具包,以方便的在目標系統中實現全文檢索的功能,或者以Lucene為基礎構建全文檢索應用。
Solr的目標是打造一款企業級的搜尋引擎系統,它是基於Lucene一個搜尋引擎服務,可以獨立執行,通過Solr可以非常快速的構建企業的搜尋引擎,通過Solr也可以高效的完成站內搜尋功能。
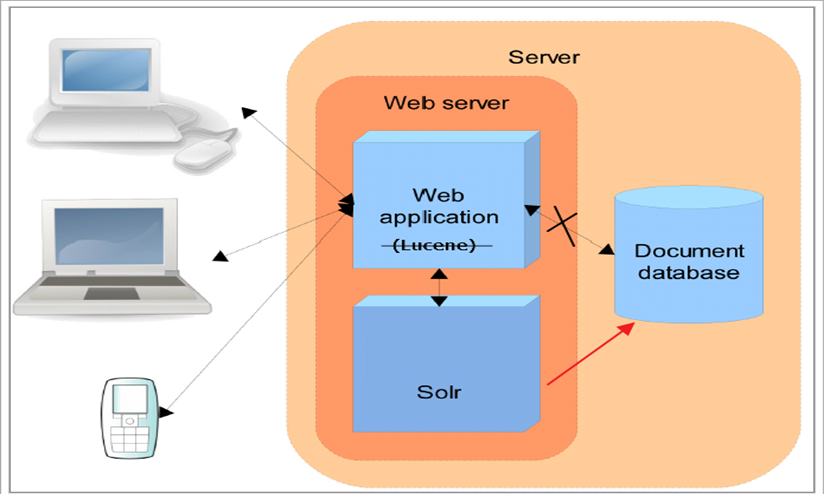
2 Solr安裝配置
2.1 下載solr
Solr和lucene的版本是同步更新的,最新的版本是5.2.1
本課程使用的版本:4.10.3
下載版本:4.10.3
Linux下需要下載lucene-4.10.3.tgz,windows下需要下載lucene-4.10.3.zip。
下載lucene-4.10.3.zip並解壓:
bin:solr的執行指令碼
contrib:solr的一些擴充套件jar包,用於增強solr的功能。
dist:該目錄包含build過程中產生的war和jar檔案,以及相關的依賴檔案。
docs:solr的API文件
example:solr工程的例子目錄:
l example/solr:
該目錄是一個標準的SolrHome,它包含一個預設的SolrCore
l example/multicore:
該目錄包含了在Solr的multicore中設定的多個Core目錄。
l example/webapps:
該目錄中包括一個solr.war,該war可作為solr的執行例項工程。
licenses:solr相關的一些許可資訊
2.2 執行環境
solr 需要執行在一個Servlet容器中,Solr4.10.3要求jdk使用1.7以上,Solr預設提供Jetty(java寫的Servlet容器),本教程使用Tocmat作為Servlet容器,相關環境如下:
l Solr:4.10.3
l Jdk環境:1.7.0_72(solr4.10 不能使用jdk1.7以下)
l Web伺服器(servlet容器):Tomcat 7X
2.3 SolrCore配置
2.3.1 SolrHome和SolrCore
SolrHome是Solr執行的主目錄,該目錄中包括了多個SolrCore目錄。SolrCore目錄中包含了執行Solr例項所有的配置檔案和資料檔案,Solr例項就是SolrCore。
一個SolrHome可以包括多個SolrCore(Solr例項),每個SolrCore提供單獨的搜尋和索引服務。
2.3.2 目錄結構
