
SQL優化:基本概念(索引調優、統計資訊、查詢調整、資源調控)
1、索引碎片
/*======================================================= 注意:所有的引數都是以當前資料庫來計算的,所以必須指定完全限定。 模式影響如何收集碎片資料: LIMITED:掃描堆所有的頁,對於索引,只掃描葉級別上面的父級別頁 SAMPLED:收集堆或索引中1%取樣率的資料 DETAILED:掃描所有頁,最精確但速度最慢 當制定null或default時,等同於limited模式。 ===================================================*/ select DB_NAME(d.database_id), OBJECT_NAME(d.object_id), i.name, --索引名稱 d.index_type_desc, d.alloc_unit_type_desc, d.index_depth, --索引的深度 d.index_level, --索引當前級別 --索引的邏輯碎片,或 IN_ROW_DATA 分配單元中堆的區碎片 d.avg_fragmentation_in_percent, --IN_ROW_DATA分配單元的葉級別中的碎片數 d.fragment_count, --IN_ROW_DATA 分配單元的葉級別中的一個碎片的平均頁數 d.avg_fragment_size_in_pages, --對於索引,平均百分比應用於 IN_ROW_DATA 分配單元中 b 樹的當前級別 --對於堆,表示 IN_ROW_DATA 分配單元中所有資料頁的平均百分比 d.avg_page_space_used_in_percent, d.page_count, --索引或資料頁的總數 d.record_count, --總記錄數 d.min_record_size_in_bytes, --最小記錄大小(位元組) d.max_record_size_in_bytes, --最大記錄大小(位元組) d.avg_record_size_in_bytes, --平均記錄大小(位元組) --壓縮頁的數目 d.compressed_page_count, --分配單元中將被虛影清除任務刪除的虛影記錄數 d.ghost_record_count, --由分配單元中未完成的快照隔離事務保留的虛影記錄數 d.version_ghost_record_count, --堆中具有指向另一個數據位置的轉向指標的記錄數 d.forwarded_record_count from sys.dm_db_index_physical_stats (db_id('wcc'), --資料庫id null, --物件id:資料庫名稱.架構.物件名稱 null, --索引id null, --分割槽號 '' --模式 )d inner join sys.indexes i on d.object_id = i.object_id and d.index_id = i.index_id
2、索引使用情況
create table txt(id int primary key,v varchar(10)) create index idx_txt_v on txt (v) insert into txt values(1,'a'), (2,'b'), (3,'c') select v from txt --idx_txt_v索引中的user_scans會顯示1 --user_updates會顯示1 select DB_NAME(d.database_id), OBJECT_NAME(d.object_id), i.name, user_seeks, user_scans, user_lookups, user_updates --通過使用者查詢執行的更新次數 from sys.dm_db_index_usage_stats d inner join sys.indexes i on d.object_id = i.object_id and d.index_id = i.index_id where database_id = DB_ID('test2') --新增資料後,user_updates會顯示2 insert into txt values(4,'a'), (5,'b'), (6,'c')
丟失的索引
