
淺析NUMA體系結構
1. NUMA的幾個概念(Node,socket,core,thread)
對於socket,core和thread會有不少文章介紹,這裡簡單說一下,具體參見下圖:
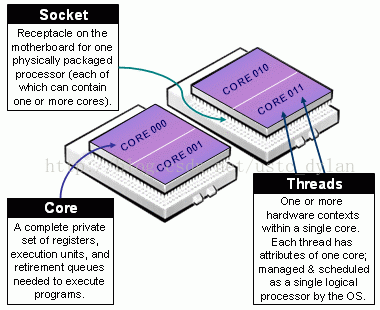
一句話總結:socket就是主機板上的CPU插槽; Core就是socket裡獨立的一組程式執行的硬體單元,比如暫存器,計算單元等; Thread:就是超執行緒hyperthread的概念,邏輯的執行單元,獨立的執行上下文,但是共享core內的暫存器和計算單元。
NUMA體系結構中多了Node的概念,這個概念其實是用來解決core的分組的問題,具體參見下圖來理解(圖中的OS CPU可以理解thread,那麼core就沒有在圖中畫出),從圖中可以看出每個Socket裡有兩個node,共有4個socket,每個socket 2個node,每個node中有8個thread,總共4(Socket)× 2(Node)× 8 (4core × 2 Thread) = 64個thread。
另外每個node有自己的內部CPU,匯流排和記憶體,同時還可以訪問其他node內的記憶體,NUMA的最大的優勢就是可以方便的增加CPU的數量,因為Node內有自己內部匯流排,所以增加CPU數量可以通過增加Node的數目來實現,如果單純的增加CPU的數量,會對匯流排造成很大的壓力,所以UMA結構不可能支援很多的核。
《此圖出自:NUMA Best Practices for Dell PowerEdge 12th Generation Servers》
根據上面提到的,由於每個node內部有自己的CPU匯流排和記憶體,所以如果一個虛擬機器的vCPU跨不同的Node的話,就會導致一個node中的CPU去訪問另外一個node中的記憶體的情況,這就導致記憶體訪問延遲的增加。在有些特殊場景下,比如NFV環境中,對效能有比較高的要求,就非常需要同一個虛擬機器的vCPU儘量被分配到同一個Node中的pCPU上,所以在OpenStack的Kilo版本中增加了基於NUMA感知的虛擬機器排程的特性。(OpenStack Kilo中NFV相關的功能具體參見:《OpenStack Kilo新特性解讀和分析(1)》)
2. 如何檢視機器的NUMA拓撲結構
比較常用的命令就是lscpu,具體輸出如下:
- [email protected]:~$ lscpu
- Architecture: x86_64
- CPU op-mode(s): 32-bit, 64-bit
- Byte Order: Little Endian
- CPU(s): 48 //共有48個邏輯CPU(threads)
- On-line CPU(s) list: 0-47
- Thread(s) per core: 2 //每個core有2個threads
- Core(s) per socket: 6 //每個socket有6個cores
- Socket(s): 4 //共有4個sockets
- NUMA node(s): 4 //共有4個NUMA nodes
- Vendor ID: GenuineIntel
- CPU family: 6
- Model: 45
- Stepping: 7
- CPU MHz: 1200.000
- BogoMIPS: 4790.83
- Virtualization: VT-x
- L1d cache: 32K //L1 data cache 32k
- L1i cache: 32K //L1 instruction cache 32k (牛x機器表現,馮諾依曼+哈弗體系結構)
- L2 cache: 256K
- L3 cache: 15360K
- NUMA node0 CPU(s): 0-5,24-29
- NUMA node1 CPU(s): 6-11,30-35
- NUMA node2 CPU(s): 12-17,36-41
- NUMA node3 CPU(s): 18-23,42-47
另外,也可以通過下面的網頁設計指令碼來打印出當前機器的socket,core和thread的數量。
- #!/bin/bash