SolrHome目錄:
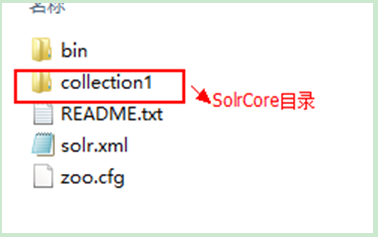
SolrCore目錄:

2.3.3 建立SolrCore
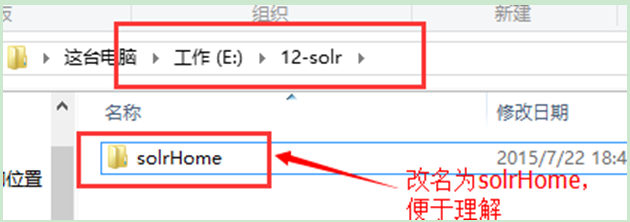
建立SolrCore先要建立SolrHome。在solr解壓包下solr-4.10.3\example\solr資料夾就是一個標準的SolrHome。
l 拷貝solr解壓包下solr-4.10.3\example\solr資料夾。

l 複製該資料夾到本地的一個目錄,把檔名稱改為solrhome。
注:改名不是必須的,只是為了便於理解
l 開啟SolrHome目錄
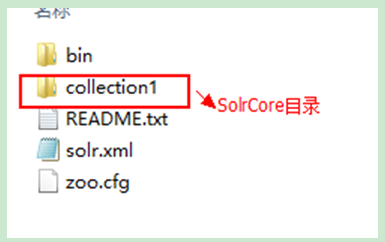
SolrCore建立成功。
2.3.4 配置SolrCore
在conf資料夾下有一個solrconfig.xml。這個檔案是來配置SolrCore例項的相關資訊。如果使用預設配置可以不用做任何修改。它裡面包含了不少標籤,但是我們關注的標籤為:lib標籤、datadir標籤、requestHandler標籤。
2.3.4.1 lib 標籤
在solrconfig.xml中可以載入一些擴充套件的jar,solr.install.dir表示solrCore的目錄位置,需要如下修改:
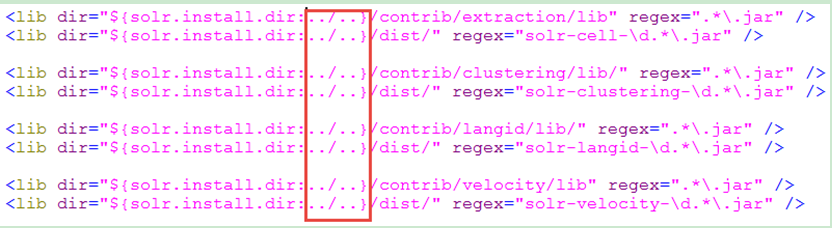
然後將contrib和dist兩個目錄拷貝到E:\12-solr\0505下
2.3.4.2 datadir標籤
每個SolrCore都有自己的索引檔案目錄 ,預設在SolrCore目錄下的data中。

data資料目錄下包括了index索引目錄 和tlog日誌檔案目錄。
如果不想使用預設的目錄也可以通過solrConfig.xml更改索引目錄 ,如下:

2.3.4.3 requestHandler標籤
requestHandler請求處理器,定義了索引和搜尋的訪問方式。
通過/update維護索引,可以完成索引的新增、修改、刪除操作。

提交xml、json資料完成索引維護,索引維護小節詳細介紹。
通過/select搜尋索引。

設定搜尋引數完成搜尋,搜尋引數也可以設定一些預設值,如下:
<requestHandlername="/select" class="solr.SearchHandler">
<!-- 設定預設的引數值,可以在請求地址中修改這些引數-->
