
SPARK RDD JAVA API 用法指南
1.RDD介紹:
RDD,彈性分散式資料集,即分散式的元素集合。在spark中,對所有資料的操作不外乎是建立RDD、轉化已有的RDD以及呼叫RDD操作進行求值。在這一切的背後,Spark會自動將RDD中的資料分發到叢集中,並將操作並行化。
Spark中的RDD就是一個不可變的分散式物件集合。每個RDD都被分為多個分割槽,這些分割槽執行在叢集中的不同節點上。RDD可以包含Python,Java,Scala中任意型別的物件,甚至可以包含使用者自定義的物件。
使用者可以使用兩種方法建立RDD:讀取一個外部資料集,或在驅動器程式中分發驅動器程式中的物件集合,比如list或者set。
RDD的轉化操作都是惰性求值的,這意味著我們對RDD呼叫轉化操作,操作不會立即執行。相反,Spark會在內部記錄下所要求執行的操作的相關資訊。我們不應該把RDD看做存放著特定資料的資料集,而最好把每個RDD當做我們通過轉化操作構建出來的、記錄如何計算資料的指令列表。資料讀取到RDD中的操作也是惰性的,資料只會在必要時讀取。轉化操作和讀取操作都有可能多次執行。
2.建立RDD資料集
(1)讀取一個外部資料集
JavaRDD<String> lines=sc.textFile(inputFile);
(2)分發物件集合,這裡以list為例
List<String> list=new ArrayList<String>();
list.add("a");
list.add("b");
list.add("c");
JavaRDD<String> temp=sc.parallelize(list);
//上述方式等價於
JavaRDD<String> temp2=sc.parallelize(Arrays.asList
3.RDD操作
(1)轉化操作
用java實現過濾器轉化操作:
List<String> list=new ArrayList<String>();
//建立列表,列表中包含以下自定義表項
list.add("error:a");
list.add("error:b");
list.add("error:c");
list.add("warning:d");
list.add("hadppy ending!");
//將列表轉換為RDD物件
JavaRDD<String> lines = sc.parallelize(list);
//將RDD物件lines中有error的表項過濾出來,放在RDD物件errorLines中
JavaRDD<String> errorLines = lines.filter(
new Function<String, Boolean>() {
public Boolean call(String v1) throws Exception {
return v1.contains("error");
}
}
);
//遍歷過濾出來的列表項
List<String> errorList = errorLines.collect();
for (String line : errorList)
System.out
輸出:
error:a
error:b
error:c
可見,列表list中包含詞語error的表項都被正確的過濾出來了。
(2)合併操作
將兩個RDD資料集合併為一個RDD資料集
接上述程式示例:
union
輸出:
error:a
error:b
error:c
warning:d
可見,將原始列表項中的所有error項和warning項都過濾出來了。
(3)獲取RDD資料集中的部分或者全部元素
①獲取RDD資料集中的部分元素 .take(int num) 返回值List<T>
獲取RDD資料集中的前num項。
/** * Take the first num elements of the RDD. This currently scans the partitions *one by one*, so * it will be slow if a lot of partitions are required. In that case, use collect() to get the * whole RDD instead. */ def take(num: Int): JList[T]
程式示例:接上
JavaRDD<String> unionLines=errorLines.union(warningLines);
for(String line :unionLines.take(2))
System.out.println(line);
輸出:
error:a
error:b
可見,輸出了RDD資料集unionLines的前2項
②獲取RDD資料集中的全部元素 .collect() 返回值 List<T>
程式示例:
List<String> unions=unionLines.collect();
for(String line :unions)
System.out.println(line);
遍歷輸出RDD資料集unions的每一項
4.向spark傳遞函式
|
函式名 |
實現的方法 |
用途 |
|
Function<T,R> |
R call(T) |
接收一個輸入值並返回一個輸出值,用於類似map()和filter()的操作中 |
| Function<T1,T2,R> |
R call(T1,T2) |
接收兩個輸入值並返回一個輸出值,用於類似aggregate()和fold()等操作中 |
| FlatMapFunction<T,R> |
Iterable <R> call(T) |
接收一個輸入值並返回任意個輸出,用於類似flatMap()這樣的操作中 |
①Function<T,R>
JavaRDD<String> errorLines=lines.filter(
new Function<String, Boolean>() {
