
過濾CString字串中各位是數字,大小寫字母,符號,漢字
UNICODE編碼下(萬國碼、國際碼、統一碼、單一碼,雙位元組字符集編碼)
UINT GetCharacterType (CString str = _T("")) { UINT iType = 0; // 字串的型別 UINT iLen = 0; // 檢視字串strDemo的長度 CString strDemo = L"0123abcABC_雲中鶴+-*ほニホ呵呵00"; if (str.GetLength()>0) { strDemo = str; } CString shuzi = _T (""); CString biaodianfuhao = _T (""); CString hanzi = _T (""); CString daxiezimu = _T (""); CString xiaoxiezimu = _T (""); for(; iLen < strDemo.GetLength (); iLen++) { int unicode = (int) strDemo.GetAt (iLen); if(unicode <= 0x39 && unicode >= 0x30) { shuzi += strDemo.GetAt (iLen); } else if(unicode <= 0x7A && unicode >= 0x61) { xiaoxiezimu += strDemo.GetAt (iLen); } else if(unicode <= 0x5A && unicode >= 0x41) { daxiezimu += strDemo.GetAt (iLen); } else if(unicode > 0xFF) { // 255 hanzi += strDemo.GetAt (iLen); } else { biaodianfuhao += strDemo.GetAt (iLen); } } if(shuzi.GetLength () > 0) { iType |= 0x000001; } if(biaodianfuhao.GetLength () > 0) { iType |= 0x000010; } if(hanzi.GetLength () > 0) { iType |= 0x000100; } if(daxiezimu.GetLength () > 0) { iType |= 0x001000; } if(xiaoxiezimu.GetLength () > 0) { iType |= 0x010000; } return iType; } void Test () { GetCharacterType (); }
MBCS編碼下(Multi-byte character set多位元組字符集編碼)
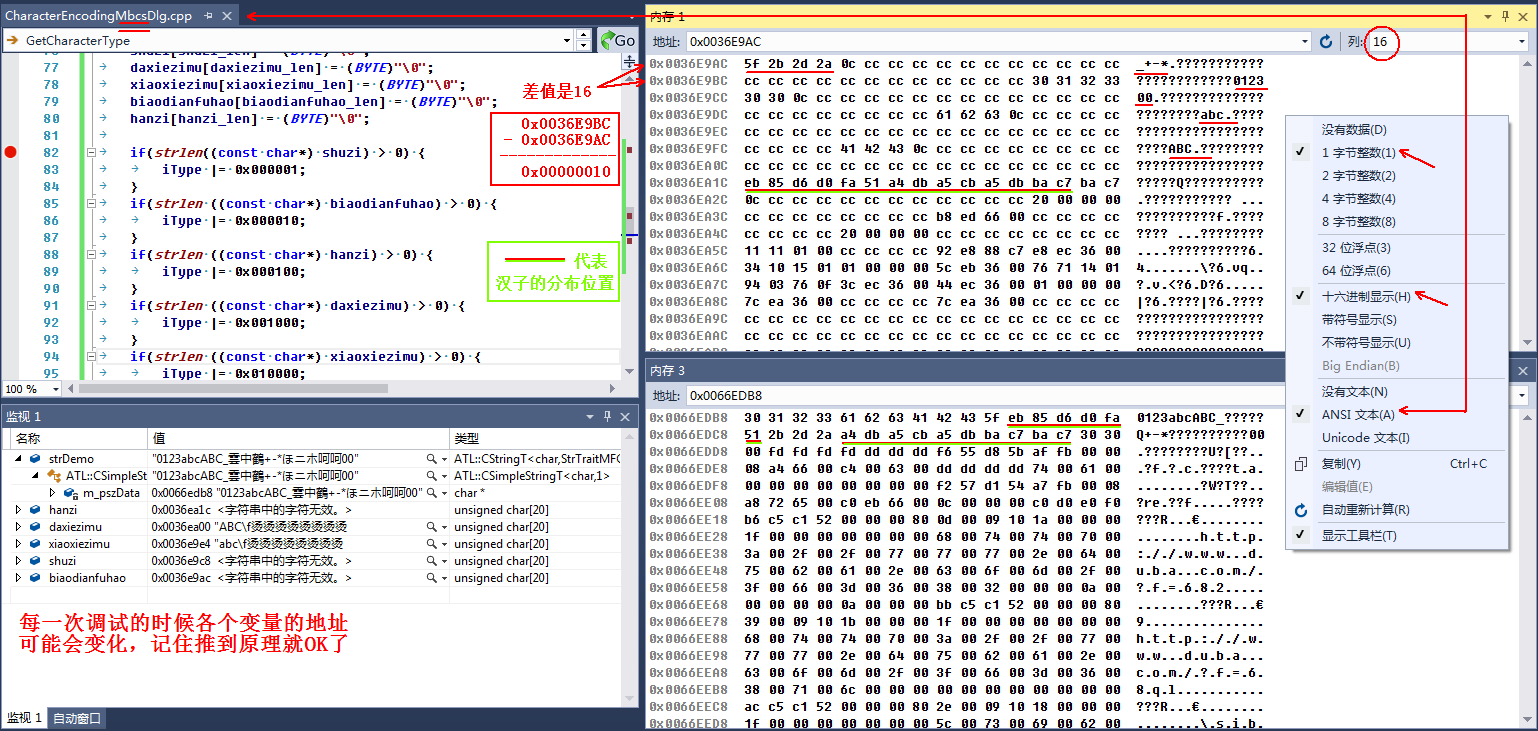
UINT GetCharacterType (CString str = _T ("")) { UINT iType = 0; // 字串的型別 UINT iLen = 0; // 檢視字串strDemo的長度 CString strDemo = "0123abcABC_雲中鶴+-*ほニホ呵呵00"; if(str.GetLength () > 0) { strDemo = str; } UINT lens; lens = (int) strlen (strDemo); unsigned char hanzi[20]; // Chinese characters;Japanese characters unsigned char daxiezimu[20]; // upper case letter unsigned char xiaoxiezimu[20]; // lower case letter unsigned char shuzi[20]; // number unsigned char biaodianfuhao[20]; // Expression symbol unsigned char ansi; int hanzi_len = 0; int daxiezimu_len = 0; int xiaoxiezimu_len = 0; int shuzi_len = 0; int biaodianfuhao_len = 0; for(; iLen < lens; iLen++) { ansi = strDemo[iLen]; if(ansi <= 0x39 && ansi >= 0x30) { shuzi[shuzi_len++] = ansi; } else if(ansi <= 0x7A && ansi >= 