
15 | 答疑文章(一):日誌和索引相關問題
在今天這篇答疑文章更新前,MySQL實戰這個專欄已經更新了14篇。在這些文章中,大家在評論區留下了很多高質量的留言。現在,每篇文章的評論區都有熱心的同學幫忙總結文章知識點,也有不少同學提出了很多高質量的問題,更有一些同學幫忙解答其他同學提出的問題。
在瀏覽這些留言並回復的過程中,我倍受鼓舞,也盡我所知地幫助你解決問題、和你討論。可以說,你們的留言活躍了整個專欄的氛圍、提升了整個專欄的質量,謝謝你們。
評論區的大多數留言我都直接回復了,對於需要展開說明的問題,我都拿出小本子記了下來。這些被記下來的問題,就是我們今天這篇答疑文章的素材了。
到目前為止,我已經收集了47個問題,很難通過今天這一篇文章全部展開。所以,我就先從中找了幾個聯系非常緊密的問題,串了起來,希望可以幫你解決關於日誌和索引的一些疑惑。而其他問題,我們就留著後面慢慢展開吧。
日誌相關問題
我在第2篇文章《日誌系統:一條SQL更新語句是如何執行的?》中,和你講到binlog(歸檔日誌)和redo log(重做日誌)配合崩潰恢復的時候,用的是反證法,說明了如果沒有兩階段提交,會導致MySQL出現主備數據不一致等問題。
在這篇文章下面,很多同學在問,在兩階段提交的不同瞬間,MySQL如果發生異常重啟,是怎麽保證數據完整性的?
現在,我們就從這個問題開始吧。
我再放一次兩階段提交的圖,方便你學習下面的內容。
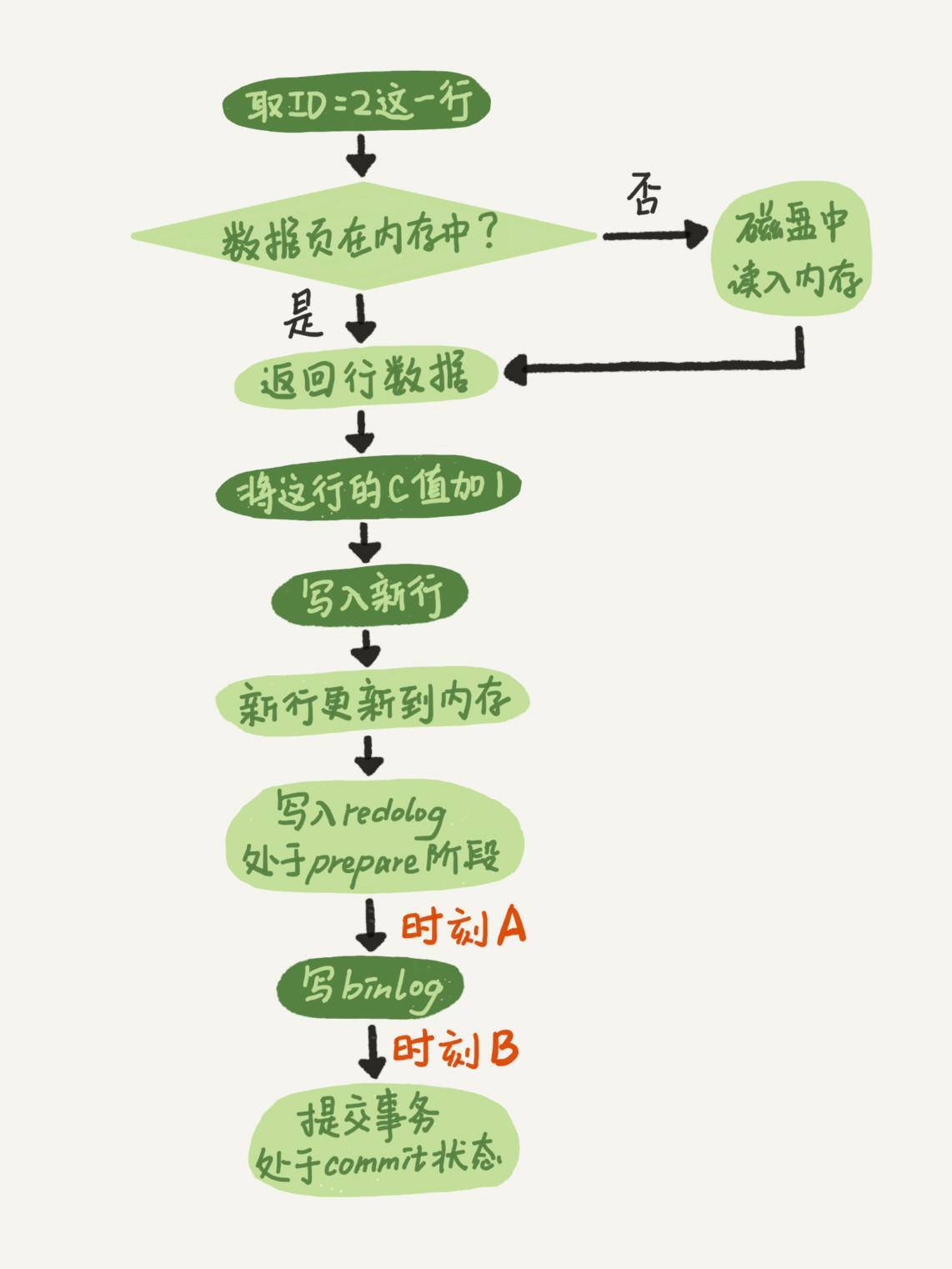
這裏,我要先和你解釋一個誤會式的問題。有同學在評論區問到,這個圖不是一個update語句的執行流程嗎,怎麽還會調用commit語句?
他產生這個疑問的原因,是把兩個“commit”的概念
- 他說的“commit語句”,是指MySQL語法中,用於提交一個事務的命令。一般跟begin/start transaction 配對使用。
- 而我們圖中用到的這個“commit步驟”,指的是事務提交過程中的一個小步驟,也是最後一步。當這個步驟執行完成後,這個事務就提交完成了。