- # Simple print cpu topology
- # Author: kodango
- function get_nr_processor()
- {
- grep '^processor' /proc/cpuinfo | wc -l
- }
- function get_nr_socket()
- {
- grep 'physical id' /proc/cpuinfo | awk -F: '{
- print $2 | "sort -un"}' | wc -l
- }
- function get_nr_siblings()
- {
- grep 'siblings' /proc/cpuinfo | awk -F: '{
- print $2 | "sort -un"}'
- }
- function get_nr_cores_of_socket()
- {
- grep 'cpu cores' /proc/cpuinfo | awk -F: '{
- print $2 | "sort -un"}'
- }
- echo '===== CPU Topology Table ====='
- echo
- echo '+--------------+---------+-----------+'
- echo '| Processor ID | Core ID | Socket ID |'
- echo '+--------------+---------+-----------+'
- while read line; do
- if [ -z "$line" ]; then
- printf '| %-12s | %-7s | %-9s |\n' $p_id $c_id $s_id
- echo '+--------------+---------+-----------+'
- continue
- fi
- if echo "$line" | grep -q "^processor"; then
- p_id=`echo "$line" | awk -F: '{print $2}' | tr -d ' '`
- fi
- if echo "$line" | grep -q "^core id"; then
- c_id=`echo "$line" | awk -F: '{print $2}' | tr -d ' '`
- fi
- if echo "$line" | grep -q "^physical id"; then
- s_id=`echo "$line" | awk -F: '{print $2}' | tr -d ' '`
- fi
- done < /proc/cpuinfo
- echo
- awk -F: '{
- if ($1 ~ /processor/) {
- gsub(/ /,"",$2);
- p_id=$2;
- } else if ($1 ~ /physical id/){
- gsub(/ /,"",$2);
- s_id=$2;
- arr[s_id]=arr[s_id] " " p_id
- }
- }
- END{
- for (i in arr)
- printf "Socket %s:%s\n", i, arr[i];
- }' /proc/cpuinfo
- echo
- echo '===== CPU Info Summary ====='
- echo
- nr_processor=`get_nr_processor`
- echo "Logical processors: $nr_processor"
- nr_socket=`get_nr_socket`
- echo "Physical socket: $nr_socket"
- nr_siblings=`get_nr_siblings`
- echo "Siblings in one socket: $nr_siblings"
- nr_cores=`get_nr_cores_of_socket`
- echo "Cores in one socket: $nr_cores"
- let nr_cores*=nr_socket
- echo "Cores in total: $nr_cores"