0x61) { xiaoxiezimu[xiaoxiezimu_len++] = ansi; } else if(ansi <= 0x5A && ansi >= 0x41) { daxiezimu[daxiezimu_len++] = ansi; } else if(ansi > 0x7F) { // 127 hanzi[hanzi_len++] = ansi; hanzi[hanzi_len++] = strDemo[++iLen]; } else { biaodianfuhao[biaodianfuhao_len++] = ansi; } } shuzi[shuzi_len] = (BYTE)"\0"; daxiezimu[daxiezimu_len] = (BYTE)"\0"; xiaoxiezimu[xiaoxiezimu_len] = (BYTE)"\0"; biaodianfuhao[biaodianfuhao_len] = (BYTE)"\0"; hanzi[hanzi_len] = (BYTE)"\0"; if(strlen((const char*) shuzi) > 0) { iType |= 0x000001; } if(strlen ((const char*) biaodianfuhao) > 0) { iType |= 0x000010; } if(strlen ((const char*) hanzi) > 0) { iType |= 0x000100; } if(strlen ((const char*) daxiezimu) > 0) { iType |= 0x001000; } if(strlen ((const char*) xiaoxiezimu) > 0) { iType |= 0x010000; } return iType; } void Test () { GetCharacterType (); }
多位元組字符集除錯資訊
ASCII標準表
| Bin(二進位制) | Oct(八進位制) | Dec(十進位制) | Hex(十六進位制) | 縮寫/字元 | 解釋 |
| 0000 0000 | 0 | 0 | 00 | NUL(null) | 空字元 |
| 0000 0001 | 1 | 1 | 01 | SOH(start of headline) | 標題開始 |
| 0000 0010 | 2 | 2 | 02 | STX (start of text) | 正文開始 |
| 0000 0011 | 3 | 3 | 03 | ETX (end of text) | 正文結束 |
| 0000 0100 | 4 | 4 | 04 | EOT (end of transmission) | 傳輸結束 |
| 0000 0101 | 5 | 5 | 05 | ENQ (enquiry) | 請求 |
| 0000 0110 | 6 | 6 | 06 | ACK (acknowledge) | 收到通知 |
| 0000 0111 | 7 | 7 | 07 | BEL (bell) | 響鈴 |
| 0000 1000 | 10 | 8 | 08 | BS (backspace) | 退格 |
| 0000 1001 | 11 | 9 | 09 | HT (horizontal tab) | 水平製表符 |
| 0000 1010 | 12 | 10 | 0A | LF (NL line feed, new line) | 換行鍵 |
| 0000 1011 | 13 | 11 | 0B | VT (vertical tab) | 垂直製表符 |
| 0000 1100 | 14 | 12 | 0C | FF (NP form feed, new page) | 換頁鍵 |
| 0000 1101 | 15 | 13 | 0D | CR (carriage return) | 回車鍵 |
| 0000 1110 | 16 | 14 | 0E | SO (shift out) | 不用切換 |
| 0000 1111 | 17 | 15 | 0F | SI (shift in) | 啟用切換 |
| 0001 0000 | 20 | 16 | 10 | DLE (data link escape) | 資料鏈路轉義 |
| 0001 0001 | 21 | 17 | 11 | DC1 (device control 1) | 裝置控制1 |
| 0001 0010 | 22 | 18 | 12 | DC2 (device control 2) | 裝置控制2 |
| 0001 0011 | 23 | 19 | 13 | DC3 (device control 3) | 裝置控制3 |
