
世界級的開源專案:TiDB 如何重新定義下一代關係型資料庫
在資料庫的平行世界裡,黃東旭以不同的方式在追隨著自己的內心。他認為,通常傳統的關係型資料庫無法滿足海量資料處理和分析時,新一輪的視窗期也隨之需求開啟,但是各類劣勢架構、記憶體架構、 NoSQL 等方案都不能滿足自己理想的解決方案,這些都不夠美,很少能夠把分散式事務與彈性擴充套件做到完美。
絕對的理性與感性,在黃東旭的身上看似矛盾,直到 2012 年底,他看到 Google 釋出的兩篇論文,如同稜鏡般,折射出他自己內心微爍的光彩。這兩篇論文描述了 Google 內部使用的一個海量關係型資料庫 F1/Spanner ,解決了關係型資料庫、彈性擴充套件以及全球分佈的問題,並在生產中大規模使用。“如果這個能實現,對資料儲存領域來說將是顛覆性的”,黃東旭為完美方案的出現而興奮, PingCAP 的 TiDB 在此基礎上誕生了。
當然,每向前進一步,都需要付出巨大的努力。在啟動 TiDB 專案之前,黃東旭先完成了一個開源分散式的 Redis 叢集方案 Codis ,這個專案完成以後讓他們覺得雖然快取的水平擴充套件問題有了解決方案,但是底層的關係型資料庫(主要是 MySQL 為主)並沒有一個優雅的擴充套件方案。業界除了在業務層分庫分表,或者使用中介軟體等折衷方案外,並沒有其他太多的辦法,有些業務可能能遷移到 NoSQL 之上,例如 HBase 、 C* 等,跟很多的業務沒法平滑遷移,幾乎需要重寫全部邏輯。如果採用分庫分表和中介軟體的方案,擴充套件以及高可用的方案會帶來大量額外的運維成本,比如無法使用跨 shard 的 join、子查詢、跨行事務等。
但是作為一個基礎軟體工程師的黃東旭他們不希望將這些複雜度轉嫁給業務層,所以就開始重新審視整個資料庫,希望從根本上解決 MySQL 的擴充套件問題,而不是再造一箇中間件。
“如果創造一個全新的東西,使它有一天能夠成為生產力,那種感覺真好!”
在 2012 、 2013 年期間,黃東旭他們就開始研究了Google 發表的一系列關於新一代分散式資料庫 Spanner 和 F1 的論文以及相關的學術界的進展,直到 2015 年,他們覺得基本所有的技術問題和架構都已經思考得差不多了,於是決定出來全職去重新開始完整的實現一個新的資料庫,也就是今天的主角——下一代開源 NewSQL 資料庫 TiDB 。
當然了,創造並不意味著開始,它需要面臨的是無限的投入和無限的博弈來適應網際網路的競爭和審視,真正做到讓開發者和企業受益,才是真正的開始。
TiDB在整體架構基本是參考 Google Spanner 和 F1 的設計,上分兩層為 TiDB 和 TiKV 。 TiDB 對應的是 Google F1, 是一層無狀態的 SQL Layer ,相容絕大多數 MySQL 語法,對外暴露 MySQL 網路協議,負責解析使用者的 SQL 語句,生成分散式的 Query Plan,翻譯成底層 Key Value 操作傳送給 TiKV , TiKV 是真正的儲存資料的地方,對應的是 Google Spanner ,是一個分散式 Key Value 資料庫,支援彈性水平擴充套件,自動的災難恢復和故障轉移(高可用),以及 ACID 跨行事務。值得一提的是 TiKV 並不像 HBase 或者 BigTable 那樣依賴底層的分散式檔案系統,在效能和靈活性上能更好,這個對於線上業務來說是非常重要。
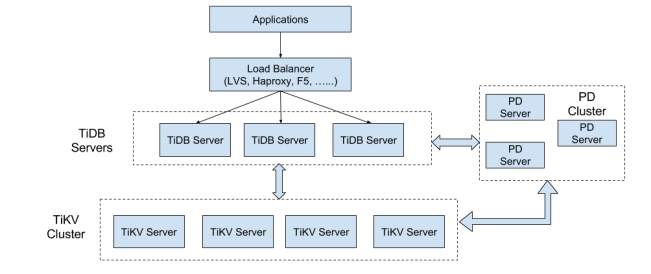
▲ TiDB 整體架構
這群理想很豐沛,這不被骨感現實所惑的人。在 TiDB 研發語言的選擇過程中,放棄了 Java 而採用 Go 。
TiDB整個專案分為兩層,TiDB 作為 SQL 層,採用 Go 語言開發, TiKV 作為下邊的分散式儲存引擎,採用 Rust 語言開發。在架構上確實類似 FoundationDB,也是基於兩層的結構。 FoundationDB 的 SQL Layer 採用 Java ,底層是 C++ ,不過在去年,被 Apple 收購了。
在選擇程式語言並沒有融入太多的個人喜好偏向, SQL 層選擇 Go 相對 Java 來說:
第一是 他們團隊的背景使用 Go 的開發效率更高,而且效能尚可,尤其對於高併發程式而言,可以使用 goroutine / channel 等工具用更少的程式碼寫出正確的程式;
第二是 在標準庫中很多包對網路程式開發非常友好,這個對於一個分散式系統來說非常重要;
第三是 在儲存引擎底層對於效能要求很高,Go 畢竟是一個帶有 GC 和 Runtime 的語言,在 TiKV 層可以選擇的方案並不多,過去基本只有 C 或 C++,不過近兩年隨著 Rust 語言的成熟,又在經過長時間的思考和大量實驗,最終他們團隊選擇了 Rust。
Rust 這門靜態語言的定位是取代 C++,最大的特點是通過很多語法的限制來避免開發者寫出記憶體洩露和 data race 的程式,將很多問題解決在編譯期,使得執行時不需要花費額外的代價進行 GC 之類的事情,保證高效能。所以,寫出安全的程式,這正是 C++ 程式的很大的一個痛點。
雖然在 C++ 11 中有了很多的改進,但是由於歷史包袱太重或者第三方包庫開發者的水平參差不齊。但是重要的原因不因為別的,正是他們的背後並不是一個 C++ 背景很深的團隊,所以最後放棄了 C++ 11 而選擇了 Rust 。
Rust 不僅有安全和高效能的特點,同時語法更加現代,開發效率更高,另外擁有非常完善的包管理機制(Cargo),使得在能寫出非常高效能且安全的程式同時,開發效率比起 Go並沒有下降太多,對於目前來說是一個非常正確的選擇。作為 Rust 社群內全球最大的開源專案之一,也得到了 Rust 語言官方團隊的很大支援,黃東旭表示,包括一些他們需要的第三方庫,Rust team 都會放在很高優先順序上去開發或者在社群裡推進。另外 Rust 早已釋出 1.0,語法也早已穩定,是一個非常有前途的系統程式語言。
輪番在Google中刷出了存在感後,還一直在沒有盡頭的草原上奔跑,黃東旭認為只有聚焦,專注,才能擺脫掉令人迷惑的干擾。在不斷的探索後,終於尋找到了實現事務模型的方式。
TiDB 的事務模型通過參考了 Google 的 Percolator。該論文發表於 2010 年,是描述 Google 在 BigTable 上的構建 ACID 跨行事務框架用於保證索引更新的一致性。演算法的核心思想是兩階段提交,但是傳統的分散式兩階段提交的問題是單點的事務管理器沒法擴充套件,會成為整個系統的瓶頸,Percolator 使用了一個兩級鎖的機制實現了去中心化的事務管理器,使得整個系統的可擴充套件性大大提升。
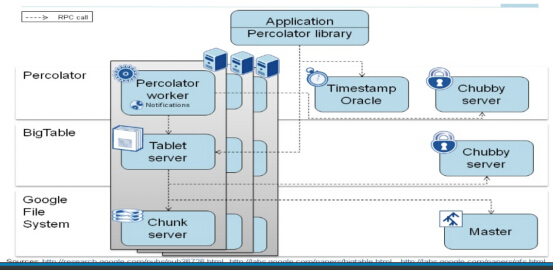
▲ Goolge Percolator內部實現
TiDB 將這個模型應用在底層的儲存引擎中,並做了很多工程上的優化,黃東旭舉例說,通過 batch 和 pipeline 等手段大大提升了授時服務的吞吐,使用 Raft + RockDB 來替代原文的 BigTable 效能更好,另外採用樂觀事務機制追求更高的吞吐,不過是從演算法層面,是 Percolator 實現。
TiDB 對比 NOSQL
TiDB 對於這些 NoSQL 來說,最大的特點是程式設計介面是 SQL,SQL對於開發者而言是更加靈活的操作資料庫的方式,且對 MySQL 有著極高的相容性—原業務的 MySQL切換到 TiDB 幾乎一行程式碼都不用修改就可以完成。TiDB 在支援 SQL 的同時有沒有喪失 HBase 這樣的系統的彈性擴充套件能力,業務層不需要再去關心資料庫的容量,不用去考慮分庫分表,也不用像過去那樣投入很大的運維力量,擴容只需簡單加機器就好,儲存節點故障對業務透明,而且資料庫本身具有自我修復的能力,保證資料不會丟失。
對於 MongoDB 也是一樣,更重要的是不需要改變使用者已有的習慣和程式,而且為了定義未來的雲上的資料庫形態,TiDB 設計的目標是單叢集需要可以 Scale 到 1000 以上物理節點的規模,支援 P 級別容量,萬億以上的行的結構化資料儲存,在這個前提約束下的設計和技術選型和 MongoDB 很不一樣,在大資料量的情況下 TiDB 的表現更穩定,擴充套件更加平滑。