SELECT TOP 30 ROUND(s.avg_total_user_cost * s.avg_user_impact * ( s.user_seeks + s.user_scans ), 0) AS [Total Cost] , s.avg_total_user_cost * ( s.avg_user_impact / 100.0 ) * ( s.user_seeks + s.user_scans ) AS Improvement_Measure , DB_NAME() AS DatabaseName , d.[statement] AS [Table Name] , equality_columns , inequality_columns , included_columns FROM sys.dm_db_missing_index_groups g INNER JOIN sys.dm_db_missing_index_group_stats s ON s.group_handle = g.index_group_handle INNER JOIN sys.dm_db_missing_index_details d ON d.index_handle = g.index_handle WHERE s.avg_total_user_cost * ( s.avg_user_impact / 100.0 ) * ( s.user_seeks + s.user_scans ) > 10 ORDER BY [Total Cost] DESC , s.avg_total_user_cost * s.avg_user_impact * ( s.user_seeks + s.user_scans ) DESC
3、統計資訊
--建立有主鍵的表,會自動建立聚集索引,自動生成索引所對應的統計資訊
create table txt(id numeric(10,0) primary key,
v varchar(20),
vv int )
--建立非聚集索引後自動生成索引所對應的統計資訊
create index txt_v on txt(v)
insert into txt
select object_id,
type_desc,
schema_id
from sys.objects
where LEN(type_desc) < 20
--1.1建立統計資訊,通過掃描表或索引檢視中的所有行來計算統計資訊
create statistics txtStats
on dbo.txt(v,vv)
with fullscan
--1.2採用為10%的行
create statistics txtStatsPercent
on dbo.txt(v,vv)
with sample 10 percent
--1.3取樣為100行
create statistics txtStatsRow
on dbo.txt(v,vv)
where id < 1000 --使用篩選謂詞建立的統計資訊
with sample 100 rows,
norecompute --覆蓋資料庫選項選項AUTO_STATISTICS_UPDATE
--查詢優化器將完成statistics_name的任何正在進行中的統計資訊更新
--並禁用將來的更新
--2.更新表或索引檢視的統計資訊
--2.1更新表中為某些列建立的統計資訊
update statistics txt(txtStats)
update statistics txt(txtStats)
with sample 50 percent
update statistics txt(txtStatsRow)
with resample, --使用最近的取樣速率更新每個統計資訊
norecompute --查詢優化器將完成此統計資訊更新並禁用將來的更新
--2.2更新索引的統計資訊
update statistics txt(txt_v)
with fullscan
--2.3更新表的所有統計資訊
update statistics txt
with all
--2.4更新表中所有為某一些列建立的統計資訊
update statistics txt(txt_v)
with columns
--2.5更新表中所有為索引建立的統計資訊
update statistics txt(txt_v)
with index
/*==============================================
呼叫CREATE STATISTICS語句以便對於不是統計資訊物件中第一列的列建立單列統計資訊。
建立單列統計資訊會增加直方圖的數目,這可能會改進基數估計、查詢計劃和查詢效能。
統計資訊物件的第一列具有直方圖;其他列不具有直方圖.
在查詢執行時間很重要並且不能等待查詢優化器以生成單列統計資訊時,
sp_createstats對於基準確定之類的應用程式十分有用。
在大多數情況下,無需使用sp_createstats,
而是由查詢優化器根據需要生成單列統計資訊,
以便在AUTO_CREATE_STATISTICS選項為ON時改進查詢計劃.
========================================================*/
--3.1引數值預設都是NO.
[email protected]:僅對位於現有索引中並且不是任何索引定義中的第一列的列建立統計資訊
[email protected]: 將CREATE STATISTICS語句與FULLSCAN選項一起使用