| 0001 0100 | 24 | 20 | 14 | DC4 (device control 4) | 裝置控制4 |
| 0001 0101 | 25 | 21 | 15 | NAK (negative acknowledge) | 拒絕接收 |
| 0001 0110 | 26 | 22 | 16 | SYN (synchronous idle) | 同步空閒 |
| 0001 0111 | 27 | 23 | 17 | ETB (end of trans. block) | 結束傳輸塊 |
| 0001 1000 | 30 | 24 | 18 | CAN (cancel) | 取消 |
| 0001 1001 | 31 | 25 | 19 | EM (end of medium) | 媒介結束 |
| 0001 1010 | 32 | 26 | 1A | SUB (substitute) | 代替 |
| 0001 1011 | 33 | 27 | 1B | ESC (escape) | 換碼(溢位) |
| 0001 1100 | 34 | 28 | 1C | FS (file separator) | 檔案分隔符 |
| 0001 1101 | 35 | 29 | 1D | GS (group separator) | 分組符 |
| 0001 1110 | 36 | 30 | 1E | RS (record separator) | 記錄分隔符 |
| 0001 1111 | 37 | 31 | 1F | US (unit separator) | 單元分隔符 |
| 0010 0000 | 40 | 32 | 20 | (space) | 空格 |
| 0010 0001 | 41 | 33 | 21 | ! | 歎號 |
| 0010 0010 | 42 | 34 | 22 |
相關推薦過濾CString字串中各位是數字,大小寫字母,符號,漢字UNICODE編碼下(萬國碼、國際碼、統一碼、單一碼,雙位元組字符集編碼) UINT GetCharacterType (CString str = _T("")) { UINT iType = 0; // 字串的型別 UINT iLen = 0; // 檢視 華為面試題:請編寫一個字串壓縮程式,將字串中連續出席的重複字母進行壓縮,並輸出壓縮後的字串。#include<iostream> #include<stdio.h> #include<cstring> using namespace std; //void stringZip(const char *pInputStr, long lInputLen, char CString字串中數字的提取假設CString型別的字串“192.168.1.1” void main() { CString str = "192.168.1.1"; int a,b,c,d; int pos; pos = str.Find('.'); CStr 給出字串分別計算出字串中數字、大小寫字母的個數。(兩種方法 getBytes( ) charAt( ) )public class LetterAndNumberCount { public static void main(String[] args) { Count("FJJgjsgfsd543632"); count1("SFsefgdg2354354fsdf" Python 計算字串中所有數字的和,如:'12abc34de5f' => 12 + 34 + 5 => 51Python 計算字串中所有數字的和,如:‘12abc34de5f’ => 12 + 34 + 5 => 51 解題思路: 可以把不是數字的元素轉換成’ '空格, 然後按空格切割成列表, 把列表中的數字元素找出相加 最後返回 s = '12abc34de5f' def sum Python練習題2:提取列表中的所有數字,包括字串中的數字 target = ['25',5,'a',1,2,'b',4,5,'A','python','3.6']方法一:使用type(eval())函式判斷型別,再用try-except-else處理異常 1 def num_trans(): 2 """使用eval()函式判斷""" 3 target = ['25',5,'a',1,2,'b',4,5,'A','python','3.6' #計算字串中所有數字和,連續當一個數字 (正則表示式,能不用就不用)s='12as3d6f20ads01sd02' import re def he(s): c=re.compile('\d+')#建立正則表示式 l=c.findall(s)#返回所有匹配結果的列表 sum=0 #和 for i in l: #遍歷 如何從CString型別的字串中取出數字LRESULT CMainDlg::OnOK(WORD /*wNotifyCode*/, WORD wID, HWND /*hWndCtl*/, BOOL& /*bHandled*/){// TODO: Add validation code CString strDate ="abcd 判斷字串中的數字是否相同,連續最近幾天在寫pin code和指紋登入功能,一直沒有時間總結技術,今天終於有點時間了。 