<lst name="defaults">
<strname="echoParams">explicit</str>
<intname="rows">10</int><!--顯示數量-->
<str name="wt">json</str><!--顯示格式-->
<strname="df">text</str><!--預設搜尋欄位-->
</lst>
</requestHandler>
2.4 Solr工程部署
由於在專案中用到的web伺服器大多數是用的Tomcat,所以就講solr和Tomcat的整合。
2.4.1 安裝Tomcat
2.4.2 把solr.war部署到Tomcat中
1、 從solr解壓包下的solr-4.10.3\example\webapps目錄中拷貝solr.war
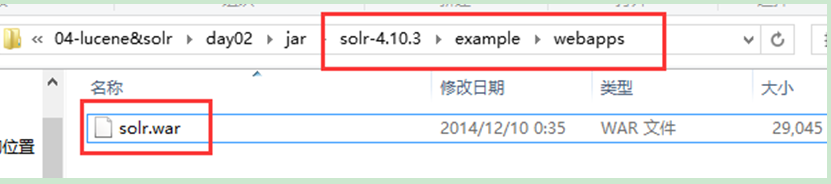
2、 複製到tomcat安裝目錄的webapps資料夾下
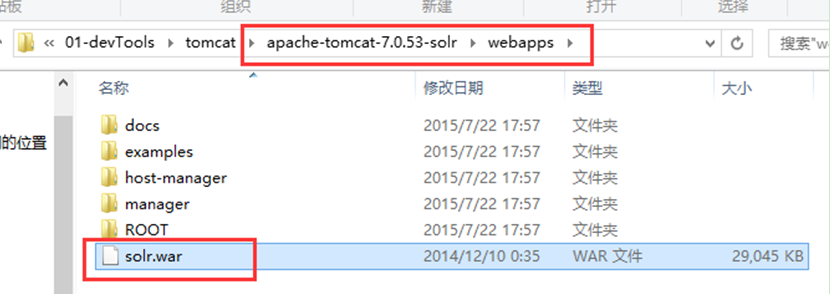
2.4.3 解壓縮solr.war
使用壓縮工具解壓或者啟動tomcat自動解壓。解壓之後刪除solr.war
2.4.4 新增solr服務的擴充套件依賴包(日誌包)
l 把solr解壓包下的solr-4.10.3\example\lib\ext目錄下的所有jar包拷貝。
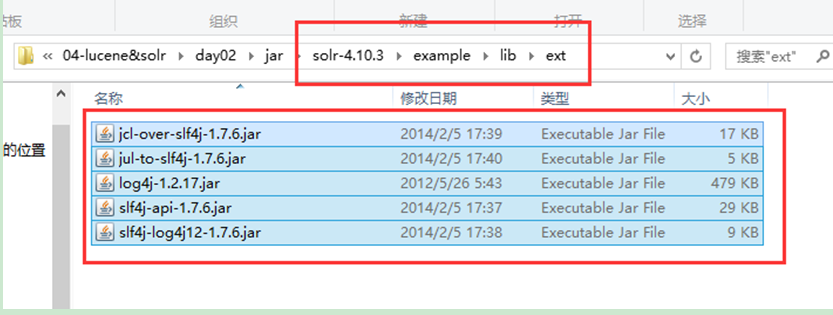
l 複製到解壓縮後的solr工程的WEB-INF\lib目錄
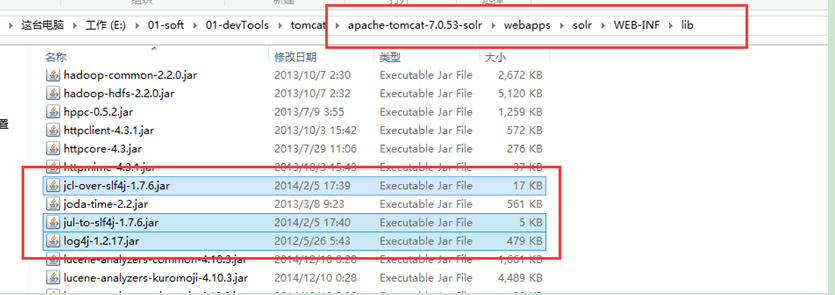
2.4.5 新增log4j.properties
1、 把solr解壓包下solr-4.10.3\example\resources\log4j.properties檔案進行拷貝
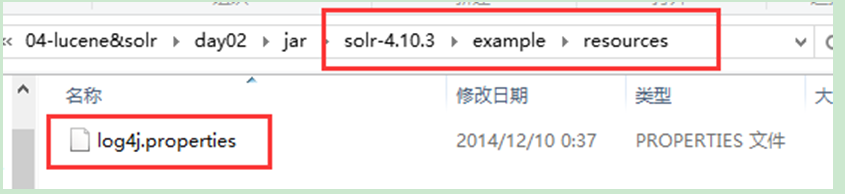
2、 在解壓縮後的solr工程中的WEB-INF目錄中建立classes資料夾

3、 複製log4j.properties檔案到剛建立的classes目錄

2.4.6 在solr應用的web.xml檔案中,載入SolrHome
修改web.xml使用jndi的方式告訴solr伺服器。
Solr/home名稱必須是固定的。

2.4.7 啟動Tomcat進行訪問
出現以下介面則說明solr安裝成功!!!