- “commit語句”執行的時候,會包含“commit 步驟”。
而我們這個例子裏面,沒有顯式地開啟事務,因此這個update語句自己就是一個事務,在執行完成後提交事務時,就會用到這個“commit步驟“。
接下來,我們就一起分析一下在兩階段提交的不同時刻,MySQL異常重啟會出現什麽現象。
如果在圖中時刻A的地方,也就是寫入redo log 處於prepare階段之後、寫binlog之前,發生了崩潰(crash),由於此時binlog還沒寫,redo log也還沒提交,所以崩潰恢復的時候,這個事務會回滾。這時候,binlog還沒寫,所以也不會傳到備庫。到這裏,大家都可以理解。
大家出現問題的地方,主要集中在時刻B,也就是binlog寫完,redo log還沒commit前發生crash,那崩潰恢復的時候MySQL會怎麽處理?
我們先來看一下崩潰恢復時的判斷規則。
-
如果redo log裏面的事務是完整的,也就是已經有了commit標識,則直接提交;
-
如果redo log裏面的事務只有完整的prepare,則判斷對應的事務binlog是否存在並完整:
a. 如果是,則提交事務;
b. 否則,回滾事務。
這裏,時刻B發生crash對應的就是2(a)的情況,崩潰恢復過程中事務會被提交。
現在,我們繼續延展一下這個問題。
追問1:MySQL怎麽知道binlog是完整的?
回答:一個事務的binlog是有完整格式的:
- statement格式的binlog,最後會有COMMIT;
- row格式的binlog,最後會有一個XID event。
另外,在MySQL 5.6.2版本以後,還引入了binlog-checksum參數,用來驗證binlog內容的正確性。對於binlog日誌由於磁盤原因,可能會在日誌中間出錯的情況,MySQL可以通過校驗checksum的結果來發現。所以,MySQL還是有辦法驗證事務binlog的完整性的。
追問2:redo log 和 binlog是怎麽關聯起來的?