[email protected]:將CREATE STATISTICS語句與NORECOMPUTE選項一起使用
exec sp_createstats
@indexonly ='indexonly',
@fullscan ='fullscan',
@norecompute = 'norecompute'
--3.2對當前資料庫中所有使用者定義表和內部表執行UPDATE STATISTICS
--將使用預設的抽樣來更新統計資訊
exec sp_updatestats @resample = 'no'
--使用UPDATE STATISTICS語句的RESAMPLE選項來更新統計資訊
exec sp_updatestats @resample = 'resample'
/*====================================================
4.顯示錶或索引檢視的當前查詢優化統計資訊
查詢優化器使用統計資訊來估計查詢結果中的基數或行數,
查詢優化器就可以建立高質量的查詢計劃。
例如,查詢優化器可以使用基數估計,在查詢計劃中選擇索引查詢運算子而不是索引掃描運算子,
避免消耗大量資源的索引掃描,提高查詢效能。
對於表,統計資訊是根據索引或表列的列表建立的。
統計資訊包含一個帶有統計資訊的相關元資料的標題、
一個用於度量各列之間的相關性的密度向量、
一個帶有統計資訊第一個鍵列中的值的分佈的直方圖。
資料庫引擎可以使用統計資訊中的任何資料計算基數估計。
DBCC SHOW_STATISTICS 根據統計資訊物件中儲存的資料顯示標題、直方圖和密度向量。
使用以下語法,您可以指定表或索引檢視以及target(目標索引名稱、統計資訊名稱或列名)
DBCC SHOW_STATISTICS ( table_or_indexed_view_name , target )
[ WITH [ NO_INFOMSGS ] < option > [ , n ] ]
< option > :: =
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM
======================================================*/
DBCC SHOW_STATISTICS('dbo.txt','txtStats')
DBCC SHOW_STATISTICS('dbo.txt','vv') with HISTOGRAM
--5.刪除某個表的統計資訊
drop statistics txt.txtStatsRow,
txt.txtStatsPercent --表.統計資訊名
統計資訊的更新時間:
--1.更新日期,列名
select stats_date(s.object_id,s.stats_id) 統計資訊的最新更新的日期,
c.name as 列名,
*
from sys.stats s
inner join sys.stats_columns sc
on s.object_id = sc.object_id and
s.stats_id = sc.stats_id
inner join sys.columns c
on s.object_id = c.object_id and
sc.column_id = c.column_id
where s.object_id = object_id('xx')
--2.或者直接這樣
sp_helpstats 'xx'
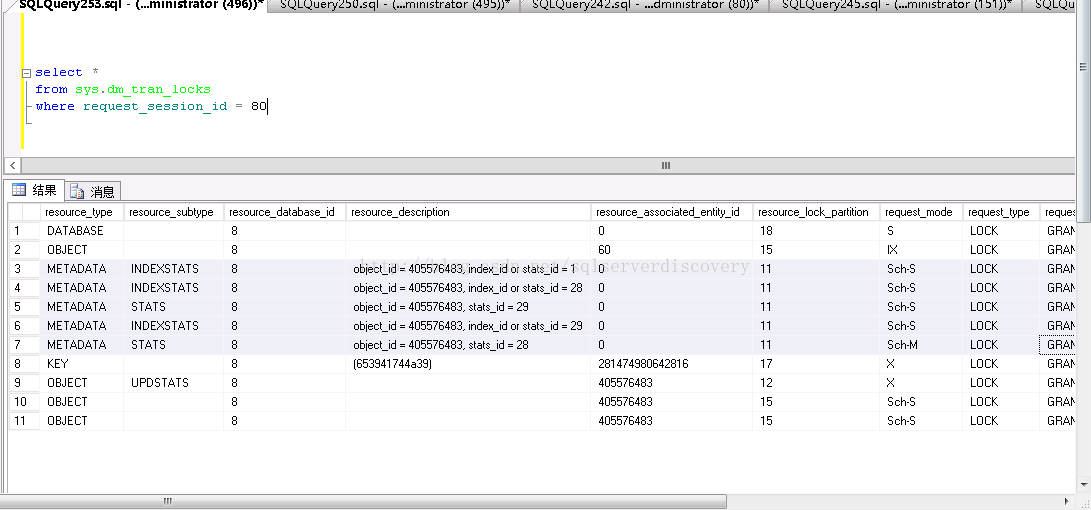
那麼在更新某個表的統計資訊時,會導致阻塞問題嗎?
通過實驗發現,在更新某個表的統計資訊時,會對錶加上X鎖,這個肯定會導致阻塞問題:
4、查詢調整
create table txt(id numeric(10,0) primary key,
v varchar(20),
vv int )
create index txt_v on txt(v)
insert into txt
select object_id,
type_desc,
schema_id
from sys.objects
where LEN(type_desc) < 20
/*=================================================
1.1動態sql語句很容易導致SQL注入,與儲存過程不同的是,
動態sql、常規即席查詢在每次執行時都會生成新的執行計劃,
所以查詢的效能不穩定.
===================================================*/
exec ('select * from txt');
/*===============================================
1.2建立可重複使用的、只有查詢引數不同的查詢計劃,
來處理動態sql的效能問題.
引數是型別安全的,不能以非指定的資料型別使用,
也就是引數型別與欄位型別必須一致,否則會報錯.