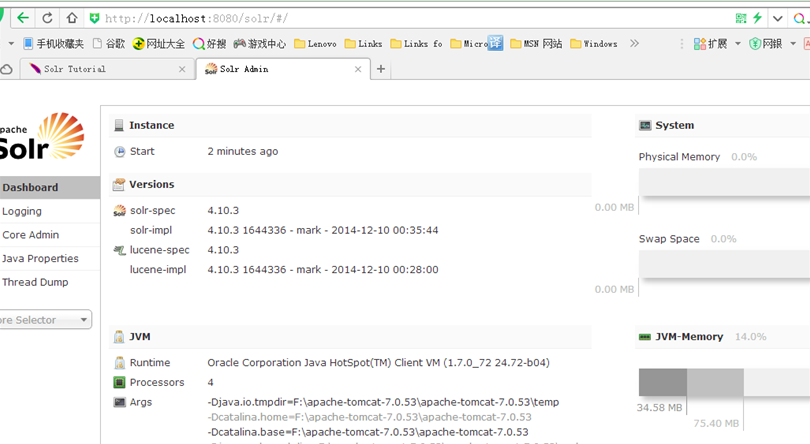
2.5 管理介面功能介紹
2.5.1 Dashboard
儀表盤,顯示了該Solr例項開始啟動執行的時間、版本、系統資源、jvm等資訊。
2.5.2 Logging
Solr執行日誌資訊
2.5.3 Cloud
Cloud即SolrCloud,即Solr雲(叢集),當使用SolrCloud模式執行時會顯示此選單,該部分功能在第二個專案,即電商專案會講解。
2.5.4 Core Admin
Solr Core的管理介面。在這裡可以新增SolrCore例項。
2.5.5 java properties
Solr在JVM 執行環境中的屬性資訊,包括類路徑、檔案編碼、jvm記憶體設定等資訊。
2.5.6 Tread Dump
顯示Solr Server中當前活躍執行緒資訊,同時也可以跟蹤執行緒執行棧資訊。
2.5.7 Core selector(重點)
選擇一個SolrCore進行詳細操作,如下:

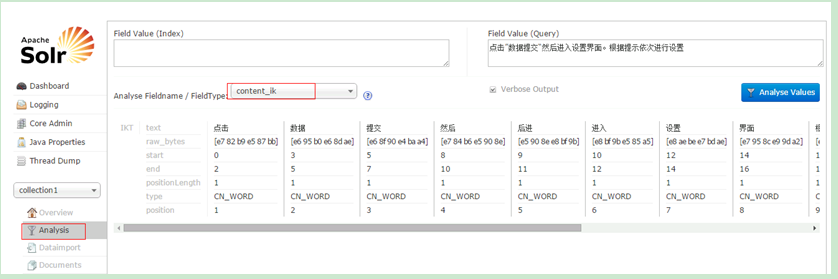
2.5.7.1 Analysis(重點)

通過此介面可以測試索引分析器和搜尋分析器的執行情況。
注:solr中,分析器是繫結在域的型別中的。
2.5.7.2 dataimport
可以定義資料匯入處理器,從關係資料庫將資料匯入到Solr索引庫中。
預設沒有配置,需要手工配置。
2.5.7.3 Document(重點)
通過/update表示更新索引,solr預設根據id(唯一約束)域來更新Document的內容,如果根據id值搜尋不到id域則會執行新增操作,如果找到則更新。
通過此選單可以建立索引、更新索引、刪除索引等操作,介面如下:
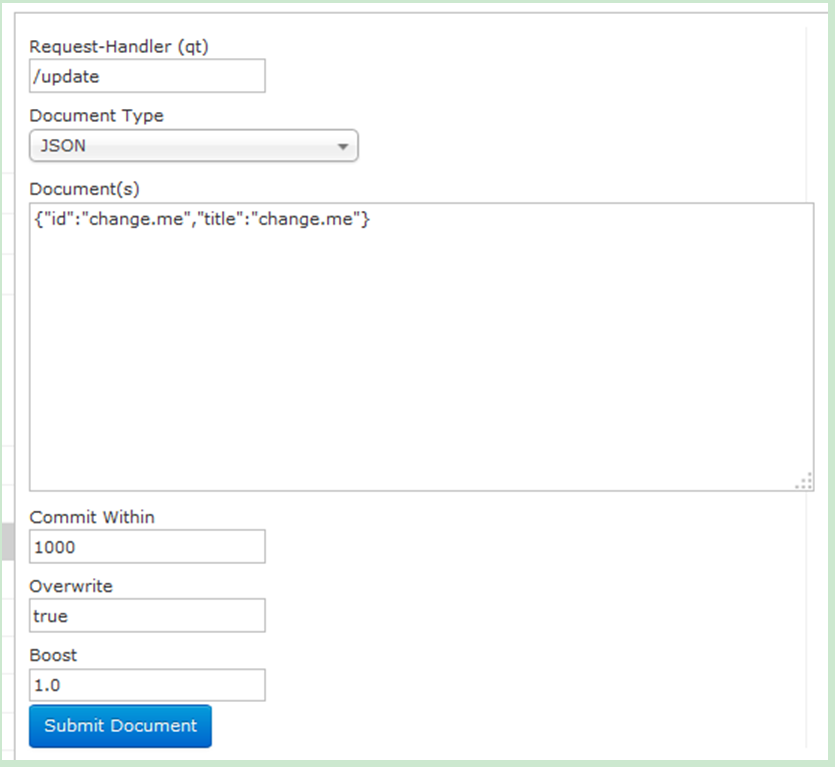
l overwrite="true" : solr在做索引的時候,如果文件已經存在,就用xml中的文件進行替換
l commitWithin="1000" : solr 在做索引的時候,每個1000(1秒)毫秒,做一次文件提交。為了方便測試也可以在Document中立即提交,</doc>後新增“<commit/>”
2.5.7.4 Query(重點)
通過/select執行搜尋索引,必須指定“q”查詢條件方可搜尋。
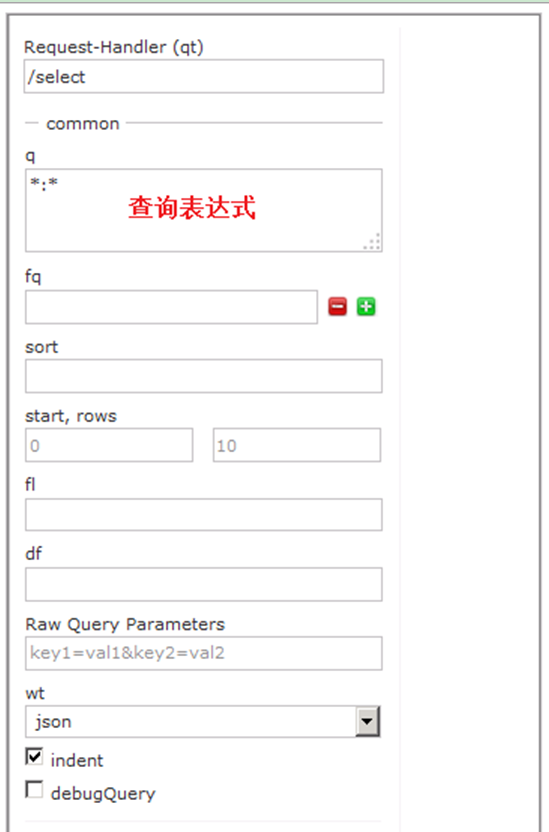
2.6 多solrcore配置
1. 一個solr工程對外通過SorlCore 提供服務,每個SolrCore相當於一個數據庫,這個功能就相當於一個MySQL可以執行多個數據庫。
2. 將索引資料分SolrCore儲存,方便對索引資料管理維護。
3. SolrCloud叢集需要使用多core。
複製原來的core目錄為collection2,目錄結構如下:
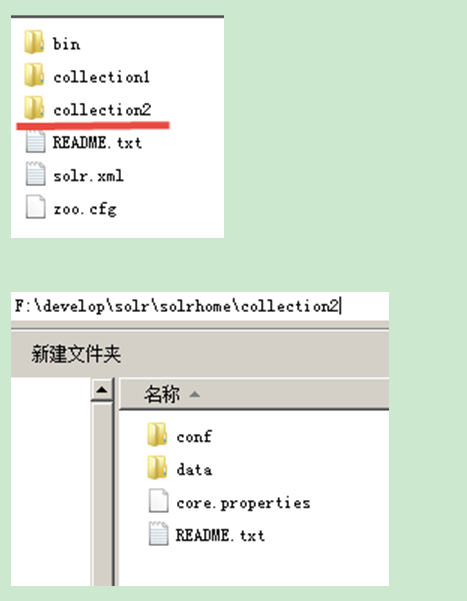
修改collection2下的core.properties,如下:
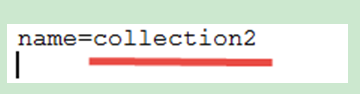
演示多core的使用,在collection1和collection2中分別建立索引、搜尋索引。
3 solr基本使用
3.1 schema.xml
schema.xml檔案在SolrCore的conf目錄下,它是Solr資料表配置檔案,在此配置檔案中定義了域以及域的型別還有其他一些配置,在solr中域必須先定義後使用。
3.1.1 field
|
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> |
l Name:域的名稱
l Type:域的型別
l Indexed:是否索引
l Stored:是否儲存
l Required:是否必須
l multiValued:是否是多值,儲存多個值時設定為true,solr允許一個Field儲存多個值,比如儲存一個使用者的好友id(多個),商品的圖片(多個,大圖和小圖)
3.1.2 fieldType(域型別)
- <fieldTypename="text_general"class="solr.TextField"positionIncrementGap="100">
- <analyzertype="index">
- <tokenizerclass="solr.StandardTokenizerFactory"/>
- <filterclass="solr.StopFilterFactory"ignoreCase="true"words="stopwords.txt"/>
- <!-- in this example, we will only use synonyms at query time
- <filterclass="solr.SynonymFilterFactory"synonyms="index_synonyms.txt"ignoreCase="true"expand="false"/>
- -->
- <filterclass="solr.LowerCaseFilterFactory"/>
- </analyzer>
- <analyzertype="query">
- <tokenizerclass="solr.StandardTokenizerFactory"/>
- <filterclass="solr.StopFilterFactory"ignoreCase="true"words="stopwords.txt"/>
- <filterclass="solr.SynonymFilterFactory"synonyms="synonyms.txt"ignoreCase="true"expand="true"/>
- <filterclass="solr.LowerCaseFilterFactory"/>
- </analyzer>
- </fieldType>
l name:域型別的名稱
l class:指定域型別的solr型別。
l analyzer:指定分詞器。在FieldType定義的時候最重要的就是定義這個型別的資料在建立索引和進行查詢的時候要使用的分析器analyzer,包括分詞和過濾。