- if [ "$nr_cores" = "$nr_processor" ]; then
- echo "Hyper-Threading: off"
- else
- echo "Hyper-Threading: on"
- fi
- echo
- echo '===== END ====='
email: [email protected]
微博:@Marshal-Liu
PC硬體結構近5年的最大變化是多核CPU在PC上的普及,多核最常用的SMP微架構:
- 多個CPU之間是平等的,無主從關係(對比IBM Cell)網路公司;
- 多個CPU平等的訪問系統記憶體,也就是說記憶體是統一結構、統一定址的(UMA,Uniform Memory Architecture);
- CPU到CPU的訪問必須通過系統匯流排。
結構如圖所示:
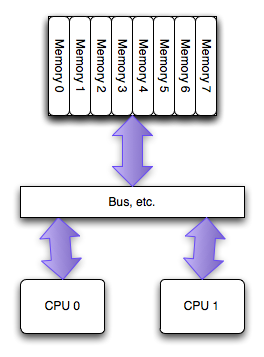 SMP的問題主要在CPU和記憶體之間的通訊延遲較大、通訊頻寬受限於系統匯流排頻寬,同時匯流排頻寬會成為整個系統的瓶頸。
SMP的問題主要在CPU和記憶體之間的通訊延遲較大、通訊頻寬受限於系統匯流排頻寬,同時匯流排頻寬會成為整個系統的瓶頸。
由此應運而生了NUMA架構:
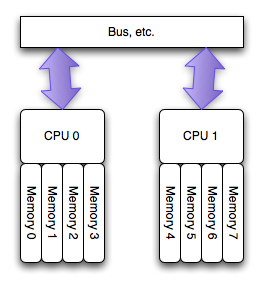 NUMA(Non-Uniform Memory Access)是起源於AMD Opteron的微架構,同時被Intel
Nehalem採用(英特爾志強E5500以上的CPU和桌面的i3、i5、i7均基於此架構)。這也應該是繼AMD64後AMD對CPU架構的又一項重要改進。
NUMA(Non-Uniform Memory Access)是起源於AMD Opteron的微架構,同時被Intel
Nehalem採用(英特爾志強E5500以上的CPU和桌面的i3、i5、i7均基於此架構)。這也應該是繼AMD64後AMD對CPU架構的又一項重要改進。
在這個架構中,每個處理器有其可以直接訪問其自身的“本地”記憶體池,使CPU和這塊兒記憶體之間擁有更小的延遲和更大的頻寬。而且整個記憶體仍然可做為一個整體,可以接受來自任何CPU的訪問。簡言之就是CPU訪問自己領地內的記憶體延遲最小獨佔頻寬,訪問其他的記憶體區域稍慢並且共享頻寬。
GNU/Linux如何管理NUMA:
- probe硬體,瞭解物理CPU數量,記憶體大小等;
- 根據物理CPU的數量(不是core)分配node,一個物理CPU對應一個node;
- 把屬於一個node的記憶體模組和其node相聯絡;
- 測試各個CPU到各個記憶體區域的通訊延遲;
在一臺16GB記憶體,雙Xeon E5620 CPU Dell R710用numactl得到以下資訊:
# numactl --hardware
available: 2 nodes (0-1)
node 0 size: 8080 MB
node 0 free: 5643 MB
node 1 size: 8051 MB
node 1 free: 2294 MB
node distances:
node 0 1
0: 10 20
1: 20 10
- 第一列node0和node1就是對應物理CPU0和CPU1;
- size就是指在此節點NUMA分配的記憶體總數;
- free是指此節點NUMA的記憶體空閒數量;
- node distances就是指node到各個記憶體節點之間的距離,預設情況10是指本地記憶體,21是指跨區域訪問。
因為就近記憶體訪問的快速性,所以預設情況下一個CPU只訪問其所屬區域的記憶體空間。此時造成的問題是在大記憶體佔用的一些應用時會有CPU近線記憶體不夠的情況,可以使用如下方式把CPU對記憶體區域的訪問變為round robin方式。此時需要通過以下方式修改:
# echo 0 > /proc/sys/vm/zone_reclaim_mode
# numactl --interleave=all
memcached、redis、monodb等應該做以上的優化修改。
另外,如果有時間,下一篇會總結一下自己對於此問題的思考:如果自己實現一個記憶體池,併發揮NUMA架構的最大效能,如何設計?
