
史上最全!阿里智慧人機互動的核心技術解析

“連線“本身不是目的,它只是為“互動”建立了通道。在人機互動(Human-Computer Interaction)中,人通過輸入裝置給機器輸入相關訊號,這些訊號包括語音、文字、影象、觸控等中的一種模態或多種模態,機器通過輸出或顯示裝置給人提供相關反饋訊號。“連線”為“互動”雙方架起了橋樑。
“互動”的演進方向是更加自然、高效、友好和智慧。對人來說,採用自然語言與機器進行智慧對話互動是最自然的互動方式之一,但這條路上充滿了各種挑戰。如何讓機器理解人類複雜的自然語言?如何對使用者的提問給出精準的答案而不是一堆候選?如何更加友好地與使用者閒聊而不是答非所問?如何管理複雜的多輪對話狀態和對話上下文?在阿里巴巴,我們從2014年初開始對智慧對話互動進行探索和實踐創新,研發成果逐步大規模應用在了智慧客服(針對阿里巴巴生態內部企業的阿里小蜜、針對阿里零售平臺上的千萬商家的店小蜜,以及針對阿里之外企業及政府的雲小蜜等)和各種裝置(如YunOS手機、天貓魔盒、網際網路汽車等)上。
本文將對阿里巴巴在智慧對話互動技術上的實踐和創新進行系統的介紹。首先簡要介紹智慧對話互動框架和主要任務;接下來詳細介紹自然語言理解、智慧問答、智慧聊天和對話管理等核心技術;然後介紹阿里巴巴的智慧對話互動產品;最後是總結和思考。強烈建議收藏細看!
本文作者:孫健,李永彬,陳海青,邱明輝
1 智慧對話互動框架
典型的智慧對話互動框架如圖1所示。其中,語音識別模組和文字轉語音模組為可選模組,比如在某些場景下使用者用文字輸入,系統也用文本回復。自然語言理解和對話管理是其中的核心模組,廣義的自然語言理解模組包括對任務類、問答類和閒聊類使用者輸入的理解,但在深度學習興起後,大量端到端(End-to-End)的方法湧現出來,問答和聊天的很多模型都是端到端訓練和部署的,所以本文中的自然語言理解狹義的單指任務類使用者輸入的語義理解。在圖2所示的智慧對話互動核心功能模組中,自然語言理解和對話管理之外,智慧問答用來完成問答類任務,智慧聊天用來完成閒聊類任務。在對外輸出層,我們提供了SaaS平臺、PaaS平臺和BotFramework三種方式,其中Bot Framework為使用者提供了定製智慧助理的平臺。
