
Pig安裝及簡單例項
阿新 • • 發佈:2019-01-24
前面講到了如何用MapReduce進行資料分析。當業務比較複雜的時候,使用MapReduce將會是一個很複雜的事情,比如你需要對資料進行很多預處理或轉換,以便能夠適應MapReduce的處理模式。另一方面,編寫MapReduce程式,釋出及執行作業都將是一個比較耗時的事情。
Pig的出現很好的彌補了這一不足。Pig能夠讓你專心於資料及業務本身,而不是糾結於資料的格式轉換以及MapReduce程式的編寫。本質是上來說,當你使用Pig進行處理時,Pig本身會在後臺生成一系列的MapReduce操作來執行任務,但是這個過程對使用者來說是透明的。
Pig的安裝
Pig作為客戶端程式執行,即使你準備在Hadoop叢集上使用Pig,你也不需要在叢集上做任何安裝。Pig從本地提交作業,並和Hadoop進行互動。
1)下載Pig
前往http://mirror.bit.edu.cn/apache/pig/ 下載合適的版本,比如Pig 0.12.0
2)解壓檔案到合適的目錄
tar –xzf pig-0.12.0
3)設定環境變數
export PIG_INSTALL=/opt/pig-0.12.0
export PATH=$PATH:$PIG_INSTALL/bin
如果沒有設定JAVA環境變數,此時還需要設定JAVA_HOME,比如:
export JAVA_HOME=/usr/lib/jvm/java-6-sun
4)驗證
執行以下命令,檢視Pig是否可用:
pig –help
Pig執行模式
Pig有兩種執行模式,分別為:
1)本地模式(Local)
本地模式下,Pig執行在單一的JVM中,可訪問本地檔案。該模式適用於處理小規模資料或學習之用。
執行以下命名設定為本地模式:
pig –x local
2)MapReduce模式
在MapReduce模式下,Pig將查詢轉換為MapReduce作業提交給Hadoop(可以說群集 ,也可以說偽分散式)。
應該檢查當前Pig版本是否支援你當前所用的Hadoop版本。某一版本的Pig僅支援特定版本的Hadoop,你可以通過訪問Pig官網獲取版本支援資訊。
Pig會用到HADOOP_HOME環境變數。如果該變數沒有設定,Pig也可以利用自帶的Hadoop庫,但是這樣就無法保證其自帶肯定庫和你實際使用的HADOOP版本是否相容,所以建議顯式設定HADOOP_HOME變數。且還需要設定如下變數:
下一步,需要告訴Pig它所用Hadoop叢集的Namenode和Jobtracker。一般情況下,正確安裝配置Hadoop後,這些配置資訊就已經可用了,不需要做額外的配置。
Pig預設模式是mapreduce,你也可以用以下命令進行設定:
pig –x mapreduce
執行Pig程式
Pig程式執行方式有三種:
1)指令碼方式
直接執行包含Pig指令碼的檔案,比如以下命令將執行本地scripts.pig檔案中的所有命令:
pig scripts.pig
2)Grunt方式
Grunt提供了互動式執行環境,可以在命令列編輯執行命令。
Grund同時支援命令的歷史記錄,通過上下方向鍵訪問。
Grund支援命令的自動補全功能。比如當你輸入a = foreach b g時,按下Tab鍵,則命令列自動變成a = foreach b generate。你甚至可以自定義命令自動補全功能的詳細方式。具體請參閱相關文件。
3)嵌入式方式
可以在java中執行Pig程式,類似於使用JDBC執行SQL程式。
Pig Latin編輯器
PigPen是一個Ecliipse外掛,它提供了在Eclipse中開發執行Pig程式的常用功能,比如指令碼編輯、執行等。下載地址:http://wiki.apache.org/pig/PigPen
其他一些編輯器也提供了編輯Pig指令碼的功能,比如vim等。
簡單示例
我們以查詢最高氣溫為例,演示如何利用Pig統計每年的最高氣溫。假設資料檔案內容如下(每行一個記錄,tab分割):
1990 21
1990 18
1991 21
1992 30
1992 999
1990 23
以local模式進入pig,依次輸入以下命令(注意以分號結束語句):
records = load ‘/home/user/input/temperature1.txt’ as (year: chararray,temperature: int);
dump records;
describe records;
valid_records = filter records by temperature!=999;
grouped_records = group valid_records by year;
dump grouped_records;
describe grouped_records;
max_temperature = foreach grouped_records generate group,MAX(valid_records.temperature);
--備註:valid_records是欄位名,在上一語句的describe命令結果中可以檢視到group_records 的具體結構。
dump max_temperature;
Pig的出現很好的彌補了這一不足。Pig能夠讓你專心於資料及業務本身,而不是糾結於資料的格式轉換以及MapReduce程式的編寫。本質是上來說,當你使用Pig進行處理時,Pig本身會在後臺生成一系列的MapReduce操作來執行任務,但是這個過程對使用者來說是透明的。
Pig的安裝
Pig作為客戶端程式執行,即使你準備在Hadoop叢集上使用Pig,你也不需要在叢集上做任何安裝。Pig從本地提交作業,並和Hadoop進行互動。