回答:它們有一個共同的數據字段,叫XID。崩潰恢復的時候,會按順序掃描redo log:
- 如果碰到既有prepare、又有commit的redo log,就直接提交;
- 如果碰到只有parepare、而沒有commit的redo log,就拿著XID去binlog找對應的事務。
追問3:處於prepare階段的redo log加上完整binlog,重啟就能恢復,MySQL為什麽要這麽設計?
回答:其實,這個問題還是跟我們在反證法中說到的數據與備份的一致性有關。在時刻B,也就是binlog寫完以後MySQL發生崩潰,這時候binlog已經寫入了,之後就會被從庫(或者用這個binlog恢復出來的庫)使用。
所以,在主庫上也要提交這個事務。采用這個策略,主庫和備庫的數據就保證了一致性。
追問4:如果這樣的話,為什麽還要兩階段提交呢?幹脆先redo log寫完,再寫binlog。崩潰恢復的時候,必須得兩個日誌都完整才可以。是不是一樣的邏輯?
回答:其實,兩階段提交是經典的分布式系統問題,並不是MySQL獨有的。
如果必須要舉一個場景,來說明這麽做的必要性的話,那就是事務的持久性問題。
對於InnoDB引擎來說,如果redo log提交完成了,事務就不能回滾(如果這還允許回滾,就可能覆蓋掉別的事務的更新)。而如果redo log直接提交,然後binlog寫入的時候失敗,InnoDB又回滾不了,數據和binlog日誌又不一致了。
兩階段提交就是為了給所有人一個機會,當每個人都說“我ok”的時候,再一起提交。
追問5:不引入兩個日誌,也就沒有兩階段提交的必要了。只用binlog來支持崩潰恢復,又能支持歸檔,不就可以了?
回答:這位同學的意思是,只保留binlog,然後可以把提交流程改成這樣:… -> “數據更新到內存” -> “寫 binlog” -> “提交事務”,是不是也可以提供崩潰恢復的能力?
答案是不可以。
如果說歷史原因的話,那就是InnoDB並不是MySQL的原生存儲引擎。MySQL的原生引擎是MyISAM,設計之初就有沒有支持崩潰恢復。
InnoDB在作為MySQL的插件加入MySQL引擎家族之前,就已經是一個提供了崩潰恢復和事務支持的引擎了。
InnoDB接入了MySQL後,發現既然binlog沒有崩潰恢復的能力,那就用InnoDB原有的redo log好了。