public Boolean call(String v1)throws Exception {
return v1.contains("error");
}
}
);
過濾RDD資料集中包含error的表項,新建RDD資料集errorLines
②FlatMapFunction<T,R>
List<String> strLine=new ArrayList<String>();
strLine.add("how are you");
strLine.add("I am ok");
strLine.add("do you love me")
JavaRDD<String> input=sc.parallelize(strLine);
JavaRDD<String> words=input.flatMap(
new FlatMapFunction<String, String>() {
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(s.split(" "));
}
}
);
將文字行的單詞過濾出來,並將所有的單詞儲存在RDD資料集words中。
③ Function<T1,T2,R>
List<String> strLine=new ArrayList<String>();
strLine.add("how are you");
strLine.add("I am ok");
strLine.add("do you love me");
JavaRDD<String> input=sc.parallelize(strLine);
JavaRDD<String> words=input.flatMap(
new FlatMapFunction<String, String>() {
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(s.split(" "));
}
}
);
JavaPairRDD<String,Integer> counts=words.mapToPair(
new PairFunction<String, String, Integer>() {
public Tuple2<String, Integer> call(String s) throws Exception {
return new Tuple2(s, 1);
}
}
);
JavaPairRDD <String,Integer> results=counts.reduceByKey(
new org.apache.spark.api.java.function.Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
}
) ;
上述程式是spark中的wordcount實現方式,其中的reduceByKey操作的Function2函式定義了遇到相同的key時,value是如何reduce的->直接將兩者的value相加。
*注意:
可以將我們的函式類定義為使用匿名內部類,就像上述程式實現的那樣,也可以建立一個具名類,就像這樣:
class ContainError implements Function<String,Boolean>{
public Boolean call(String v1) throws Exception {
return v1.contains("error");
}
}
JavaRDD<String> errorLines=lines.filter(new ContainError());
for(String line :errorLines.collect())
System.out.println(line);
具名類也可以有引數,就像上述過濾出含有”error“的表項,我們可以自定義到底含有哪個詞語,就像這樣,程式就更有普適性了。
5.針對每個元素的轉化操作:
轉化操作map()接收一個函式,把這個函式用於RDD中的每個元素,將函式的返回結果作為結果RDD中對應的元素。關鍵詞:轉化
轉化操作filter()接受一個函式,並將RDD中滿足該函式的元素放入新的RDD中返回。關鍵詞:過濾
示例圖如下所示:
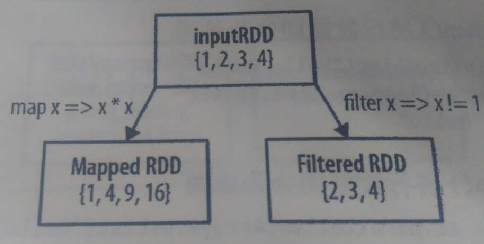
①map()
計算RDD中各值的平方
JavaRDD<Integer> rdd =sc.parallelize(Arrays.asList(1,2,3,4));
JavaRDD<Integer> result=rdd.map(
new Function<Integer, Integer>() {
public Integer call(Integer v1) throwsException {
return v1*v1;
}
}
);
System.out.println( StringUtils.join(result.collect(),","));
輸出:
1,4,9,16
filter()
② 去除RDD集合中值為1的元素:
JavaRDD<Integer> rdd =sc.parallelize(Arrays.asList(1,2,3,4));
JavaRDD<Integer> results=rdd.filter(
new Function<Integer, Boolean>() {
public Boolean call(Integer v1) throws Exception {
return v1!=1;
}
}
);
System.out.println(StringUtils.join(results.collect(),","));
結果:
2,3,4