我們的pin code的規則如下圖所示: 先說一下我對這個問題的解決思路: 我們先進行判重,怎麼進行判重呢,首先我們需要把字串中的數字切割成單獨的數字,放入到陣列中, MySQL:字串中的數字、英文字元、漢字提取原文:https://blog.csdn.net/oyezhou/article/details/81665643 另外一篇類似的:https://blog.csdn.net/haijiege/article/details/79460236 建立一個Num_char_ 解決 Order By 將字串型別的數字 或 字串中含數字 按數字排序問題oracle資料庫,欄位是varchar2型別即string,而其實存的是數字,這時候不加處理的order by的排序結果,肯定有問題 解決辦法: & 輸入字符串,包含數字,大小寫字母,編程輸出出現做多的數字的和數字 字母 十進制數 println code key generated 分離 其他 題目描述: 輸入字符串,包含數字,大小寫字母,編程輸出出現做多的數字的和。 思路: 1.創建輸入對象2.輸入字符串3.利用正則將字母分離出,剩余的每一個字符串即為待統計的每一個數字 PHP去掉字串中的數字這個比較簡單,但是也有些需要注意的地方,先貼程式碼 $class=preg_replace("\\d+",'', $res); 需要使用preg_replace函式,但是隻是這麼寫的話,會報錯 Warning: preg_replace(): Delimiter must not be python提取字串中的數字字串儲存在string.txt中,將字串中的數字提取出來,組成心得字串,並列印輸出。 #!/usr/bin/env python3 file=open('/home/user/string.txt') file_context=file.read() i=0 string='' wh 將字串中的數字轉化為文字String ids = "1,2,3"; String[] industryIdsArr = ids.split(","); String str = ""; if (industryIdsArr != null && industryIdsArr.length Java中對字串中的數字進行求和運算字串中的數字進行求和 1 public class StringDemo { 2 3 public static void main(String[] args) { 4 // TODO Auto-generated method stub 5 Python 提取字串中的數字方法*正則表示式. re.findall >>> import re >>> str1="this book is 99 yuan 8" >>> a=re.findall(r'\d',str1) #在字串中找到正則表示式所匹配的所 請實現一個函式,將一個字串中的每個空格替換成指定符號。題目描述 請實現一個函式,將一個字串中的每個空格替換成“%20”。例如,當字串為We Are Happy.則經過替換之後的字串為We%20Are%20Happy。 /* 思路:從前向後記錄‘ ’數目,從後向前替換‘ ’。 重點:從後向前替換的時候的技巧 例如:“we are lucky” shell正則提取字串中的數字並儲存到變數中1.提取數字到變數 temp = `echo "helloworld20181212 | tr -cd "[0-9]""` echo ${temp} 2.釋義tr -cd "[0-9]" tr是translate的縮寫,主要用於刪除檔案中的控制字元,或者進行字元轉換 &n java 劍指offer 第二題:請實現一個函式,將一個字串中的空格替換成“%20”。例如,當字串為We Are Happy.則經過替換之後的字串為We%20Are%20Happy。** public class Solution { public String replaceSpace(StringBuffer str) { 首先程式給出的引數是StringBuffer類,那麼我首先考慮的是就呼叫StringBuffer類的相關方法完成操作。 |