而如果說實現上的原因的話,就有很多了。就按照問題中說的,只用binlog來實現崩潰恢復的流程,我畫了一張示意圖,這裏就沒有redo log了。
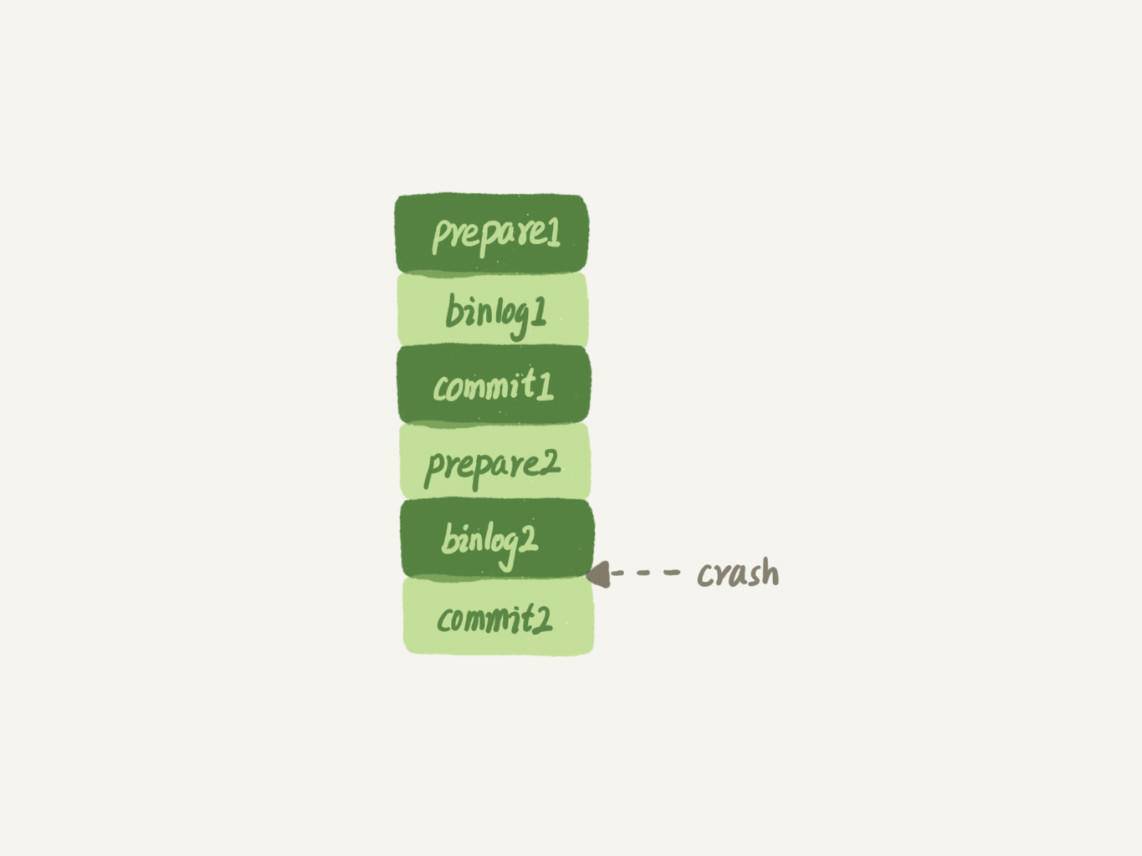
這樣的流程下,binlog還是不能支持崩潰恢復的。我說一個不支持的點吧:binlog沒有能力恢復“數據頁”。
如果在圖中標的位置,也就是binlog2寫完了,但是整個事務還沒有commit的時候,MySQL發生了crash。
重啟後,引擎內部事務2會回滾,然後應用binlog2可以補回來;但是對於事務1來說,系統已經認為提交完成了,不會再應用一次binlog1。
但是,InnoDB引擎使用的是WAL技術,執行事務的時候,寫完內存和日誌,事務就算完成了。如果之後崩潰,要依賴於日誌來恢復數據頁。
也就是說在圖中這個位置發生崩潰的話,事務1也是可能丟失了的,而且是數據頁級的丟失。此時,binlog裏面並沒有記錄數據頁的更新細節,是補不回來的。
你如果要說,那我優化一下binlog的內容,讓它來記錄數據頁的更改可以嗎?但,這其實就是又做了一個redo log出來。
所以,至少現在的binlog能力,還不能支持崩潰恢復。
追問6:那能不能反過來,只用redo log,不要binlog?
回答:如果只從崩潰恢復的角度來講是可以的。你可以把binlog關掉,這樣就沒有兩階段提交了,但系統依然是crash-safe的。
但是,如果你了解一下業界各個公司的使用場景的話,就會發現在正式的生產庫上,binlog都是開著的。因為binlog有著redo log無法替代的功能。
一個是歸檔。redo log是循環寫,寫到末尾是要回到開頭繼續寫的。這樣歷史日誌沒法保留,redo log也就起不到歸檔的作用。
一個就是MySQL系統依賴於binlog。binlog作為MySQL一開始就有的功能,被用在了很多地方。其中,MySQL系統高可用的基礎,就是binlog復制。
還有很多公司有異構系統(比如一些數據分析系統),這些系統就靠消費MySQL的binlog來更新自己的數據。關掉binlog的話,這些下遊系統就沒法輸入了。
總之,由於現在包括MySQL高可用在內的很多系統機制都依賴於binlog,所以“鳩占鵲巢”redo log還做不到。你看,發展生態是多麽重要。
追問7:redo log一般設置多大?