參考自:
http://en.wikipedia.org/wiki/Non-Uniform_Memory_Access
Ulrich Drepper, Memory part 4: NUMA support http://lwn.net/Articles/254445/
http://www.kernel.org/doc/Documentation/sysctl/vm.txt
就目前而言,CPU主頻速度的迅速提升以及CPU數量的高速增長,並沒有能夠促使CPU在訪問記憶體時的速度有所長進。
儘管L3 Cache的提出解決了部分問題,不過,CPU訪問記憶體速度慢的現象並未有所改觀,瓶頸依然存在。
為了更有效的解決CPU訪問記憶體的速度問題,工業界引入了NUMA概念
首先介紹一下 NUMA 的架構,如下圖:

每個 NUMA 節點(硬體 NUMA 或軟體 NUMA)都有一個用於處理網路 I/O 的相關 I/O 完成埠,這有助於跨多個埠分佈網路 I/O 處理
上述結構中展現出兩個NUMA結點,每個NUMA結點有一些CPU, 一個內部匯流排,和自己的記憶體,甚至可以有自己的IO。每個CPU有離自己最近的記憶體可以直接訪問。
所以,使用NUMA架構,系統的效能會更佳。值得注意的是,在NUMA結構下,可以比較方便的增加CPU的數目。
而在非NUMA架構下,增加CPU會導致系統匯流排負載很重,效能提升不明顯。
雖然每個CPU也可以訪問其他NUMA結點上的記憶體,但付出的代價則是導致網站運營速度更慢,這是要儘量避免的。
應用軟體如果沒有意識到這種結構,在NUMA機器上,有時候效能會更差,這是因為,他們經常會不自覺的去訪問遠端記憶體,從而導致整體效能下降。
通常而言,NUMA架構也有硬體和軟體之分。
一、硬體NUMA
硬體NUMA是在硬體層面上得以支援。如何才能知道本機是否有硬體NUMA呢? 最好的辦法是問硬體供應商了。
但如果想知道機器中有多少個NUMA結點,那就可以在SQL Server Management Studio下用如下的查詢,看能返回幾個NUMA結點
1 SELECT DISTINCT memory_node_id FROM sys.dm_os_memory_clerks
或者,可以檢視SQL Server的錯誤日誌,如下面的錯誤日誌表明,系統有兩個NUMA結點

從 SQL Server 2000 SP3 以後,SQL Server開始支援NUMA架構,記憶體訪問會盡量使用離CPU最近的記憶體,以提高效能。
二、軟體NUMA
如果硬體本身不支援NUMA,還可以在軟體層面上設定NUMA,如機器有4個CPU, 設成兩個NUMA NODE
一個NODE佔用CPU 0x11 (二進位制編碼),另外一個NODE佔用CPU 0x1100 (二進位制編碼)。
那麼,可以在登錄檔上做如下修改,以SQL Server 2008為例:

軟體NUMA只是對CPU進行分組,並不會改變記憶體。因此對於記憶體來講,還是隻有一個結點,所以兩個NUMA結點,訪問的都是同一塊記憶體。
而增加軟體NUMA結點的好處在於,SQL Server會針對每一個軟體NUMA結點,多一個LazyWriter的執行緒,
如果系統在LazyWriter上是效能瓶頸的話,引入Software NUMA則可以有效提升效能。
在伺服器屬性這個地方設定的只是軟體NUMA,要機器真正支援硬體NUMA才是真正的NUMA

面對連線層面的NUMA
SQL Server 不僅僅在引擎上支援NUMA,在連線層面上也支援NUMA。
如果沒有在連線層面上對NUMA進行設定的話,那麼每一個連線進來,SQL Server會根據round-robin方式,選擇NODE 進行處理。
在NODE內部,SQL Server會選擇CPU負載最低的一個CPU進行處理。而這種方法的網站優化缺點是,有可能某一個NODE內的所有CPU都很忙,
但是另外一個NODE內的所有CPU都很空,從而導致資源不均衡。這種情況下,使用NUMA架構時網站推廣效能反而會下降,還不如使用非NUMA架構,
系統能均衡分配CPU資源。
如下圖所示,採用round-robin方式,可能NUMA NODE 0會非常繁忙,而NUMA NODE 1會非常空閒,系統資源不能充分利用。