l type:index和query。Index 是建立索引,query是查詢索引。
l tokenizer:指定分詞器
l filter:指定過濾器
3.1.3 uniqueKey
|
<uniqueKey>id</uniqueKey> |
相當於主鍵,每個文件中必須有一個id域。
3.1.4 copyField(複製域)
|
<copyField source="cat" dest="text" /> |
可以將多個Field複製到一個Field中,以便進行統一的檢索。當建立索引時,solr伺服器會自動的將源域的內容複製到目標域中。
l source:源域
l dest:目標域,搜尋時,指定目標域為預設搜尋域,可以提供查詢效率。
定義目標域:

必須要使用:multiValued="true"
3.1.5 dynamicField(動態域)
|
<dynamicField name="*_i" type="int" indexed="true" stored="true"/> |
l Name:動態域的名稱,是一個表示式,*匹配任意字元,只要域的名稱和表示式的規則能夠匹配就可以使用。
例如:搜尋時查詢條件【product_i:鑽石】就可以匹配這個動態域,可以直接使用,不用單獨再定義一個product_i域。
3.2 配置中文分析器
使用IKAnalyzer中文分析器。
第一步:把IKAnalyzer2012FF_u1.jar新增到solr/WEB-INF/lib目錄下。
第二步:複製IKAnalyzer的配置檔案和自定義詞典和停用詞詞典到solr的classpath下。
第三步:在schema.xml中新增一個自定義的fieldType,使用中文分析器。
|
<!-- IKAnalyzer--> <fieldType name="text_ik" class="solr.TextField"> <analyzer class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> |
第四步:定義field,指定field的type屬性為text_ik
|
<!--IKAnalyzer Field--> <field name="title_ik" type="text_ik" indexed="true" stored="true" /> <field name="content_ik" type="text_ik" indexed="true" stored="false" multiValued="true"/> |
第五步:重啟tomcat
測試:

3.3 配置業務field
3.3.1 需求
要使用solr實現電商網站中商品搜尋。
電商中商品資訊在mysql資料庫中儲存了,將mysql資料庫中資料在solr中建立索引。
需要在solr的schema.xml檔案定義商品Field。
3.3.2 定義步驟
先確定定義的商品document的field有哪些?