回答:redo log太小的話,會導致很快就被寫滿,然後不得不強行刷redo log,這樣WAL機制的能力就發揮不出來了。
所以,如果是現在常見的幾個TB的磁盤的話,就不要太小氣了,直接將redo log設置為4個文件、每個文件1GB吧。
追問8:正常運行中的實例,數據寫入後的最終落盤,是從redo log更新過來的還是從buffer pool更新過來的呢?
回答:這個問題其實問得非常好。這裏涉及到了,“redo log裏面到底是什麽”的問題。
實際上,redo log並沒有記錄數據頁的完整數據,所以它並沒有能力自己去更新磁盤數據頁,也就不存在“數據最終落盤,是由redo log更新過去”的情況。
-
如果是正常運行的實例的話,數據頁被修改以後,跟磁盤的數據頁不一致,稱為臟頁。最終數據落盤,就是把內存中的數據頁寫盤。這個過程,甚至與redo log毫無關系。
-
在崩潰恢復場景中,InnoDB如果判斷到一個數據頁可能在崩潰恢復的時候丟失了更新,就會將它讀到內存,然後讓redo log更新內存內容。更新完成後,內存頁變成臟頁,就回到了第一種情況的狀態。
追問9:redo log buffer是什麽?是先修改內存,還是先寫redo log文件?
回答:這兩個問題可以一起回答。
在一個事務的更新過程中,日誌是要寫多次的。比如下面這個事務:
begin;
insert into t1 ...
insert into t2 ...
commit;
這個事務要往兩個表中插入記錄,插入數據的過程中,生成的日誌都得先保存起來,但又不能在還沒commit的時候就直接寫到redo log文件裏。
所以,redo log buffer就是一塊內存,用來先存redo日誌的。也就是說,在執行第一個insert的時候,數據的內存被修改了,redo log buffer也寫入了日誌。
但是,真正把日誌寫到redo log文件(文件名是 ib_logfile+數字),是在執行commit語句的時候做的。
(這裏說的是事務執行過程中不會“主動去刷盤”,以減少不必要的IO消耗。但是可能會出現“被動寫入磁盤”,比如內存不夠、其他事務提交等情況。這個問題我們會在後面第22篇文章《MySQL有哪些“飲鴆止渴”的提高性能的方法?》中再詳細展開)。
單獨執行一個更新語句的時候,InnoDB會自己啟動一個事務,在語句執行完成的時候提交。過程跟上面是一樣的,只不過是“壓縮”到了一個語句裏面完成。
以上這些問題,就是把大家提過的關於redo log和binlog的問題串起來,做的一次集中回答。如果你還有問題,可以在評論區繼續留言補充。
業務設計問題
接下來,我再和你分享@ithunter 同學在第8篇文章《事務到底是隔離的還是不隔離的?》的評論區提到的跟索引相關的一個問題。我覺得這個問題挺有趣、也挺實用的,其他同學也可能會碰上這樣的場景,在這裏解答和分享一下。
問題是這樣的(我文字上稍微做了點修改,方便大家理解):
業務上有這樣的需求,A、B兩個用戶,如果互相關註,則成為好友。設計上是有兩張表,一個是like表,一個是friend表,like表有user_id、liker_id兩個字段,我設置為復合唯一索引即uk_user_id_liker_id。語句執行邏輯是這樣的:
以A關註B為例:
第一步,先查詢對方有沒有關註自己(B有沒有關註A)
select * from like where user_id = B and liker_id = A;
如果有,則成為好友
insert into friend;
沒有,則只是單向關註關系
insert into like;
但是如果A、B同時關註對方,會出現不會成為好友的情況。因為上面第1步,雙方都沒關註對方。第1步即使使用了排他鎖也不行,因為記錄不存在,行鎖無法生效。請問這種情況,在MySQL鎖層面有沒有辦法處理?