1)下載Pig
前往http://mirror.bit.edu.cn/apache/pig/ 下載合適的版本,比如Pig 0.12.0
2)解壓檔案到合適的目錄
tar –xzf pig-0.12.0
3)設定環境變數
export PIG_INSTALL=/opt/pig-0.12.0
export PATH=$PATH:$PIG_INSTALL/bin
如果沒有設定JAVA環境變數,此時還需要設定JAVA_HOME,比如:
export JAVA_HOME=/usr/lib/jvm/java-6-sun
4)驗證
執行以下命令,檢視Pig是否可用:
pig –help
Pig執行模式
Pig有兩種執行模式,分別為:
1)本地模式(Local)
本地模式下,Pig執行在單一的JVM中,可訪問本地檔案。該模式適用於處理小規模資料或學習之用。
執行以下命名設定為本地模式:
pig –x local
2)MapReduce模式
在MapReduce模式下,Pig將查詢轉換為MapReduce作業提交給Hadoop(可以說群集 ,也可以說偽分散式)。
應該檢查當前Pig版本是否支援你當前所用的Hadoop版本。某一版本的Pig僅支援特定版本的Hadoop,你可以通過訪問Pig官網獲取版本支援資訊。
Pig會用到HADOOP_HOME環境變數。如果該變數沒有設定,Pig也可以利用自帶的Hadoop庫,但是這樣就無法保證其自帶肯定庫和你實際使用的HADOOP版本是否相容,所以建議顯式設定HADOOP_HOME變數。且還需要設定如下變數:
export PIG_CLASSPATH=$HADOOP_HOME/etc/hadoop
下一步,需要告訴Pig它所用Hadoop叢集的Namenode和Jobtracker。一般情況下,正確安裝配置Hadoop後,這些配置資訊就已經可用了,不需要做額外的配置。
Pig預設模式是mapreduce,你也可以用以下命令進行設定:
pig –x mapreduce
執行Pig程式
Pig程式執行方式有三種:
1)指令碼方式
直接執行包含Pig指令碼的檔案,比如以下命令將執行本地scripts.pig檔案中的所有命令:
pig scripts.pig
2)Grunt方式
Grunt提供了互動式執行環境,可以在命令列編輯執行命令。
Grund同時支援命令的歷史記錄,通過上下方向鍵訪問。
Grund支援命令的自動補全功能。比如當你輸入a = foreach b g時,按下Tab鍵,則命令列自動變成a = foreach b generate。你甚至可以自定義命令自動補全功能的詳細方式。具體請參閱相關文件。
3)嵌入式方式
可以在java中執行Pig程式,類似於使用JDBC執行SQL程式。
Pig Latin編輯器
PigPen是一個Ecliipse外掛,它提供了在Eclipse中開發執行Pig程式的常用功能,比如指令碼編輯、執行等。下載地址:http://wiki.apache.org/pig/PigPen
其他一些編輯器也提供了編輯Pig指令碼的功能,比如vim等。
簡單示例
我們以查詢最高氣溫為例,演示如何利用Pig統計每年的最高氣溫。假設資料檔案內容如下(每行一個記錄,tab分割):
1990 21
1990 18
1991 21
1992 30
1992 999
1990 23
以local模式進入pig,依次輸入以下命令(注意以分號結束語句):
records = load ‘/home/user/input/temperature1.txt’ as (year: chararray,temperature: int);
dump records;
describe records;
valid_records = filter records by temperature!=999;
grouped_records = group valid_records by year;
dump grouped_records;
describe grouped_records;
max_temperature = foreach grouped_records generate group,MAX(valid_records.temperature);
--備註:valid_records是欄位名,在上一語句的describe命令結果中可以檢視到group_records 的具體結構。
dump max_temperature;
最終結果為:
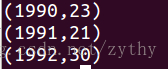
注意:
1)如果你執行Pig命令後報錯,且錯誤訊息中包含如下資訊:
WARN org.apache.pig.backend.hadoop20.PigJobControl- falling back to default JobControl (not using hadoop 0.20 ?)
java.lang.NoSuchFieldException:runnerState
則可能你的Pig版本和Hadoop版本不相容。此時可重新針對特定Hadoop版本進行編輯。下載原始碼後,進入原始碼根目錄,執行以下命令:
ant clean jar-withouthadoop-Dhadoopversion=23
注意:版本號是根據具體Hadoop而定,此處23可用於Hadoop2.2.0。
也可到以下網址下載:
(因為檔案太大,分成了3個壓縮包)
2)Pig同一時間只能工作在一種模式下,比如以MapReduce模式進入後,只能讀取HDFS檔案,如果此時你用load 讀取本地檔案,將會報錯。