=================================================*/
exec sp_executesql
@statement = N'select *
from txt
where id > @id and
vv > @vv',
@params = N'@id numeric(10,0),
@vv int', --定義為@id int時會報錯
@id = 10000,
@vv = 2
--2.強制SQL Server使用特定的查詢計劃
set statistics xml on
select *
from txt
where id > 1000 and
vv > 2
set statistics xml off
select *
from txt
option(
use plan
'<ShowPlanXML xmlns="http://schemas.microsoft.com/sqlserver/2004/07/showplan"
Version="1.1" Build="10.50.1600.1">
<BatchSequence><Batch><Statements>
<StmtSimple StatementText="SELECT * FROM [txt] WHERE [id]>@1 AND [vv]>@2"
StatementId="1" StatementCompId="1" StatementType="SELECT" StatementSubTreeCost="0.00429444"
StatementEstRows="42.2945" StatementOptmLevel="TRIVIAL" QueryHash="0xA4E0AA4B0A87F88B"
QueryPlanHash="0x3325250D8A42F500">
<StatementSetOptions QUOTED_IDENTIFIER="true" ARITHABORT="true" CONCAT_NULL_YIELDS_NULL="true"
ANSI_NULLS="true" ANSI_PADDING="true" ANSI_WARNINGS="true" NUMERIC_ROUNDABORT="false"/>
<QueryPlan DegreeOfParallelism="1" CachedPlanSize="16" CompileTime="1" CompileCPU="1"
CompileMemory="136"><RelOp NodeId="0"
PhysicalOp="Clustered Index Seek" LogicalOp="Clustered Index Seek"
EstimateRows="42.2945" EstimateIO="0.00386574" EstimateCPU="0.0004287"
AvgRowSize="34" EstimatedTotalSubtreeCost="0.00429444"
TableCardinality="292" Parallel="0" EstimateRebinds="0" EstimateRewinds="0">
<OutputList><ColumnReference Database="[test2]"
Schema="[dbo]" Table="[txt]" Column="id"/><ColumnReference
Database="[test2]" Schema="[dbo]" Table="[txt]" Column="v"/>
<ColumnReference Database="[test2]" Schema="[dbo]" Table="[txt]" Column="vv"/>
</OutputList><RunTimeInformation><RunTimeCountersPerThread Thread="0"
ActualRows="5" ActualEndOfScans="1" ActualExecutions="1"/>
</RunTimeInformation><IndexScan Ordered="1" ScanDirection="FORWARD"
ForcedIndex="0" ForceSeek="0" NoExpandHint="0"><DefinedValues>
<DefinedValue><ColumnReference Database="[test2]"
Schema="[dbo]" Table="[txt]" Column="id"/>
</DefinedValue><DefinedValue><ColumnReference
Database="[test2]" Schema="[dbo]" Table="[txt]"
Column="v"/></DefinedValue><DefinedValue>
<ColumnReference Database="[test2]" Schema="[dbo]"
Table="[txt]" Column="vv"/></DefinedValue></DefinedValues>
<Object Database="[test2]" Schema="[dbo]" Table="[txt]"
Index="[PK__txt__3213E83F4D1564AE]" IndexKind="Clustered"/>
<SeekPredicates><SeekPredicateNew><SeekKeys>
<StartRange ScanType="GT"><RangeColumns>
<ColumnReference Database="[test2]" Schema="[dbo]" Table="[txt]"
Column="id"/></RangeColumns><RangeExpressions><ScalarOperator
ScalarString="CONVERT_IMPLICIT(numeric(10,0),[@1],0)"><Identifier>
<ColumnReference Column="ConstExpr1003"><ScalarOperator>