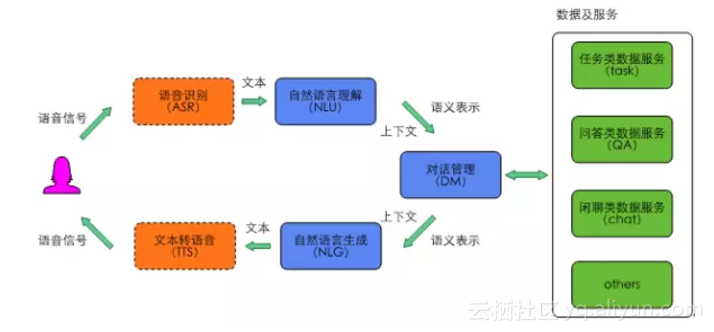
圖1 智慧對話互動框架
2 智慧對話互動核心技術
智慧對話互動中的核心功能模組如圖2所示,本部分詳細介紹智慧對話互動中除輸出層外的自然語言理解、智慧問答、智慧聊天和對話管理四個核心模組。
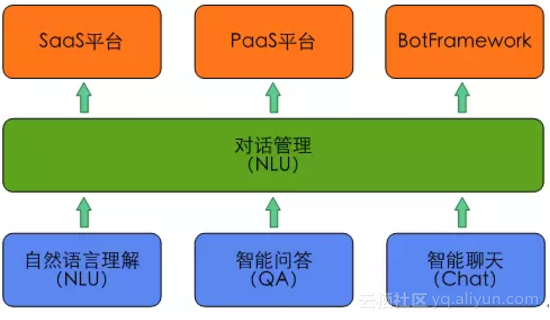
圖2 智慧對話互動中的核心功能模組
2.1自然語言理解
自然語言理解是人工智慧的AI-Hard問題[1],也是目前智慧對話互動的核心難題。機器要理解自然語言,主要面臨如下的5個挑戰。
(1)語言的多樣性
(2)語言的多義性
(3)語言的表達錯誤
(4)語言的知識依賴
(5)語言的上下文表1 上下文示例

注:U指使用者(user),A指智慧體(agent)。下同。
整個自然語言理解圍繞著如何解決以上難點問題展開。
2.1.1自然語言理解語義表示
自然語言理解的語義表示主要有三種方式[2]。
(1)分佈語義表示(Distributional semantics)
(2)框架語義表示(Frame semantics)
(3)模型論語義表示(Model-theoretic semantics)
在智慧對話互動中,自然語言理解一般採用的是framesemantics表示的一種變形,即採用領域(domain)、意圖(intent)和屬性槽(slots)來表示語義結果,如圖3所示。
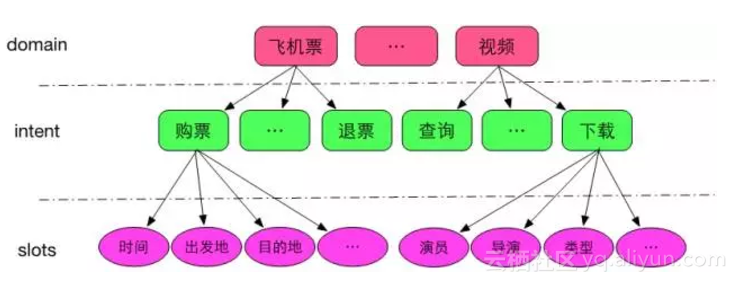
圖3domain ongology示意圖
在定義了上述的domain ontology結構後,整個演算法流程如圖4所示。
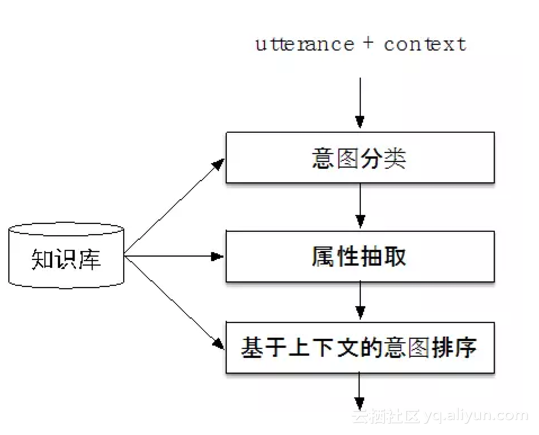
圖4 自然語言理解流程簡圖
2.1.2意圖分類
意圖分類是一種文字分類,主要分為基於規則的方法、基於傳統機器學習的方法和基於深度學習的方法,如CNN [3]、LSTM [4]、RCNN [5]、C-LSTM [6]及FastText[7]等。針對CNN、LSTM、RCNN、C-LSTM四種典型的模型框架,我們在14個領域的資料集上進行訓練,在4萬左右規模的測試集上進行測試,採用Micro F1作為度量指標(注:此處的訓練和測試中,神經網路的輸入只包含word embedding,沒有融合符號表示),結果如圖5所示,其中Yoon Kim在2014年提出的基於CNN[3]的分類演算法效果最好。