首先,我要先贊一下這樣的提問方式。雖然極客時間現在的評論區還不能追加評論,但如果大家能夠一次留言就把問題講清楚的話,其實影響也不大。所以,我希望你在留言提問的時候,也能借鑒這種方式。
接下來,我把@ithunter 同學說的表模擬出來,方便我們討論。
CREATE TABLE `like` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`liker_id` int(11) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `uk_user_id_liker_id` (`user_id`,`liker_id`)
) ENGINE=InnoDB;
CREATE TABLE `friend` (
id` int(11) NOT NULL AUTO_INCREMENT,
`friend_1_id` int(11) NOT NULL,
`firned_2_id` int(11) NOT NULL,
UNIQUE KEY `uk_friend` (`friend_1_id`,`firned_2_id`)
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
雖然這個題幹中,並沒有說到friend表的索引結構。但我猜測friend_1_id和friend_2_id也有索引,為便於描述,我給加上唯一索引。
順便說明一下,“like”是關鍵字,我一般不建議使用關鍵字作為庫名、表名、字段名或索引名。
我把他的疑問翻譯一下,在並發場景下,同時有兩個人,設置為關註對方,就可能導致無法成功加為朋友關系。
現在,我用你已經熟悉的時刻順序表的形式,把這兩個事務的執行語句列出來:

由於一開始A和B之間沒有關註關系,所以兩個事務裏面的select語句查出來的結果都是空。
因此,session 1的邏輯就是“既然B沒有關註A,那就只插入一個單向關註關系”。session 2也同樣是這個邏輯。
這個結果對業務來說就是bug了。因為在業務設定裏面,這兩個邏輯都執行完成以後,是應該在friend表裏面插入一行記錄的。
如提問裏面說的,“第1步即使使用了排他鎖也不行,因為記錄不存在,行鎖無法生效”。不過,我想到了另外一個方法,來解決這個問題。
首先,要給“like”表增加一個字段,比如叫作 relation_ship,並設為整型,取值1、2、3。
值是1的時候,表示user_id 關註 liker_id;
值是2的時候,表示liker_id 關註 user_id;
值是3的時候,表示互相關註。
然後,當 A關註B的時候,邏輯改成如下所示的樣子:
應用代碼裏面,比較A和B的大小,如果A<B,就執行下面的邏輯
mysql> begin; /*啟動事務*/
insert into `like`(user_id, liker_id, relation_ship) values(A, B, 1) on duplicate key update relation_ship=relation_ship | 1;
select relation_ship from `like` where user_id=A and liker_id=B;
/*代碼中判斷返回的 relation_ship,
如果是1,事務結束,執行 commit
如果是3,則執行下面這兩個語句:
*/
insert ignore into friend(friend_1_id, friend_2_id) values(A,B);
commit;
如果A>B,則執行下面的邏輯
mysql> begin; /*啟動事務*/
insert into `like`(user_id, liker_id, relation_ship) values(B, A, 2) on duplicate key update relation_ship=relation_ship | 2;
select relation_ship from `like` where user_id=B and liker_id=A;
/*代碼中判斷返回的 relation_ship,
如果是2,事務結束,執行 commit
如果是3,則執行下面這兩個語句:
*/
insert ignore into friend(friend_1_id, friend_2_id) values(B,A);
commit;
這個設計裏,讓“like”表裏的數據保證user_id < liker_id,這樣不論是A關註B,還是B關註A,在操作“like”表的時候,如果反向的關系已經存在,就會出現行鎖沖突。