重要的連線可能會被分配到NODE 0,導致不能得到及時處理,效能受到影響。

對此,可以在連線層面上進行設定。對於重要的操作,使用埠1450,該埠會繫結NUMA結點0、1,、2,
而對於不重要的網路優化操作(可能需要耗費大量資源,但不重要的),則使用網路推廣埠1433,該網路營銷埠會繫結NUMA結點3,
如此,不重要的操作不會對重要的操作在效能上有所影響

如何設定埠對NUMA結點的繫結?可以在偵聽的設計公司埠後面加NUMA結點資訊。如有八個NUMA結點,如果要使用NUMA結點0, 2, 5 那麼根據MASK方式,
相應的數值是0x25,或37

在SQL Server的網路設定中,相應的網路偵聽埠後面,我們可以加MASK數值,如下,
這樣,埠63409進來的連線,會跟NUMA結點0, 2, 5 進行繫結。

應該在配置管理器那裡設定,我的是SQL2005

綜上所述,NUMA概念的引入,將大大地提升硬體的可擴充套件性和處理能力。
SQL Server 從硬體NUMA、軟體NUMA及連線上分別對NUMA這個體系架構做了優化支援,因此,在NUMA架構下,SQL Server擁有更佳的建設網站效能和更好的網站設計公司擴充套件。
SQL Server 如何支援 NUMA
這裡我摘抄一些重要部分算了
公共 CPU 的網站設計分組
SQL Server 對計劃程式進行分組,以根據 Windows 所顯示的硬體 NUMA 邊界將這些計劃程式對映到 CPU 的分組。
例如,16 路邏輯單元有 4 個 NUMA 節點,每個節點有 4 個 CPU。這使得在節點上處理任務時,該組計劃程式具有更多的本地記憶體。
使用 SQL Server,您可以進一步將網站建設公司與硬體 NUMA 節點關聯的 CPU 細分為多個 CPU 節點。這稱為軟體 NUMA。
通常,您將細分做網站CPU 以跨建網站 CPU 節點對工作進行分割槽。
名詞解釋:
16 路邏輯單元:說的是16個邏輯CPU,什麼是邏輯CPU,比如酷睿I3cpu 雙核四執行緒,那麼四執行緒實際上就是四個邏輯CPU
四個邏輯CPU是指在同一個時間點,可以同時運算的計算單元,執行四個執行緒,處理四個任務在同一個時間點
繼續摘抄:--------------------------------------------------------------------------------------------------------------------
每個 NUMA 節點(硬體 NUMA 或軟體 NUMA)都有一個用於處理網路 I/O 的相關 I/O 完成埠,這有助於跨多個埠分佈網路 I/O 處理。
當某個客戶端連線到 SQL Server 時,將繫結到其中一個節點。此客戶端的所有批處理請求都將在該節點上處理
上面這句話是對上面哪兩個圖的很好解釋
軟體 NUMA 針對計算機中的所有 SQL Server 例項定義一次,因此,多個數據庫引擎例項都能看到同樣的軟體 NUMA 節點。
然後,每個資料庫引擎例項都使用 affinity mask 選項選擇相應的 CPU。接著,每個例項都使用與這些 CPU 關聯的任何軟體 NUMA 節點
這句話說的就是伺服器屬性裡面的CPU掩碼
Windows 在啟動後,從硬體 NODE 0 為作業系統分配記憶體。
因此,硬體 NODE 0 可用於其他應用程式的本地記憶體少於其他節點。
當需要快取一個大型檔案時,此問題尤為突出。當 SQL Server 在具有多個 NUMA 節點的計算機中啟動時,它將嘗試在 NODE 0 以外的 NUMA 節點上啟動
如何將連線分配到 NUMA 節點
TCP 和 VIA 都可以將連線關聯到一個或多個特定 NUMA 節點。當未進行關聯,或使用 Named Pipes 或 Shared Memory 進行連線時,連線將採用迴圈方式分佈到 NUMA 節點。在 NUMA 節點內,連線按照該節點上負載最小的計劃程式執行。由於新連線的分配具有迴圈性,因此,例如:網站建設,APP開發,網頁製作,網站製作,網站製作公司企業網站建設的網站中可以設定的。當某個節點空閒時,另一個節點中的所有
CPU 可能都處於繁忙狀態。如果您的 CPU 非常少(如 2 個),
並且看到由於具有長時間執行的批處理(如大容量載入)而導致龐大的計劃不均衡,則在這種情況下,關閉 NUMA 可能會提高效能。
