
Hadoop,MapReduce,HDFS面試題
今天發這個的目的是為了給自己掃開迷茫,告訴自己該進階了,以下內容不一定官方和正確,完全個人理解,歡迎大家留言討論
1.什麼是hadoop
答:是google的核心演算法MapReduce的一個開源實現。用於海量資料的並行處理。
hadoop的核心主要包含:HDFS和MapReduce
HDFS是分散式檔案系統,用於分散式儲存海量資料。
MapReduce是分散式資料處理模型,本質是並行處理。
2.用hadoop來做什麼?
1、最簡單的,做個數據備份/檔案歸檔的地方,這利用了hadoop海量資料的儲存能力
2、資料倉庫/資料探勘:分析web日誌,分析使用者的行為(如:使用者使用搜索時,在搜尋結果中點選第2頁的概率有多大)
3、搜尋引擎:設計hadoop的初衷,就是為了快速建立索引。
4、雲端計算:據說,中國移動的大雲,就是基於hadoop的
5、研究:hadoop的本質就是分散式計算,又是開源的。有很多思想值得借鑑。
3.什麼是MapReduce,它是怎麼工作的
MapReduce借用了函數語言程式設計的概念,是google發明的一種用分散式來處理大資料集的資料處理模型
[這也是和SQL資料庫重大區別之一,用函式程式設計(MapReduce)代替宣告查詢SQL。
SQL:宣告查詢結果,讓資料庫引擎判定獲取資料。
MapReduce:資料處理步驟由你自己制定(指令碼,程式碼)eg:複雜的資料統計模型,或改變影象資料格式]
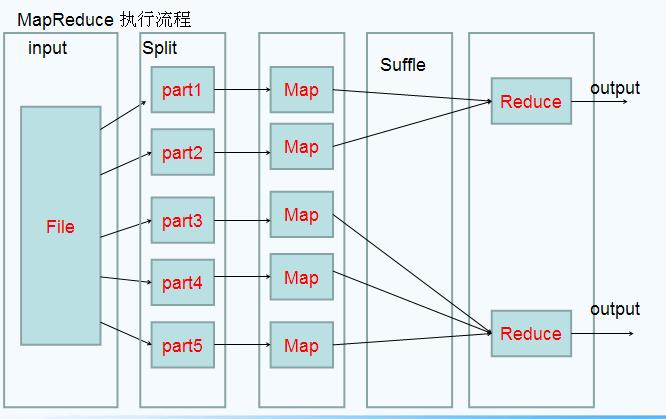
工作流程:
1、client提交資料到DFS,然後被分為多個split,然後通過inputformatter以key-value傳給jobTraker,jobTraker分配工作給多個map(taskTraker),工程師重寫map,在各個taskTraker上分別執行程式碼任務,做到資料不動,程式碼動(改革之一)。真正實現程式碼分散式。
2、tasktraker執行完程式碼後,將結果通過上下文收集起來,再傳給reduce(也是taskTraker),經過排序等操作,再執行工程師重寫的reduce方法,最終將結果通過outputFormatter寫到DFS。
4.什麼是HDFS,它的儲存機制?
HDFS(Hadoop Distributed File System)是Hadoop專案的核心子專案,是分散式計算中資料儲存管理的基礎,坦白說HDFS是一個不錯的分散式檔案系統,它有很多的優點,但也存在有一些缺點,包括:不適合低延遲資料訪問、無法高效儲存大量小檔案、不支援多使用者寫入及任意修改檔案。
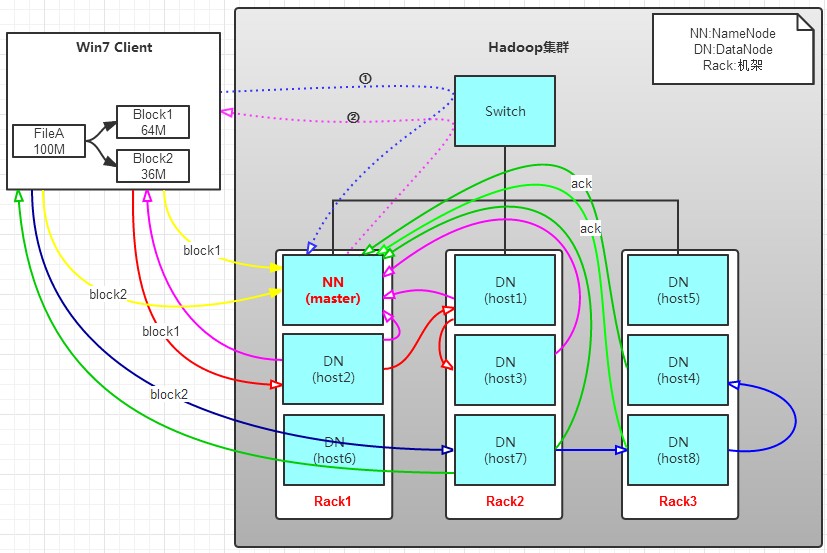
有一個檔案FileA,100M大小。Client將FileA寫入到HDFS上。
HDFS按預設配置。
HDFS分佈在三個機架上Rack1,Rack2,Rack3。
a. Client將FileA按64M分塊。分成兩塊,block1和Block2;
b. Client向nameNode傳送寫資料請求,如圖藍色虛線①——>。
c. NameNode節點,記錄block資訊。並返回可用的DataNode,如粉色虛線②———>。
Block1: host2,host1,host3
Block2: host7,host8,host4
原理:
NameNode具有RackAware機架感知功能,這個可以配置。
若client為DataNode節點,那儲存block時,規則為:副本1,同client的節點上;副本2,不同機架節點上;
副本3,同第二個副本機架的另一個節點上;其他副本隨機挑選。
若client不為DataNode節點,那儲存block時,規則為:副本1,隨機選擇一個節點上;副本2,不同副本1,機架上;
副本3,同副本2相同的另一個節點上;其他副本隨機挑選。
d. client向DataNode傳送block1;傳送過程是以流式寫入。
流式寫入過程,
1>將64M的block1按64k的package劃分;
2>然後將第一個package傳送給host2;
3>host2接收完後,將第一個package傳送給host1,同時client想host2傳送第二個package;
4>host1接收完第一個package後,傳送給host3,同時接收host2發來的第二個package。
5>以此類推,如圖紅線實線所示,直到將block1傳送完畢。
6>host2,host1,host3向NameNode,host2向Client傳送通知,說“訊息傳送完了”。如圖粉紅顏色實線所示。
7>client收到host2發來的訊息後,向namenode傳送訊息,說我寫完了。這樣就真完成了。如圖黃色粗實線
8>傳送完block1後,再向host7,host8,host4傳送block2,如圖藍色實線所示。
9>傳送完block2後,host7,host8,host4向NameNode,host7向Client傳送通知,如圖淺綠色實線所示。
10>client向NameNode傳送訊息,說我寫完了,如圖黃色粗實線。。。這樣就完畢了。
分析,通過寫過程,我們可以瞭解到:
①寫1T檔案,我們需要3T的儲存,3T的網路流量貸款。
②在執行讀或寫的過程中,NameNode和DataNode通過HeartBeat進行儲存通訊,確定DataNode活著。
如果發現DataNode死掉了,就將死掉的DataNode上的資料,放到其他節點去。讀取時,要讀其他節點去。
③掛掉一個節點,沒關係,還有其他節點可以備份;甚至,掛掉某一個機架,也沒關係;其他機架上,也有備份。
以後是通過原始碼分析,和程式碼經驗來慢慢加深這些概念的理解鞏固他們,歡迎大家常駐,一起學習。