然後,insert … on duplicate語句,確保了在事務內部,執行了這個SQL語句後,就強行占住了這個行鎖,之後的select 判斷relation_ship這個邏輯時就確保了是在行鎖保護下的讀操作。
操作符 “|” 是按位或,連同最後一句insert語句裏的ignore,是為了保證重復調用時的冪等性。
這樣,即使在雙方“同時”執行關註操作,最終數據庫裏的結果,也是like表裏面有一條關於A和B的記錄,而且relation_ship的值是3, 並且friend表裏面也有了A和B的這條記錄。
不知道你會不會吐槽:之前明明還說盡量不要使用唯一索引,結果這個例子一上來我就創建了兩個。這裏我要再和你說明一下,之前文章我們討論的,是在“業務開發保證不會插入重復記錄”的情況下,著重要解決性能問題的時候,才建議盡量使用普通索引。
而像這個例子裏,按照這個設計,業務根本就是保證“我一定會插入重復數據,數據庫一定要要有唯一性約束”,這時就沒啥好說的了,唯一索引建起來吧。
小結
這是專欄的第一篇答疑文章。
我針對前14篇文章,大家在評論區中的留言,從中摘取了關於日誌和索引的相關問題,串成了今天這篇文章。這裏我也要再和你說一聲,有些我答應在答疑文章中進行擴展的話題,今天這篇文章沒來得及擴展,後續我會再找機會為你解答。所以,篇幅所限,評論區見吧。
最後,雖然這篇是答疑文章,但課後問題還是要有的。
我們創建了一個簡單的表t,並插入一行,然後對這一行做修改。
mysql> CREATE TABLE `t` (
`id` int(11) NOT NULL primary key auto_increment,
`a` int(11) DEFAULT NULL
) ENGINE=InnoDB;
insert into t values(1,2);
這時候,表t裏有唯一的一行數據(1,2)。假設,我現在要執行:
mysql> update t set a=2 where id=1;
你會看到這樣的結果:

結果顯示,匹配(rows matched)了一行,修改(Changed)了0行。
僅從現象上看,MySQL內部在處理這個命令的時候,可以有以下三種選擇:
-
更新都是先讀後寫的,MySQL讀出數據,發現a的值本來就是2,不更新,直接返回,執行結束;
-
MySQL調用了InnoDB引擎提供的“修改為(1,2)”這個接口,但是引擎發現值與原來相同,不更新,直接返回;
-
InnoDB認真執行了“把這個值修改成(1,2)"這個操作,該加鎖的加鎖,該更新的更新。
你覺得實際情況會是以上哪種呢?你可否用構造實驗的方式,來證明你的結論?進一步地,可以思考一下,MySQL為什麽要選擇這種策略呢?
你可以把你的驗證方法和思考寫在留言區裏,我會在下一篇文章的末尾和你討論這個問題。感謝你的收聽,也歡迎你把這篇文章分享給更多的朋友一起閱讀。
上期問題時間
上期的問題是,用一個計數表記錄一個業務表的總行數,在往業務表插入數據的時候,需要給計數值加1。
邏輯實現上是啟動一個事務,執行兩個語句:
-
insert into 數據表;
-
update 計數表,計數值加1。
從系統並發能力的角度考慮,怎麽安排這兩個語句的順序。
這裏,我直接復制 @阿建 的回答過來供你參考:
並發系統性能的角度考慮,應該先插入操作記錄,再更新計數表。
知識點在《行鎖功過:怎麽減少行鎖對性能的影響?》
因為更新計數表涉及到行鎖的競爭,先插入再更新能最大程度地減少事務之間的鎖等待,提升並發度。
評論區有同學說,應該把update計數表放後面,因為這個計數表可能保存了多個業務表的計數值。如果把update計數表放到事務的第一個語句,多個業務表同時插入數據的話,等待時間會更長。
這個答案的結論是對的,但是理解不太正確。即使我們用一個計數表記錄多個業務表的行數,也肯定會給表名字段加唯一索引。類似於下面這樣的表結構:
CREATE TABLE `rows_stat` (
`table_name` varchar(64) NOT NULL,
`row_count` int(10) unsigned NOT NULL,
PRIMARY KEY (`table_name`)
) ENGINE=InnoDB;
在更新計數表的時候,一定會傳入where table_name=$table_name,使用主鍵索引,更新加行鎖只會鎖在一行上。
而在不同業務表插入數據,是更新不同的行,不會有行鎖。
15 | 答疑文章(一):日誌和索引相關問題