這句話同樣也是上面兩個分配連線的截圖的補充解釋
SQL Server 版本限制
從 SQL Server 2000 到 Service Pack 3,都不包括對 NUMA 的特別支援;
但是,Service Pack 4 有一些有限的 NUMA 優化。SQL Server 2005 有了大量重要的改進
,因此,我們極力鼓勵 NUMA 使用者升級到 SQL Server 2005 以充分利用 NUMA 體系結構
我的個人理解
SQLSERVER2008支援硬體NUMA,SQLSERVER2005只支援軟體NUMA
假如一臺電腦有兩個物理NUMA節點(當然前提是電腦要支援NUMA),那麼記憶體可以分成兩份
SQL2008可以直接訪問這兩份記憶體
SQL2005 只能訪問同一份記憶體
(引用一下宋大俠的一些圖片)
NUMA節點的概念
邏輯CPU:代表多少個執行緒
core:代表多少個核心
numa node:numa節點
socket:socket通訊
例如:酷睿I3 雙核四執行緒,那麼邏輯CPU(logical cpu)有4個,core有2個

SQL Server OS在SMP硬體 直接訪問同一個記憶體 方向 是自下向上

SQL Server OS在NUMA硬體 將一份實體記憶體分成兩份 方向 是自下向上

相關推薦
淺析NUMA體系結構
由於OpenStack Kilo增加很多針對NUMA體系結構的增強功能,所以又重新溫習了下NUMA相關的知識,簡單做個筆記。 1. NUMA的幾個概念(Node,socket,core,thread) 對於socket,core和thread會有不少文章介紹,
淺析Trafodion體系結構
pri stl ransac nal acid 分布式事務 等待 原則 更多 淺析Trafodion體系結構 Trafodion簡介 Trafodion是一個構建在Hadoop/HBase基礎之上的關系型數據庫,它完全開源免費。Trafodion能夠完整地支持AN
jvm的內部體系結構淺析--轉
跳轉 對象 裝載 基礎 數據 defined 服務 java虛擬機規範 平時 jvm全稱是Java Virtual Machine(java虛擬機)。它之所以被稱之為是“虛擬”的,就是因為它僅僅是由一個規範來定義的抽象計算機。我們平時經常使用的Sun HotSpot
軟件體系結構六大質量屬性-淺析淘寶網
用戶界面 body 有一個 log 價格 進行 代碼段 訪問 完成 淘寶網質量屬性描述 以淘寶網為例,進行描繪質量屬性的六個常見屬性場景。 1.可用性 可用性與系統故障及其後果相關。當系統不再提供其規範中所說的服務時,就出現了系統故障。系統用戶
淺析理解Oracle數據庫體系結構和存儲結構
控制文件 打開 提高 相互 col 刪除 undo 建議 行數 一、Oracle體系結構 個人比喻幫助理解:類似於圖書館,去圖書館的客戶(用戶進程和服務進程等)需要調取資料,求助於圖書管理員(實例)進入圖書分區(數據庫)進行資料查找。【如果比喻不當,歡迎指正,盡請諒解】
馮諾依曼體系結構淺析
馮·諾依曼結構計算機(百度解釋) 美籍匈牙利科學家馮·諾依曼最新提出程式儲存的思想,併成功將其運用在計算機的設計之中,根據這一原理製造的計算機被稱為馮·諾依曼結構計算機。由於他對現代計算機技術的突出貢獻,因此馮·諾依曼又被稱為“現代計算機之父”。 說
android的四層體系結構,基於mvc三層結構淺析
從多方面理解Android體系結構 1.以分層的方式來看Android 安卓體系結構分為四層。 首先看一下官方關於Android體系結構的圖: 1)、Linux Kernel:負責硬體的驅動程式、網路、電源、系統安全以及記憶體管理等功能。 2)、 Libraries和
ORACLE 體系結構
默認 告警 再次 ava shared 檢查 從數據 物理結構 增量 本文內容來自王二暖11G視頻講解 oracle工作原理: 1)、在數據庫服務器上啟動Oracle實例;2)、應用程序在客戶端的用戶進程中運行,啟用Oracle網絡服務驅動器與服務器建立連接;3)、服
PCI Express 系統體系結構標準教材