③ 有時候,我們希望對每個輸入元素生成多個輸出元素。實現該功能的操作叫做flatMap()。和map()類似,我們提供給flatMap()的函式被分別應用到了輸入的RDD的每個元素上。不過返回的不是一個元素,而是一個返回值序列的迭代器。輸出的RDD倒不是由迭代器組成的。我們得到的是一個包含各個迭代器可以訪問的所有元素的RDD。flatMap()的一個簡單用途是將輸入的字串切分成單詞,如下所示:
JavaRDD<String> rdd =sc.parallelize(Arrays.asList("hello world","hello you","world i love you"));
JavaRDD<String> words=rdd.flatMap(
new FlatMapFunction<String, String>() {
public Iterable<String> call(String s) throws Exception {
return Arrays.asList(s.split(" "));
}
}
);
System.out.println(StringUtils.join(words.collect(),'\n'));
輸出:
hello
world
hello
you
world
i
love
you
6.集合操作
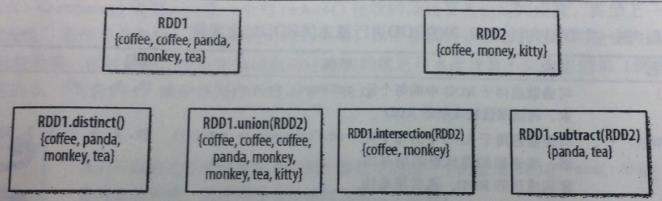
RDD中的集合操作
|
函式 |
用途 |
|
RDD1.distinct() |
生成一個只包含不同元素的新RDD。需要資料混洗。 |
|
RDD1.union(RDD2) |
返回一個包含兩個RDD中所有元素的RDD |
|
RDD1.intersection(RDD2) |
只返回兩個RDD中都有的元素 |
|
RDD1.substr(RDD2) |
返回一個只存在於第一個RDD而不存在於第二個RDD中的所有元素組成的RDD。需要資料混洗。 |
集合操作對笛卡爾集的處理:
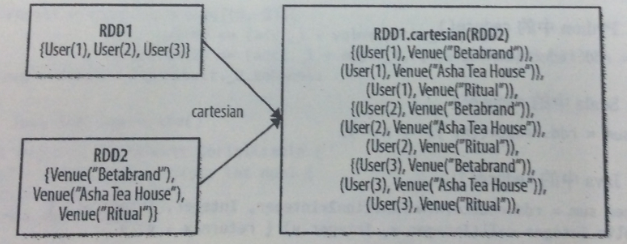
|
RDD1.cartesian(RDD2) |
返回兩個RDD資料集的笛卡爾集 |
程式示例:生成RDD集合{1,2} 和{1,2}的笛卡爾集
JavaRDD<Integer> rdd1 = sc.parallelize(Arrays.asList(1,2));
JavaRDD<Integer> rdd2 = sc.parallelize(Arrays.asList(1,2));
JavaPairRDD<Integer ,Integer> rdd=rdd1.cartesian(rdd2);
for(Tuple2<Integer,Integer> tuple:rdd.collect())
System.out.println(tuple._1()+"->"+tuple._2());
輸出:
1->1
1->2
2->1
2->2
7.行動操作
(1)reduce操作
reduce()接收一個函式作為引數,這個函式要操作兩個RDD的元素型別的資料並返回一個同樣型別的新元素。一個簡單的例子就是函式+,可以用它來對我們的RDD進行累加。使用reduce(),可以很方便地計算出RDD中所有元素的總和,元素的個數,以及其他型別的聚合操作。
以下是求RDD資料集所有元素和的程式示例:
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1,2,3,4,5,6,7,8,9,10));
Integer sum =rdd.reduce(
new Function2<Integer, Integer, Integer>() {
public Integercall(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
}
);
System.out.println(sum.intValue());
輸出:55
(2)fold()操作
接收一個與reduce()接收的函式簽名相同的函式,再加上一個初始值來作為每個分割槽第一次呼叫時的結果。你所提供的初始值應當是你提供的操作的單位元素,也就是說,使用你的函式對這個初始值進行多次計算不會改變結果(例如+對應的0,*對應的1,或者拼接操作對應的空列表)。
程式例項:
①計算RDD資料集中所有元素的和:
zeroValue=0;//求和時,初始值為0。
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1,2,3,4,5,6,7,8,9,10));
Integer sum =rdd.fold(0,
new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
}
);
System.out.println(sum);
②計算RDD資料集中所有元素的積:
zeroValue=1;//求積時,初始值為1。
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1,2,3,4,5,6,7,8,9,10));
Integer result =rdd.fold(1,
new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1*v2;
}
}
);
System.out.println(result);
(3)aggregate()操作
aggregate()函式返回值型別不必與所操作的RDD型別相同。
與fold()類似,使用aggregate()時,需要提供我們期待返回的型別的初始值。然後通過一個函式把RDD中的元素合併起來放入累加器。考慮到每個節點是在本地進行累加的,最終,還需要提供第二個函式來將累加器兩兩合併。
以下是程式例項:
public class AvgCount implements Serializable{
public int total;
public int num;
public AvgCount(int total,int num){