可以根據mysql資料庫中商品表的欄位來確定:
products商品表:
商品document的field包括:pid、name、catalog、catalog_name、price、description、picture
先定義Fieldtype:
solr本身提供的fieldtype型別夠用了不用定義新的了。
再定義Field:
pid:商品id主鍵
使用solr本身提供的:
<field name="id"type="string" indexed="true" stored="true"required="true" multiValued="false" />
name:商品名稱
<field name="product_name"type="text_ik" indexed="true" stored="true"/>
catalog:商品分類
<field name="product_catalog"type="string" indexed="true" stored="true"/>
catalog_name:商品分類名稱
<field name="product_catalog_name"type="text_ik" indexed="true" stored="true"/>
price:商品價格
<fieldname="product_price" type="float" indexed="true"stored="true"/>
description:商品描述
<fieldname="product_description" type="text_ik"indexed="true" stored="false"/>
picture:商品圖片
<field name="product_picture"type="string" indexed="false" stored="true"/>
相關推薦
Solr 全文搜尋服務
Solr 全文搜尋服務 1 Solr介紹 1.1 什麼是solr Solr 是Apache下的一個頂級開源專案,採用Java開發,它是基於Lucene的全文搜尋伺服器。Solr可以獨立執行在Jetty、To
快速入門全文搜尋服務 -- solr 7.4.0 (有java的增刪改查程式碼)
solr圖示簡介 看了上面的圖示介紹,你可能會問,那資料庫在solr中有什麼用呢?是不是有了solr的索引庫我們就不需要建立索引庫了呢? 其實不然 第一,資料庫可以作為索引庫資料的備份,當索引庫損壞時,可以將資料庫中的資料匯入到索引庫中。 第二,當你要升級s
Solr全文搜尋伺服器
Solr全文搜尋伺服器 示意圖&nb
Solr全文搜尋伺服器的搭建以及在Java中的使用(solr單機版)
直接步入正題。。。。。。Solr的搭建環境:JDK:1.8.0_161Tomcat:7.0.57OS:CentOS 7Solr服務搭建:第一步:將solr的壓縮包上傳至Linux系統,下載地址:http://www.apache.org/dyn/closer.lua/luce
solr全文搜尋搭建
因為最近專案要用到全文搜尋,然後挑選了solr作為全文搜尋實現方式,下載的是solr4.10.4版本,下面主要說下solr伺服器搭建主要步驟: 1、把解壓後solr-4.10.4\example\webapps下的solr.war拷到tomcat下進行部署,然後
Solr(全文搜尋功能)的介紹,安裝及配置
Solr(全文搜尋功能) Solr是什麼? Solr 是Apache下的一個頂級開源專案,採用Java開發,它是基於Lucene的全文搜尋伺服器。Solr提供了比Lucene更為豐富的查詢語言,同時實現了可配置、可擴充套件,並對索引、搜尋效能進行了優
瞭解學習 Elasticsearch 及其與 Python 實現全文搜尋
Elasticsearch簡介 ElasticSearch是一個基於Lucene的搜尋伺服器.它提供了一個分散式多使用者能力的全文搜尋引擎,基於RESTful web介面。Elasticsearch是用Java開發的,並作為Apache許可條款下的開放原始碼釋出,是當前流行的企業級搜尋引擎。設計
Eclipse Ctrl+H 全文搜尋正則表示式應用
Eclipse IDE 有個強大的搜尋工具,選單search -> search或快捷鍵Ctrl+H,即可開啟搜尋對話方塊,如下圖所示: 上圖所示為查詢檔案中包含toSelectDataSource字串的所有js或jsp檔案,並且大小寫敏感。 除此之外,還可以使用正則實現功能更加
ElasticSearch最佳入門實踐(三十八)精確匹配與全文搜尋的對比分析