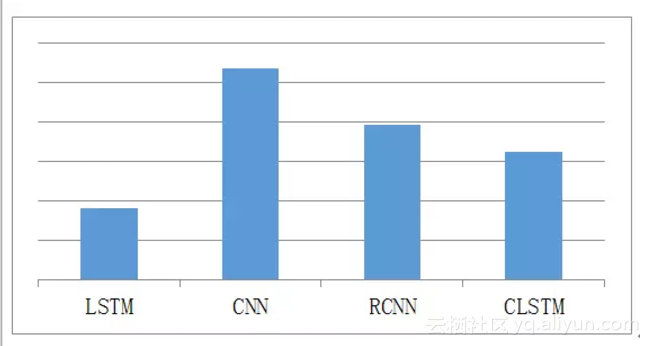
圖5 四種模型的分類效果對比
單純以word vector為輸入的CNN分類效果,在某些領域上無法超越複雜特徵工程的SVM分類器。如何進一步提升深度學習的效果,其中一個探索方向就是試圖把分散式表示和符號表示進行融合。比如對於“劉德華的忘情水”這句話,通過知識庫可以標註劉德華為singer、忘情水為song,期望能把singer和song這樣的符號表示融入到網路中去。具體融合方法,既可以把符號標籤進行embedding,然後把embedding後的vector拼接到wordvector後進行分類,也可以直接用multi-hot的方式拼接到word vector後面。分散式表示和符號表示融合後的CNN結構如圖6所示。
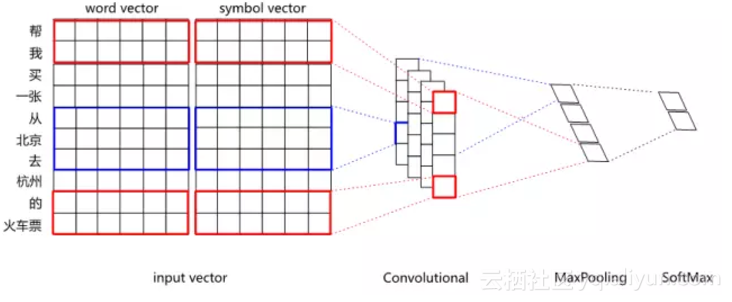
圖6 分散式表示和符號表示融合後的CNN分類網路結構
經過融合後,在14個領域約4萬條測試資料集上,對比融合前後的F1值(如圖7所示),從中可以看出,像餐廳、酒店、音樂等命名實體多且命名形式自由的領域,效果提升非常明顯。
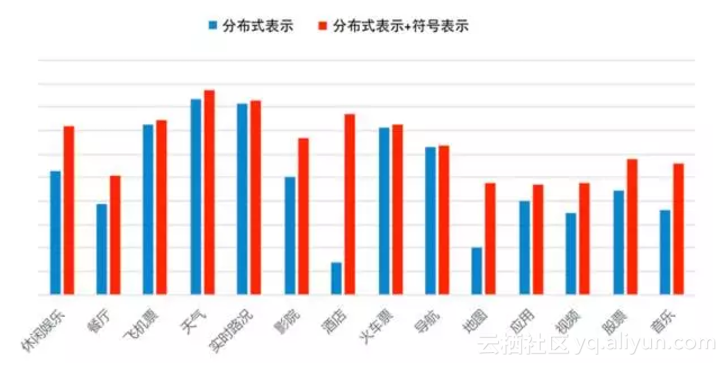
圖7 在CNN中分散式表示融合符號表示前後效果對比
在以詞為輸入單位的CNN中,經常會遇到OOV(Out-Of-Vocabulary)問題,一般情況下會使用一個特殊向量(比如固定的隨機向量或者已知詞向量的平均值)來表示所有的OOV,這樣做的效果肯定不夠好。在我們的實現中,引入了FastText [8]來訓練word vector,對於OOV,可以用其subword向量計算得到,有效地解決了OOV的問題。
在效果優化方面,除了本文中所述的word vector的動態訓練和dropout之外,通過對訓練資料進行資料增強(data augmentation),效果會有較大的提升。
2.1.3屬性抽取