<Convert DataType="numeric" Precision="10" Scale="0" Style="0" Implicit="1">
<ScalarOperator><Identifier><ColumnReference Column="@1"/>
</Identifier></ScalarOperator></Convert></ScalarOperator>
</ColumnReference></Identifier></ScalarOperator>
</RangeExpressions></StartRange></SeekKeys></SeekPredicateNew>
</SeekPredicates><Predicate><ScalarOperator
ScalarString="[test2].[dbo].[txt].[vv]>CONVERT_IMPLICIT(int,[@2],0)"><Compare CompareOp="GT">
<ScalarOperator><Identifier><ColumnReference Database="[test2]" Schema="[dbo]"
Table="[txt]" Column="vv"/></Identifier></ScalarOperator><ScalarOperator>
<Identifier><ColumnReference Column="ConstExpr1004"><ScalarOperator>
<Convert DataType="int" Style="0" Implicit="1"><ScalarOperator>
<Identifier><ColumnReference Column="@2"/></Identifier>
</ScalarOperator></Convert></ScalarOperator></ColumnReference>
</Identifier></ScalarOperator></Compare></ScalarOperator>
</Predicate></IndexScan></RelOp><ParameterList>
<ColumnReference Column="@2" ParameterCompiledValue="(2)" ParameterRuntimeValue="(2)"/>
<ColumnReference Column="@1" ParameterCompiledValue="(1000)"
ParameterRuntimeValue="(1000)"/></ParameterList></QueryPlan>
</StmtSimple></Statements></Batch></BatchSequence></ShowPlanXML>')
--3.不修改應用程式,應用查詢提示
exec sp_create_plan_guide
@name = 'plan_guide_txt',
@stmt = 'select *
from txt
inner join sys.objects o
on o.object_id = txt.id',
@type = 'sql',
@module_or_batch = null,
@params = null,
@hints = 'option(merge join)'
--當下面的這段程式碼與上面的程式碼完全一樣(包括空格,回車)時,系統才會應用查詢提示
select *
from txt
inner join sys.objects o
on o.object_id = txt.id
--4.從快取建立計劃指南
begin
select *
from txt
inner join sys.objects o
on o.object_id = txt.id
select *
from sys.objects
end
go
--找到計劃控制代碼
select e.text,
d.statement_start_offset,
d.plan_handle --計劃控制代碼
from sys.dm_exec_query_stats d
cross apply sys.dm_exec_sql_text(d.sql_handle)e
where e.text like '%from txt%'
/*========================================================
從計劃控制代碼建立計劃指南
引數@statement_start_offset:在批處理中可能會有多條語句,
此引數指出批處理中建立計劃指南的語句,在批處理中的開始偏移。
如果指定為NULL,那麼會為批處理中的所有語句建立計劃指南
==========================================================*/
exec sp_create_plan_guide_from_handle
@name = 'plan_guide_txt_handle',
@plan_handle = 0x060018007BA32F074021425A020000000000000000000000,
@statement_start_offset = 14
--5.使用計劃指南把非引數化查詢引數化
--5.1執行多條類似的查詢
select * from txt where id = 8
select * from txt where id = 9
--5.2通過查詢快取的計劃所對應的sql文字,發現很多都是相同的
--而且大部分的objtype都是proc,adhoc,prepared.
SELECT *
FROM SYS.dm_exec_cached_plans E
CROSS APPLY SYS.dm_exec_sql_text(E.plan_handle)EE
WHERE EE.text LIKE '%select * from txt where id =%'
declare @sqltext nvarchar(max)
declare @parameter nvarchar(max)
--5.3獲取查詢的引數化形式以及查詢的引數,放入變數中
