Spark技術架構,概念及執行過程
阿新 • • 發佈:2019-01-24
1.Spark技術架構
- Spark分散式記憶體計算平臺採用的是Master-Slave架構,叢集中含有Master程序的節點ClusterManager即為這裡的Master,而Slave則是叢集中的Work程序節點。
- Master作為整個叢集的控制器,負責整個叢集的正常執行,Worker則相當於是計算節點,接收主節點的命令,執行Driver或Excutor,並進行狀態彙報;Executor執行在Worker節點。
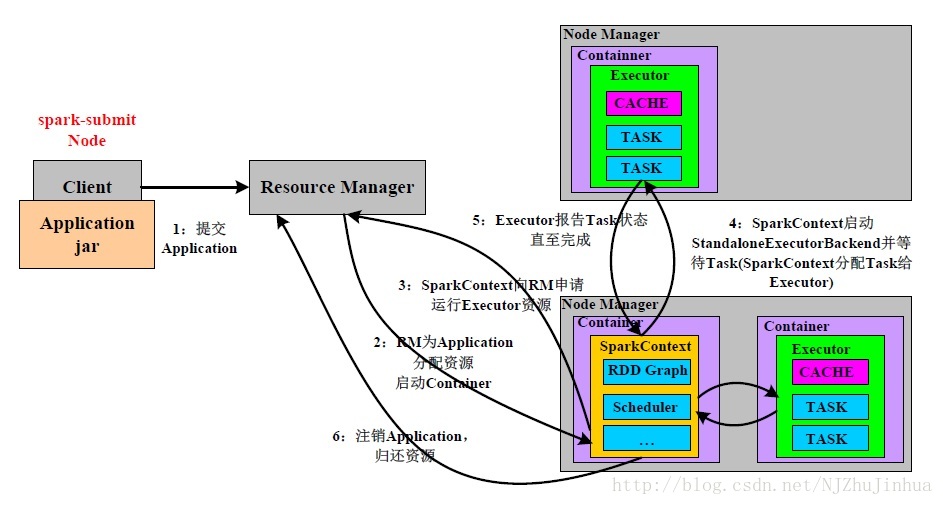
- 在Yarn執行框架下,由Yarn的ResourceManager擔任Master,Excutor則執行在NodeManager的Container中。
- Spark的提交執行流程:Spark作業在提交執行時,會指定master和deploy-mode兩個引數,共同決定了是standalone還是yarn/mesos資源管理託管模式。
- master引數包括:spark://host:port, mesos://host:port, yarn, yarn-cluster,yarn-client, local,預設為local[*]
- deploy-mode引數取值為client和cluster,分別意味著driver程式執行在哪裡,預設為client
- master取值local[n]:單機執行 spark://xxx在指定叢集上執行 yarn則為執行在yarn叢集中,yarn-cluster和yarn-client在spark2.0已經不推薦使用了,需要通過master和deploy-mode共同指定
// Set the cluster manager - Spark的任務流程:
2.Spark的基本概念
2.1 Application
使用者寫的spark程式,提交後為一個App,一個App內僅有一個SparkContext,此即App的Driver,驅動著整個App的執行。
2.2 Job
一個App內有多個Action運算元,這些action運算元觸發了RDD/Dataset的轉換,每個action對應著一個Job
2.3 Stage和DAGSchedule
Job的執行過程中根據shuffle的不同,分成了寬依賴和窄依賴,DAGSchedule據此講Job分成了不同的Stage,並將其提交給TaskSchedule執行
2.4 Task和TaskSchedule
Task為具體執行任務的基本單位,被TaskSchedule分發到excutor上執行
2.5 BlockManager
管理App執行過程中的中間資料,如記憶體磁碟等,cache/persist等的管理均通過BlockManager進行維護
2.6 寬依賴與窄依賴
RDD/DF等記憶體塊均是隻讀的,RDD的生成(除最初建立)靠的也是老RDD的轉換,所以RDD間通過這些依賴產生了關係。如果一個父RDD的每個分割槽只被子RDD的一個分割槽依賴,那這是窄依賴,相反如果子RDD的任意個分割槽的生成都依賴父RDD的每個分割槽,則為寬依賴。顯而易見,寬依賴影響很大。而在連續的多個窄依賴間因都是在同一個分割槽內,所以可連續多次處理而不用寫磁碟提高效率。DAG的Stage劃分也據此講一個Job劃分為了多個Stage,保證在每個Stage內是窄依賴。
3. 執行過程
3.1 Standalone
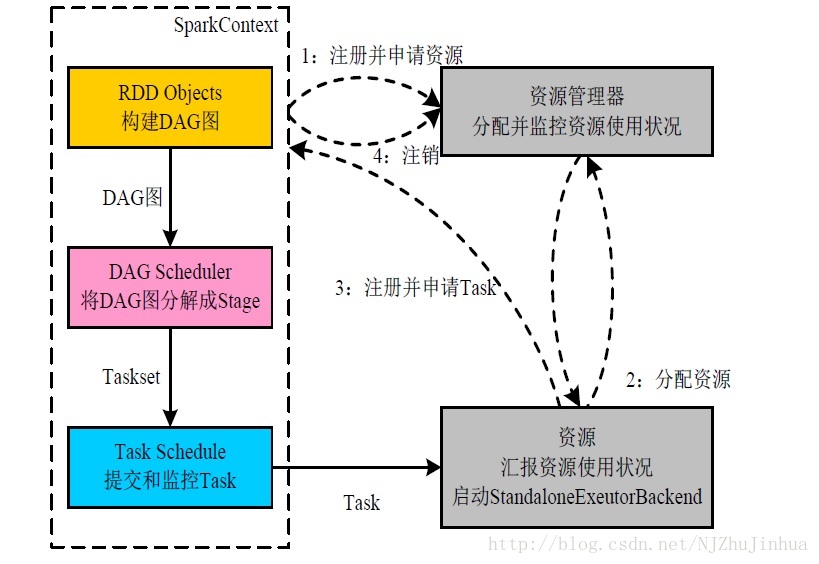
- 構建SparkApplication的執行環境(啟動SparkContext)
- SparkContext向資源管理器(Standalone的Master)申請執行Executor資源,並啟動StandaloneExecutorBackend
- Executor向SparkContext註冊
- SparkContext啟動應用程式DAG排程、Stage劃分,TaskSet生成
- TaskScheduler排程Taskset,將task發放給Executor執行。
- Task在Executor上執行,執行完畢釋放所有資源。
3.2 yarn cluster
圖中已經很清楚了