2.3 應用程序 pack 1-1 排序 bsp 芯片 png 成了 第1章 體系結構展望 1.1 第一代總線:ISA,EISA,VESA 第二代總線:PCI, AGP, PCI-X 第三代總線:PCIE 1.2 PCIE的存儲器、IO和配置地址
mysql體系結構理解與分析
interface storage 編程語言 數據庫 結構圖 接觸mysql有一年多了,但是始終是一個偶爾用用的狀態,對其原理性的東西研究不夠,在不少mysql相關的暑假中提到mysql體系結構,很清楚解析了mysql的各個模塊分層和主要功能特性,在理解此功能特性後,會剛好的幫助我
Hadoop中Hbase的體系結構
才會 right hmaster mar hbase 緩存 master 恢復數據 處理 HRegion 當一張表中的數據特別多的時候,HBase把表拆成多個塊,每個塊就是一個HRegion,每個region中包含這個表裏的所有行 HRegionServer 數據
網絡標準體系結構
point clion utl out 架構 同時 poi 應用 apach 網絡標準體系結構主要分為三種 1.B/S架構:Browser/Server 瀏覽器與服務器 2.C/S架構:Cliont/Server 客戶端與服務器 3.P2P:Point to Point 點
Oracle數據庫------體系結構
顧問 內存結構 動態 alt 索引 ron 信息 instance 訪問 ORACLE體系結構包括:實例(Instance),數據庫文件,用戶進程(User process),服務器進程以及其他文件。 1.ORACLE實例(instance) 1).要訪問數據庫必須
JSP的體系結構
創建 需要 改變 而不是 靜態 技術 修改 mage 編程 以下內容引用自http://wiki.jikexueyuan.com/project/jsp/architecture.html: Web服務器需要一個JSP引擎,即處理JSP頁面的容器。JSP容器負責為JSP頁
Zookeeper體系結構
存在 zookeepe pan -a mark 五個 -m 節點 ask 上面我們已經討論了zookeeper在應用程序中的一些操作,以下我們須要理解一下服務端的工作的原理。client是怎樣通過一個client的類庫與服務端進行通信的,然後服務端又是怎樣回應client
redis 體系結構
alt 客戶端命令 mem key ges 並不是 不出 字符串 get 程序strings key-value 類型 ,value不僅是String,也可以是數字.使用strings 類型可以完全實現目前 Memcache 的功能,並且效率更高,還可以享受redis的
Oracle 體系結構chapter2
轉載 share 通過 生存 cnblogs 恢復 啟動 數據表 默認 前言:Oracle 體系結構其實就是指oracle 服務器的體系結構,數據庫服務器主要由三個部分組成 管理數據庫的各種軟件工具(sqlplus,OEM等),實例(一組oracle 後臺進程以及服務器中分
ARM體系結構總結
匯編指令集 cpu架構1. 匯編指令集 對於不同CPU的指令集則代表著CPU各自不同的編程特征,而CPU內部電路的設計是為了實現這些指令集的具體功能。2. CISC和RISC架構的區別 CISC,復雜指令集CPU,其設計的理念就是使用最少的指令來實現功能,所以CPU本身的設計就很復雜,其典型代表Inte
OSI,TCP/IP,五層協議的體系結構,以及各層協議
802.3 面向連接 udp 用戶 數據包 格式 ios mpeg 用戶數據 以下整理的是計算機網絡的OSI,TCP/IP,五層協議的體系結構,以及各層協議,便於以後查看: OSI分層,自上而下分別是:物理層,數據鏈路層,網絡層,傳輸層,會話層,表示層,應用層 TCP/IP
spring framework體系結構及內部各模塊jar之間的maven依賴關系
都在 pen 構圖 功能 sock 編譯 pla core cat 很多人都在用spring開發java項目,但是配置maven依賴的時候並不能明確要配置哪些spring的jar,經常是胡亂添加一堆,編譯或運行報錯就繼續配置jar依賴,導致spring依賴混亂,甚至下一次創