exec sp_get_query_template
@querytext = N'select * from txt where id = 8',
@templatetext= @sqltext output,
@parameters = @parameter output
--5.4使用模板來建立計劃指南
exec sp_create_plan_guide
@name = 'plan_guide_txt_template',
@stmt = @sqltext,
@type = 'template',
@module_or_batch = null,
@params = @parameter,
@hints = 'option(parameterization forced)'
--5.5再次查詢發現多條執行計劃已經變為一條,usecounts計數增加
SELECT *
FROM SYS.dm_exec_cached_plans E
CROSS APPLY SYS.dm_exec_sql_text(E.plan_handle)EE
WHERE EE.text LIKE '%select * from txt where id =%'
--6.顯示計劃指南的元資料
select p.plan_guide_id,
p.name,
p.create_date,
p.modify_date,
p.is_disabled, --是否禁用計劃指南
p.query_text, --建立計劃指南所依據的查詢文字
p.scope_type, --3個型別:object,sql,template
p.scope_type_desc,
p.scope_object_id , --如果型別為object,那麼指出物件id
scope_batch, --如果scope_type為SQL,則為批處理文字。
--如果批處理型別不是SQL,則其值為NULL
p.parameters, --定義與計劃指南關聯的引數列表的字串
p.hints --與計劃指南關聯的 OPTION 子句提示
from sys.plan_guides p
/*=============================================================
7.驗證指定計劃指南的有效性。返回計劃指南應用於其查詢時遇到的第一條錯誤訊息。
如果計劃指南有效,則將返回一個空的行集。在更改資料庫的物理設計後,計劃指南可能會變為無效。
例如,如果計劃指南指定了特定索引並且隨後將該索引刪除,則查詢將不能再使用該計劃指南。
通過驗證計劃指南,可確定優化器是否能夠在不進行修改的情況下直接使用該指南。
例如,基於函式的結果,可決定刪除該計劃指南並重新調整查詢或修改資料庫設計,
例如,重新建立計劃指南中指定的索引。
===============================================================*/
select pp.msgnum, --錯誤訊息的 ID
pp.severity, --訊息的嚴重級別
pp.state, --錯誤的狀態號,用於指示發生錯誤的程式碼位置
pp.message --錯誤的訊息正文
from sys.plan_guides p
cross apply sys.fn_validate_plan_guide(p.plan_guide_id) pp
/*==============================================
8.刪除或者禁用計劃指南
disable,disable all:禁用(所有)計劃指南
enable,enable all:啟用(所有)計劃指南
drop,drop all:刪除(所有)計劃指南
注意:當指定all時,不能指定計劃指南名稱。
================================================*/
exec sp_control_plan_guide
@operation = 'disable', --禁用計劃指南
@name = 'plan_guide_txt'
--刪除所有計劃指南
exec sp_control_plan_guide
@operation = 'drop all'
5、資源調控
在SQL Server 2008中引入了使用資源調控器來限制工作負荷的資源消耗。在SQL Server內部包含了兩個資源池:預設和內部。內部資源池不能修改,並且使SQL Server的活動不受資源的限制。預設資源池可以把連線請求,連線、配置資源調控器,預設情況下沒有限制,之後可以修改。
一個或多個工作組可以繫結到一個資源池,使用工作負荷組可以定義資源池中重要的請求、最大授予記憶體比、最大以秒為單位的cpu時間、最大授予記憶體超時時間、最大並行度、同時執行的請求的最大數量。工作負荷組也包含:內部和預設工作組。預設工作組用在沒有被任何分類器使用者定義函式覆蓋的任何請求上。多個工作負荷組可以關聯到一個資源池,但是一個工作負荷組不能關聯到多個資源池。
在建立使用者定義工作負荷組和繫結到資源池後,可以建立一個幫助確定:進入的SQL Server連線和請求屬於哪個工作負荷組的分類器使用者定義函式。
--1.建立資源池
--建立應用程式資源池
create resource pool app_query
with
(
MIN_CPU_PERCENT = 25,
MAX_CPU_PERCENT = 75,
MIN_MEMORY_PERCENT = 25,
MAX_MEMORY_PERCENT = 75
)
--建立即席查詢資源池
CREATE RESOURCE POOL adhoc_query
with
(
min_cpu_percent = 5,
max_cpu_percent = 25,
min_memory_percent = 5,
max_memory_percent = 25
)
--修改即席查詢資源池
alter resource pool adhoc_query
with
(
min_memory_percent = 10,
max_memory_percent = 50
)
--2.建立工作負荷組
--建立應用程式a的工作負荷組
create workload group app_a
with
(