屬性抽取問題可以抽象為一個序列標註問題,可以以字為單位進行序列標註,也可以以詞為單位進行序列標註,如圖8所示為以詞為單位進行序列標註的示例。在這個例子中包含departure、destination和time三個待標註標籤;B表示一個待標註標籤的起始詞;I表示一個待標註標籤的非起始詞,O表示非待標註標籤詞。

圖8 序列標註示例
屬性抽取的方法,包括基於規則的方法,基於傳統統計模型的方法,經典的如CRF[9],以及基於深度學習模型的方法。2014年,在ARTIS資料集上,RNN[10]模型的效果超過了CRF。此後,R-CRF [11]、LSTM[12]、Bi-RNN[13]、 Bi-LSTM-CRF[14]等各種模型陸續出來。
在屬性抽取這個任務中,我們採用瞭如圖9的網路結構,該結構具有以下優點。
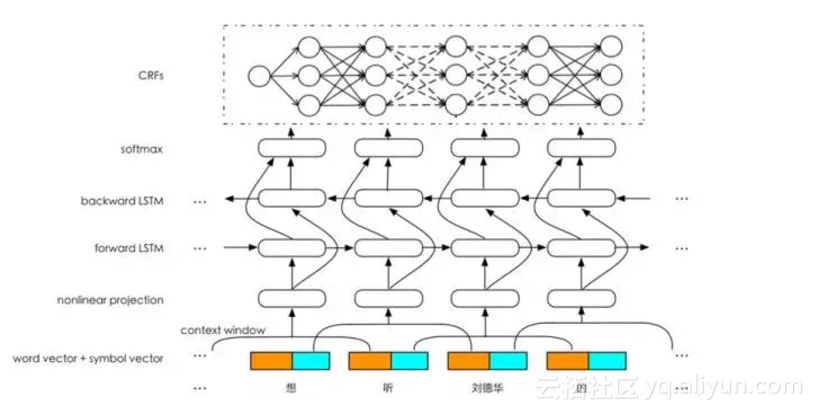
圖9 屬性抽取網路結構
(1)輸入層
在輸入層,我們做了三部分工作:① 採用了分散式表示(word vector)和符號表示(symbol vector)融合的方式,有效利用了分散式的上下文學習能力和符號的抽象知識表示能力;②採用了局部上下文視窗(local context window),將視窗內的詞的表示拼接在一起送入一個非線性對映層,非線性對映具有特徵學習和特徵降維的作用;③採用了FastText [8]進行word embedding的學習,可以有效解決OOV(Out-Of-Vocabulary)的問題。
(2)Bi-LSTM層
在中間的隱藏層,採用Bi-LSTM進行特徵學習,既能捕捉上文特徵,也能捕捉下文特徵。
(3)輸出層
在輸出層有幾種典型的做法,比如Bi-LSTM+Softmax、Bi-LSTM+CRF等,Bi-LSTM+Softmax是把屬性抽取在輸出層當成了一個分類問題,得到的標註結果是區域性最優,Bi-LSTM+CRF在輸出層會綜合句子層面的資訊得到全域性最優結果。
2.1.4意圖排序
在表1中,我們展示了一個例子,如果不看上下文,無法確定“後天呢”的意圖。為了解決這個問題,在系統中我們設計了意圖排序模組,其流程如圖10所示。對於使用者輸入的utterance,一方面先利用分類抽取模型去判定意圖並做抽取;另一方面,直接繼承上文的意圖,然後根據這個意圖做屬性抽取。這兩個結果通過特徵抽取後一起送入一個LR分類器,以判定當前utterance是應該繼承上文的意圖,還是遵循分類器分類的意圖。如果是繼承上文意圖,那麼可以把這個意圖及其屬性抽取結果作為最終結果輸出;如果是遵循分類器分類的結果,那麼可以把各個結果按照分類器分類的置信度排序輸出。