this.total=total;
this.num=num;
}
public double avg(){
return total/(double)num;
}
static Function2<AvgCount,Integer,AvgCount> addAndCount=
new Function2<AvgCount, Integer, AvgCount>() {
public AvgCount call(AvgCount a, Integer x) throws Exception {
a.total+=x;
a.num+=1;
return a;
}
};
static Function2<AvgCount,AvgCount,AvgCount> combine=
new Function2<AvgCount, AvgCount, AvgCount>() {
public AvgCount call(AvgCount a, AvgCount b) throws Exception {
a.total+=b.total;
a.num+=b.num;
return a;
}
};
public static void main(String args[]){
SparkConf conf = new SparkConf().setMaster("local").setAppName("my app");
JavaSparkContext sc = new JavaSparkContext(conf);
AvgCount intial =new AvgCount(0,0);
JavaRDD<Integer> rdd =sc.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6));
AvgCount result=rdd.aggregate(intial,addAndCount,combine);
System.out.println(result.avg());
}
}
這個程式示例可以實現求出RDD物件集的平均數的功能。其中addAndCount將RDD物件集中的元素合併起來放入AvgCount物件之中,combine提供兩個AvgCount物件的合併的實現。我們初始化AvgCount(0,0),表示有0個物件,物件的和為0,最終返回的result物件中total中儲存了所有元素的和,num儲存了元素的個數,這樣呼叫result物件的函式avg()就能夠返回最終所需的平均數,即avg=tatal/(double)num。
8.持久化快取
因為Spark RDD是惰性求值的,而有時我們希望能多次使用同一個RDD。如果簡單地對RDD呼叫行動操作,Spark每次都會重算RDD以及它的所有依賴。這在迭代演算法中消耗格外大,因為迭代演算法常常會多次使用同一組資料。
為了避免多次計算同一個RDD,可以讓Spark對資料進行持久化。當我們讓Spark持久化儲存一個RDD時,計算出RDD的節點會分別儲存它們所求出的分割槽資料。
出於不同的目的,我們可以為RDD選擇不同的持久化級別。預設情況下persist()會把資料以序列化的形式快取在JVM的堆空間中
不同關鍵字對應的儲存級別表
| 級別 |
使用的空間 |
cpu時間 |
是否在記憶體 |
是否在磁碟 |
備註 |
|
MEMORY_ONLY |
高 |
低 |
是 |
否 |
直接儲存在記憶體 |
| MEMORY_ONLY_SER |
低 |
高 |
是 |
否 |
序列化後儲存在記憶體裡 |
|
MEMORY_AND_DISK |
低 |
中等 |
部分 |
部分 |
如果資料在記憶體中放不下,溢寫在磁碟上 |
|
MEMORY_AND_DISK_SER |
低 |
高 |
部分 |
部分 |
資料在記憶體中放不下,溢寫在磁碟中。記憶體中存放序列化的資料。 |
|
DISK_ONLY |
低 |
高 |
否 |
是 |
直接儲存在硬盤裡面 |
程式示例:將RDD資料集持久化在記憶體中。
JavaRDD<Integer> rdd =sc.parallelize(Arrays.asList(1,2,3,4,5)); rdd.persist(StorageLevel.MEMORY_ONLY()); System.out.println(rdd.count()); System.out.println(StringUtils.join(rdd.collect(),','));
RDD還有unpersist()方法,呼叫該方法可以手動把持久化的RDD從快取中移除。
9.不同的RDD型別
Java中有兩個專門的類JavaDoubleRDD和JavaPairRDD,來處理特殊型別的RDD,這兩個類還針對這些型別提供了額外的函式,折讓你可以更加了解所發生的一切,但是也顯得有些累贅。
要構建這些特殊型別的RDD,需要使用特殊版本的類來替代一般使用的Function類。如果要從T型別的RDD創建出一個DoubleRDD,我們就應當在對映操作中使用DoubleFunction<T>來替代Function<T,Double>。
程式例項:以下是一個求RDD每個物件的平方值的程式例項,將普通的RDD物件轉化為DoubleRDD物件,最後呼叫DoubleRDD物件的max()方法,返回生成的平方值中的最大值。
JavaRDD<Integer> rdd =sc.parallelize(Arrays.asList(1,2,3,4,5));
JavaDoubleRDD result=rdd.mapToDouble(
new DoubleFunction<Integer>() {
public double call(Integer integer) throws Exception {
return (double) integer*integer;
}
}
);
System.out.println(result.max());