importance = high,
request_max_memory_grant_percent = 75,
request_max_cpu_time_sec = 75,
request_memory_grant_timeout_sec = 120,
max_dop = 8,
group_max_requests = 8
)
using app_query --使用應用程式資源池
--建立應用程式b的工作負荷組
create workload group app_b
with
(
importance = low,
request_max_memory_grant_percent = 50,
request_max_cpu_time_sec = 50,
request_memory_grant_timeout_sec = 360,
max_dop = 1,
group_max_requests = 4
)
using app_query --使用應用程式資源池
--建立即席查詢工作負荷組
create workload group adhoc_user
with
(
importance = low,
request_max_memory_grant_percent = 100,
request_max_cpu_time_sec = 120,
request_memory_grant_timeout_sec = 360,
max_dop = 1,
group_max_requests = 5
)
using adhoc_query
--修改工作負荷組
alter workload group app_b
with
(
importance = medium
)
--3.分類器函式必須在master資料庫中建立
use master
go
--返回工作負荷組名稱,系統會根據工作組名稱,將連線定位到工作組所對應的資源池
create function dbo.wc_classifier()
returns sysname
with schemabinding
as
begin
declare @resource_group_name sysname
if SUSER_SNAME() in ('sa')
set @resource_group_name = 'app_a'
if SUSER_SNAME() in ('sa')
set @resource_group_name = 'app_b'
if HOST_NAME() in ('abc')
set @resource_group_name = 'adhoc_query'
if @resource_group_name is null
set @resource_group_name = 'default'
return @resource_group_name
end
go
--設定資源排程器的分類器函式,並且重新配置
alter resource governor
with
(
classifier_function = dbo.wc_classifier
)
go
--為了啟用配置,需要執行reconfigure
alter resource governor reconfigure
go
--4.檢視元資料
--資源池的元資料
select pool_id,
min_cpu_percent,
max_cpu_percent,
min_memory_percent,
max_memory_percent
from sys.resource_governor_resource_pools
--負荷工作組元資料
select group_id,
name,
pool_id,
importance,
request_max_memory_grant_percent,
request_max_cpu_time_sec,
request_memory_grant_timeout_sec,
max_dop,
group_max_requests
from sys.resource_governor_workload_groups
--顯示資源調控器的配置資訊,包含了:分類器函式,是否啟用
select classifier_function_id,
OBJECT_NAME(classifier_function_id,
DB_ID('master')
), --函式名
is_enabled --是否啟用
from sys.resource_governor_configuration
--5.刪除資源池,工作負荷組,分類器函式
use master
go
drop workload group app_a
drop workload group app_b
drop workload group adhoc_user
drop resource pool adhoc_query
drop resource pool app_query
--禁用設定
alter resource governor disable
--設定不在使用分類器函式
alter resource governor
with
(
classifier_function = null
)
--刪除分類器函式
drop function dbo.wc_classifier
相關推薦
SQL優化:基本概念(索引調優、統計資訊、查詢調整、資源調控)
1、索引碎片 /*======================================================= 注意:所有的引數都是以當前資料庫來計算的,所以必須指定完全限定。 模式影響如何收集碎片資料: LIMITED:掃描堆所有的頁,對於索引,
二叉排序樹的基本操作(建立,中序遍歷,查詢,刪除,插入)
分析: 二叉排序樹的操作的難點在於刪除操作,刪除操作時,只需要滿足二叉排序樹的性質即可,即需要找到要刪除結點p的左孩子的最右下方的數替代該結點的資料,然後刪除p->lchild的最右下方的結點即可。 對於p->lchild==NULL的,只需要讓雙親結點直接指向
SQL調優-統計資訊未及時更新導致查詢緩慢
預設情況下,查詢優化器已根據需要更新統計資訊以改進查詢計劃;但在某些情況下,您可以通過使用 UPDATE STATISTICS 或儲存過程 sp_updatestats 來比預設更新更頻繁地更新統計資訊