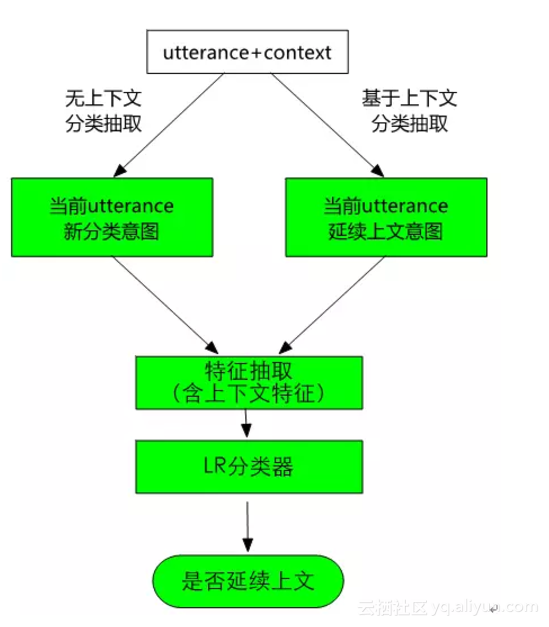
圖10 基於上下文的意圖延續判定
2.2智慧問答
在具體的業務場景中有三種典型的問答任務,一是使用者提供QA-Pairs,一問一答;二是建立結構化的知識圖譜,進行基於知識圖譜的問答;三是針對非結構化的文字,進行基於閱讀理解的問答。本文重點介紹我們在閱讀理解方面做的工作,比如利用閱讀理解解決淘寶活動規則的問答。
在閱讀理解的方法上,目前針對斯坦福大學的資料集SquAD,有大量優秀的方法不斷湧現,比如match-LSTM [15]、BiDAF [16]、DCN [17]、 FastQA [18]等。文獻[18]給出了目前的通用框架,如圖11所示,主要分為4層:① Word Embedder,對問題和文件中的詞進行embedding;② Encoder,對問題和文件進行編碼,一般採用RNN/LSTM/BiLSTM;③ Interaction Layer(互動層),在問題和文件之間逐詞進行互動,這是目前研究的熱點,主流方法是採用注意力機制(attention);④ Answer Layer(答案層),預測答案的起始位置和結束位置。
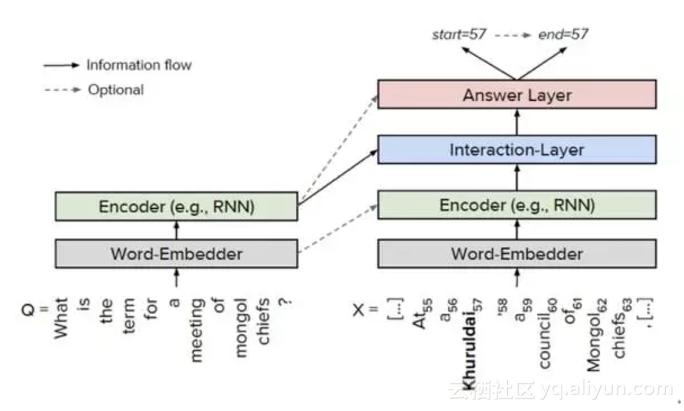
圖11 閱讀理解的通用框架
我們在具體實現中,參考BiDAF [16]網路結構,在此基礎上做了大量優化。
(1)模型的業務優化
需要改進模型的結構設計,使得模型可以支援電商文件格式的輸入。電商規則文件往往包含大量的文件結構,如大小標題和文件的層級結構等,將這些特定的篇章結構資訊一起編碼輸入到網路中,將大幅提升訓練的效果。
(2)模型的簡化
學術文獻中的模型一般都較為複雜,而工業界場景中由於對效能的要求,無法將這些模型直接在線上使用,需要做一些針對性的簡化,使得模型效果下降可控的情況下,儘可能提升線上預測效能,例如可以簡化模型中的各種bi-lstm結構。
(3)多種模型的融合