TiDB 的 SQL 優化器是黃東旭他們從頭開始實現的一個面向分散式儲存設計的查詢優化器,使用了很多學術界很新的查詢優化技術和分散式計算框架的思想,保證 MySQL 相容性的前提下比 MySQL 在複雜查詢下表現要好得多。
傳統資料庫的痛點解決
任何企業,如果使用傳統的單機關係型資料庫,在資料量持續增長下,或者對業務的可用性有嚴格要求的情況下,可能都會面臨單點故障和單點容量限制的問題,這個問題最近幾年在網際網路行業尤其突出,目前來說除了上面提到的分庫分表和中介軟體也並沒有其他的方案解決,幾乎苦不堪言。
TiDB 基於更先進的 Raft 演算法來實現了儲存層的水平擴充套件基礎上加上了分散式事務,構建了完整的 SQL 查詢層,在保證不喪失 ACID 事務的前提下,支援 JOIN ,子查詢等複雜查詢,另外對外暴露 MySQL 介面,讓使用者幾乎在無侵入性的前提下,解決大量結構化資料的儲存問題。考慮到傳統行業和網際網路行業的代差大概在 3 年左右,另外這個時間在不斷的縮短,最近隨著 TiDB 趨於穩定,越來越多的網際網路在使用 TiDB ,相信未來會成為擴充套件資料庫的一個新的主流選擇。
TiDB 的應用場景
應用場景是典型的 OLTP 場景,範圍很大,覆蓋到任何企業。在關係型資料庫上遇到擴充套件性問題、同時需要強一致事務、需要實現多資料中心強一致和高可用,都是 TiDB 的典型使用者。TiDB 對 MySQL 的支援很完善,基於目前使用著 MySQL 的使用者或企業,希望尋求更優雅的水平擴充套件方案,都是非常不錯的選擇。
其實目前在統計大多數線上生產環境中使用的使用者基本都是網際網路場景,從 MySQL 過來。TiDB 目前暫時不支援儲存過程和檢視,所以前提條件是已有業務中沒有這類操作。
在專案開始第一天就確定了 TiDB 最大相容 MySQL ,黃東旭坦言, MySQL 是一個單機的資料庫,而且查詢優化器是針對單機場景設計,基於這架構上去做一個分散式資料庫的難度很大。
而此時,他們決定選擇一條更徹底的道路,就是重寫整個 SQL Parser 和查詢優化引擎。雖然看上去幾乎是不可能完成的事情,但是實際做下來他們覺得在一個更良好設計和複雜度控制下,反而是一條更輕鬆的路。而選擇完全的 MySQL 相容這個事情帶來的好處不僅限於對使用者的友好度,更重要的是能從 MySQL 社群吸取大量的測試。這對於一個數據庫產品來說,做出來並不難,如何證明你是對的,這才是更重要的!黃東旭他們不斷的從 MySQL 社群收集了千萬級的測試用例來保證每個模組的正確性,和對 MySQL 行為的一致性。
TiDB 專案開源的程度
TiDB 專案是100% 開源,致力於做一個具有國際水準的頂級開源專案,從 Github repo 本身其實很難看出來這是一個背後是國人主導的開源專案,所有的提交記錄,所有的協作,Roadmap ,Issue tracking ,中英文文件,以及程式碼稽核都是開源的。
而專案已經迭代到 Beta 4 版本,從線上使用者的反饋,主要的功能已經基本完善穩定。黃東旭表示,接下來重要的工作會是持續的效能優化和繼續提升穩定性,還有在更大容量,更惡劣嚴苛的叢集環境下持續測試。當然周邊工具,部署教程,更多的設計文件也是在持續的豐富中。
TiDB 的未來
從更長遠的角度,一切東西都會執行在雲端,資料庫也不例外。在海量資料,大規模叢集的前提下,關係型資料庫的設計和理論還有很多東西需要探索,這種叢集規模之下,一切依賴人工的運維都將會失效,因為人是沒法 scale ,資料庫需要具有自我修復和自我擴充套件的能力,也只有這樣,才能更好的利用叢集的計算資源,這也為什麼 TiDB 團隊對自己的定位是要做 Cloud-Native 的資料庫,他們在為未來做很多基礎性的研究和準備,包含對 Kubernetes 和分散式資料庫的結合上也做了很多探索性的工作。
黃東旭希望 TiDB 定義下一代關係型資料庫,未來開發者能夠真正專注自己的業務,不用在關心資料庫有多大,併發可能會有多高,什麼時候需要擴容一下,選哪個 sharding key 好等這些問題都應該被隱藏在一個很簡單的 SQL interface 之下。
TiDB 有了非常不錯的開頭,他們做到了,在下一代關係型資料庫裡面,每個人都能感受到這種技術所帶來生產力的美好!