JVM調優總結(一):基本概念
一、資料型別 Java虛擬機器中,資料型別可以分為兩類:基本型別和引用型別。 基本型別的變數儲存原始值,即:他代表的值就是數值本身; 而引用型別的變數儲存引用值。“引用值”代表了某個物件的引用,而不是物件本身,物件本身存放在這個引用值所表示的地址的位置。
SQL Server調優系列進階篇(如何索引調優)
.cn 技術 spa 磁盤 clear 高頻 思路 ltp 覆蓋範圍 前言 上一篇我們分析了數據庫中的統計信息的作用,我們已經了解了數據庫如何通過統計信息來掌控數據庫中各個表的內容分布。不清楚的童鞋可以點擊參考。 作為調優系列的文章,數據庫的索引肯定
Python爬蟲(一):基本概念
popu 通用 字符 spider dai 自身 部分 螞蟻 people 網絡爬蟲的定義 網絡爬蟲(Web Spider。又被稱為網頁蜘蛛。網絡機器人,又稱為網頁追逐者),是一種依照一定的規則,自己主動的抓取萬維網信息的程序或者腳本。另外一些不常使用
Oracle知識梳理(一)理論篇:基本概念和術語整理
http 知識梳理 屬性集 操作 url 本質 開發 表格 weight 理論篇:基本概念和術語整理 一、關系數據庫 關系數據庫是目前應用最為廣泛的數據庫系統,它采用關系數據模型作為數據的組織方式,關系數據模型由關系的數據結構,關系的操作集合和關系的完整
spring基礎(1:基本概念)
poj 操作 共享問題 元素 組成 The 開發 let 可選值 本系列筆記來自對《Spring實戰》第三版的整理,Spring版本為3.0 ??spring是為了解決企業級應用開發的復雜性而創建的,spring最根本的使命是:簡化Java開發。為降低開發復雜性有以下四種關
Elasticsearch入門一:Elasticsearch的基本概念(譯)
一.Elasticsearch定義 Elasticsearch是一個開源的高度可擴充套件的全文搜尋和分析引擎。它允許您快速、實時的儲存、搜尋和分析大資料。它通常為具有複雜的搜尋特性和需求的應用提供底層引擎或技術。 Elasticsearch可以用於以下的一些場景: 運營一個網上商城
機器學習導論(張志華):基本概念
前言 這個筆記是北大那位老師課程的學習筆記,講的概念淺顯易懂,非常有利於我們掌握基本的概念,從而掌握相關的技術。 正文 Data Mining 是半自動化的 Machine Learning 是自動化的。 Michal Jordon。 ML:A f
《C語言程式設計:現代方法(第2版)(K.N.King 著)》學習筆記三:C語言基本概念(2)
2.3 註釋 每一個程式都應該包含識別資訊,即程式名、編寫日期、作者、程式的用途以及其他相關資訊。C語言把這類資訊放在註釋(comment)中。 符號 /* 標記註釋的開始,而符號 */ 則標記註釋
《C語言程式設計:現代方法(第2版)(K.N.King 著)》學習筆記四:C語言基本概念(3)
2.5 讀入輸入 為了獲取輸入,就要用到 scanf 函式。它是C函式庫中與 printf 相對應的函式。scanf 中的字母 f 和 printf 中的字母 f 含義相同,都是表示“格式化”的意思
《C語言程式設計:現代方法(第2版)(K.N.King 著)》學習筆記五:C語言基本概念(4)
2.7 識別符號 在編寫程式時,需要對變數、函式、巨集和其他實體進行命名。這些名字稱為識別符號(identifier)。在C語言中,識別符號可以含有字母、數字和下劃線,但是必須以字母或者下劃線開頭。
《C語言程式設計:現代方法(第2版)(K.N.King 著)》學習筆記六:C語言基本概念(5)
問與答 GCC 最初是 GNU C Compiler 的簡稱。現在指 GNU Compiler Collection,這是因為最新版本的 GCC 能夠編譯用 Ada、C、C++、Fortran、Ja
各種音視訊編解碼學習詳解之 編解碼學習筆記(一):基本概念
最近在研究音視訊編解碼這一塊兒,看到@bitbit大神寫的【各種音視訊編解碼學習詳解】這篇文章,非常感謝,佩服的五體投地。奈何大神這邊文章太長,在這裡我把它分解很多小的篇幅,方便閱讀。大神部落格傳送門:https://www.cnblogs.com/skyofbitbit/p/3651270.htm
Nginx 教程 (1):基本概念
簡介 嗨!分享就是關心!所以,我們願意再跟你分享一點點知識。我們準備了這個劃分為三節的《Nginx教程》。如果你對 Nginx 已經有所瞭解,或者你希望瞭解更多,這個教程將會對你非常有幫助。 我們會告訴你 Nginx 是如何工作的,其背後的概念有哪些,以及如何優化
【資料探勘概念與技術】學習筆記6-挖掘頻繁模式、關聯和相關性:基本概念和方法(編緝中)
頻繁模式是頻繁地出現在資料集中的模式(如項集、子序列或子結構)。頻繁模式挖掘給定資料集中反覆出現的聯絡。“購物籃”例子,想象全域是商店中商品的集合,每種商品有一個布林變數,表示該商品是否出現。則每個購物籃可以用一個布林向量表示。分析布林向量,得到反映商品頻繁關聯或同時購買的購買模式。這些模式可用關聯規則來表示
Druid.io系列(二):基本概念與架構
在介紹Druid架構之前,我們先結合有關OLAP的基本原理來理解Druid中的一些基本概念。 1 資料 以圖3.1為例,結合我們在第一章中介紹的OLAP基本概念,按列的型別上述資料可以分成以下三類: 時間序列(Timestamp),Druid既是記憶
Kubernetes筆記(1):基本概念
有關Kubernetes是什麼,網上很常見的一種介紹是:Kubernetes是Google開源的容器叢集管理系統,其提供應用部署、維護、擴充套件機制等功能,利用Kubernetes能方便地管理跨機器執行容器化的應用。 由此可見,K8s是構建在容器(Docker
Flex佈局(一:基本概念和容器屬性)
前言 算上來快2個月沒寫部落格呢,一是趕專案,二是中途接到一個朋友公司需要幫忙,週末都在TA們公司兼職,然後空下來就快12月初,然後又陸陸續續發生一些大事小事,當然最令人記憶猶新就是借錢。 這個月初由於財務出了點問題,找了幾個朋友借錢,當然也包括自己借過錢的