
自定義InputFormat
阿新 • • 發佈:2019-01-24
程式程式碼如下:
package inputformat; import java.io.DataInput; import java.io.DataOutput; import java.io.FileInputStream; import java.io.IOException; import java.net.URI; import java.util.ArrayList; import java.util.List; import java.util.Random; import mapreduce.WordCountApp; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.ArrayWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.io.Writable; import org.apache.hadoop.mapreduce.InputFormat; import org.apache.hadoop.mapreduce.InputSplit; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.JobContext; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.RecordReader; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.TaskAttemptContext; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; /** * 資料來源來自於記憶體 */ public class MyselInputFormatApp { private static final String OUT_PATH = "hdfs://chaoren1:9000/out"; public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); final FileSystem filesystem = FileSystem.get(new URI(OUT_PATH), conf); filesystem.delete(new Path(OUT_PATH), true); final Job job = new Job(conf , WordCountApp.class.getSimpleName()); job.setJarByClass(WordCountApp.class); job.setInputFormatClass(MyselfMemoryInputFormat.class); job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(LongWritable.class); job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(LongWritable.class); FileOutputFormat.setOutputPath(job, new Path(OUT_PATH)); job.waitForCompletion(true); } public static class MyMapper extends Mapper<NullWritable, Text, Text, LongWritable>{ protected void map(NullWritable key, Text value, org.apache.hadoop.mapreduce.Mapper<NullWritable,Text,Text,LongWritable>.Context context) throws java.io.IOException ,InterruptedException { final String line = value.toString(); final String[] splited = line.split("\t"); for (String word : splited) { //在for迴圈體內,臨時變數word的出現次數是常量1 context.write(new Text(word), new LongWritable(1)); } }; } //map產生的<k,v>分發到reduce的過程稱作shuffle public static class MyReducer extends Reducer<Text, LongWritable, Text, LongWritable>{ protected void reduce(Text key, java.lang.Iterable<LongWritable> values, org.apache.hadoop.mapreduce.Reducer<Text,LongWritable,Text,LongWritable>.Context context) throws java.io.IOException ,InterruptedException { //count表示單詞key在整個檔案中的出現次數 long count = 0L; for (LongWritable times : values) { count += times.get(); } context.write(key, new LongWritable(count)); }; } /** * 從記憶體中產生資料,然後解析成一個個的鍵值對 * */ public static class MyselfMemoryInputFormat extends InputFormat<NullWritable, Text>{ @Override public List<InputSplit> getSplits(JobContext context) throws IOException, InterruptedException { final ArrayList<InputSplit> result = new ArrayList<InputSplit>(); result.add(new MemoryInputSplit()); result.add(new MemoryInputSplit()); result.add(new MemoryInputSplit()); return result; } @Override public RecordReader<NullWritable, Text> createRecordReader( InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { return new MemoryRecordReader(); } } public static class MemoryInputSplit extends InputSplit implements Writable{ final int SIZE = 10; final ArrayWritable arrayWritable = new ArrayWritable(Text.class); /** * 先建立一個java陣列型別,然後轉化為hadoop的陣列型別 */ public MemoryInputSplit() { Text[] array = new Text[SIZE]; final Random random = new Random(); for (int i = 0; i < SIZE; i++) { final int nextInt = random.nextInt(999999); final Text text = new Text("Text"+nextInt); array[i] = text; } arrayWritable.set(array); } @Override public long getLength() throws IOException, InterruptedException { return SIZE; } @Override public String[] getLocations() throws IOException, InterruptedException { return new String[] {"localhost"}; } public ArrayWritable getValues() { return arrayWritable; } @Override public void write(DataOutput out) throws IOException { arrayWritable.write(out); } @Override public void readFields(DataInput in) throws IOException { arrayWritable.readFields(in); } } public static class MemoryRecordReader extends RecordReader<NullWritable, Text>{ Writable[] values = null; Text value = null; int i = 0; @Override public void initialize(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException { MemoryInputSplit inputSplit = (MemoryInputSplit)split; ArrayWritable writables = inputSplit.getValues(); this.values = writables.get(); this.i = 0; } @Override public boolean nextKeyValue() throws IOException, InterruptedException { if(i>=values.length) { return false; } if(this.value==null) { this.value = new Text(); } this.value.set((Text)values[i]); i++; return true; } @Override public NullWritable getCurrentKey() throws IOException, InterruptedException { return NullWritable.get(); } @Override public Text getCurrentValue() throws IOException, InterruptedException { return value; } @Override public float getProgress() throws IOException, InterruptedException { return 0; } @Override public void close() throws IOException { } } }
總結:
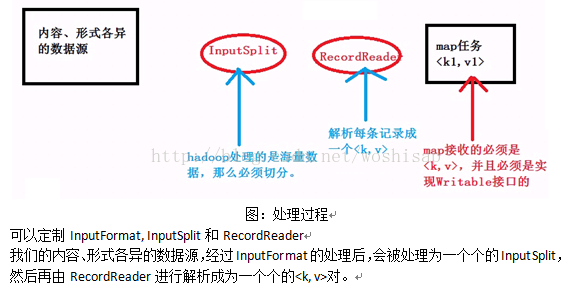
1.InputFormat是用於處理各種資料來源的。下面實現自定義的InputFormat,資料來源是來自於記憶體。
1.1 在程式的job.setInputFormatClass(MySelfInputFormat.class);
1.2 實現InputFormat extends InputFormat<k,v>,實現其中的2個方法,分別是getSplits(..)和createRecordReader(..)
1.3 getSplits(...)返回的是java.util.List<T>,裡面中的每個元素是InputSplit。每個InputSpilt對應一個mapper任務。
1.4 InputSplit是對原始海量資料來源的劃分。本例中是在記憶體中產生資料,封裝到InputSplit中。
1.5 InputSplit封裝的必須是hadoop資料型別,實現Writable介面。
1.6 RecordReader讀取每個InputSplit中的資料,解析成一個個的<k,v>,供map處理。
1.7 RecordReader有4個核心方法,分別是initialize(...),nextKeyValue(),getCurrentKey()和getCurrentValue()。
1.8 initialize(...)的重要性在於拿到InputSplit和定義臨時變數。
1.9 nextKeyValue(...)方法的每次呼叫可以獲得key和value值
1.10 當nextKeyValue(...)呼叫後,緊接著呼叫getCurrentKey()和getCurrentValue()。