1、ES中的兩種搜尋模式 1、exact value 2、full text 2、exact value 2017-01-01,exact value,搜尋的時候,必須輸入2017-01-01,才能搜尋出來。如果你輸入一個01,是搜尋不
如何使用ABAP Restful API進行程式碼的全文搜尋
使用這個程式碼全文搜尋的前提條件,是在事務碼SFW5裡啟用業務功能:SRIS_SOURCE_SEARCH 只需要把這個url貼到瀏覽器裡: https:// 意思是搜尋host指定的伺服器上所有包含了字串Jerry的ABAP程式碼。 瀏覽器裡顯示的結果: 隨便驗證幾個結果,證明搜尋是準確
全文搜尋技術--solr7.1之mysql的安裝步驟
1.安裝命令 #>線上安裝wget http://repo.mysql.com/mysql-community-release-el7-5.noarch.rpm 輸完上面一句話不能正常的下載安裝包可以試試下面這句話 yum -y install wget 然後繼續執行下面的語句 rpm -ivh
全文搜尋技術--Solr7.1之配置中文分析器
前言:中國文化博大精深,但是solr只能一個一個的識別,而是更加符合中國人的習慣,所以加了中文分析器。 1.安裝中文分詞器 第一步:把中文分詞器(ik-analyzer-solr7-7.x.jar)/usr/local/solr_tomcat/webapps/solr/WEB-INF/lib下 第二步:
sphinx全文搜尋在windows下安裝與使用方法
sphinx-for-chinese的使用方法將使用 sphinx-for-chinese-2.2.1-dev-r4311-win32 為例子,目前我只找到最新的是這個版本2013.11.09釋出。 下載地址:http://sphinxsearchcn.github.io/ 下載完後解壓出來得到以下
ElasticSearch搜尋服務技術
ElasticSearch 基於的lucene開發的搜尋服務技術;天生支援分散式; Es的結構 gatway:儲存層,所有的資料可以儲存在本地(多個es節點形成分散式儲存),hdfs輸出位置,共享檔案等 分散式lucene框架:把lucene缺少的分散式支援,做成一個基於lucen
Springboot+AngularJS+Spring-data-Solr:搜尋內容匹配高亮顯示
Java後臺部分: package com.phubing.search.service.impl; import java.util.HashMap; import java.util.List; import java.util.Map; import org.springframe
使用haystack實現Django的全文搜尋 -- Elasticsearch搜尋引擎
全文搜尋: 在使用python進行web開發的時候,免不了需要使用到全文搜尋;全文搜尋和我們平常使用的資料庫的模糊搜尋查詢不一樣,例如在mysql資料庫中,如果進行模糊查詢,比如 name like '%wang%'這一類的,效率是非常低的;而我們需求的全文搜尋,在效率方面要求是很高
全文搜尋儲存引擎 Elasticsearch 一點點
開始請大家想一個問題,如何統計一個Web站點的有效PV? 針對使用者請求的URL,統計時做模式匹配-------->即使用者真正去開啟一個站點的有效頁面並對每個頁面的入口的訪問做一個統計瀏覽量; 簡要搜尋引擎 搜尋引擎在網際網路上特別多有專業(Startpage,Google,Yah
ArangoDB 釋出 3.4 正式版:全文搜尋、GeoJSON、流式遊標
多模型資料庫的理念是:給你提供了一種多檢視檢視資料的能力。ArangoDB 的資料庫背後的理念是:可以自由的將這些檢視組合到單個查詢中。在 ArangoDB 3.4的更新中,我們進一步的擴充套件了 ArangoDB 的這些功能。對於每次釋出 ArangoDB 的新版本,我
SQL Server全文搜尋(轉載)
看這篇文章之前請先看一下下面我摘抄的全文搜尋的MSDN資料,基本上MSDN上關於全文搜尋的資料的我都copy下來了並且非常認真地閱讀和試驗了一次,並且補充了一些SQL語句,這篇文章本人抽取了一些本人自認為是重點的出來並且加入了一些自己的內容,補充MSDN上沒有的和整理了網上關於全文搜尋的資料至於全文搜尋的效能
Elasticsearch全文搜尋控制精準度
前言 本文主要是關於全文搜尋控制精準度的操作 其他搜尋請參考: 一、使用operator 搜尋結果中必須至少包括run、jump兩種愛好 GET people/_search {