當前這些模型都是純粹的end-to-end模型,其預測的可控性和可解釋性較低,要適用於業務場景的話,需要考慮將深度學習模型與傳統模型進行融合,達到智慧程度和可控性的最佳平衡點。
2.3智慧聊天
面向open domain的聊天機器人目前無論在學術界還是在工業界都是一大難題,目前有兩種典型的方法:一是基於檢索的模型,比如文獻[19-20],其基本思路是利用搜索引擎通過計算相關性來給出答案;二是基於Seq2Seq的生成式模型,典型的方法如文獻[21-22],其網路結構如圖12所示。
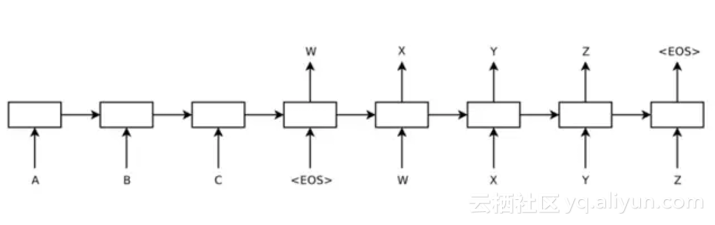
圖12 Seq2Seq典型網路結構
檢索模型的優點是答案在預設的語料庫中,可控,匹配模型相對簡單,可解釋性強;缺點是在一定程度上缺乏對語義的理解,且有固定語料庫的侷限性,長尾問題覆蓋率較差。生成模型的優點是通過深層語義方式進行答案生成,答案不受語料庫規模限制;缺點是模型的可解釋性不強,且難以保證回答一致性和合理性。
在我們的聊天引擎中,結合檢索模型和生成模型各自的優勢,提出了一種新的模型AliMe Chat [23],基本流程如圖13所示。首先採用檢索模型從QA知識庫中找出候選答案集合;然後利用帶注意力的Seq2Seq模型對候選答案進行排序,如果第一候選的得分超過某個閾值,則作為最終答案輸出,否則利用生成模型生成答案。其中帶注意力的Seq2Seq模型結構如圖14所示。經過訓練後,主要做了如下測試:如圖15所示,利用600個問題的測試集,測試了檢索(IR)、生成(Generation)、檢索+重排序(Rerank)及檢索+重排序+生成(IR+Rerank+Generation)四種方法的效果,可以看到在閾值為0.19時,IR+Rerank+Generation的方法效果最好。
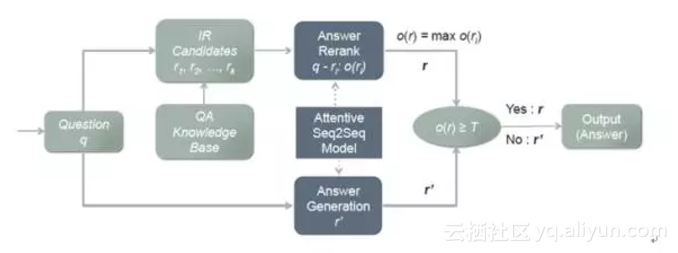
圖13AliMe Chat流程圖
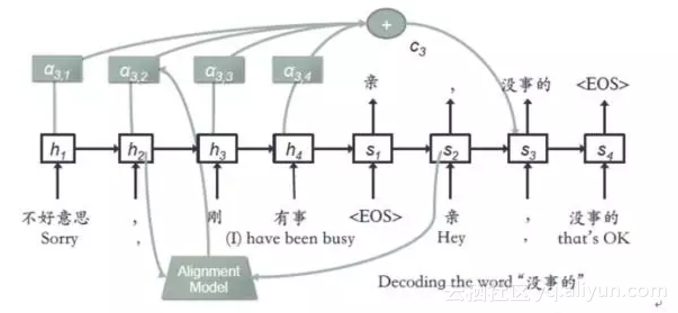
圖14 帶注意力的Seq2Seq網路結構示例
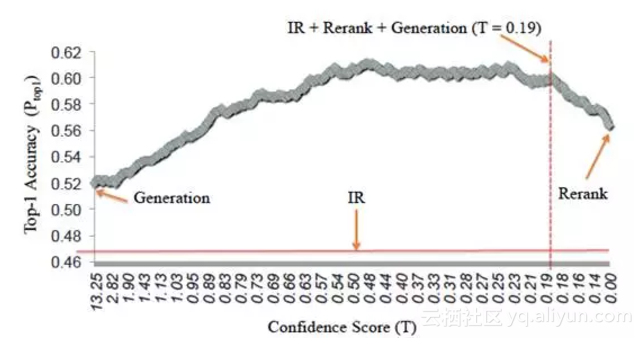
圖15 IR、Generation、Rerank、IR+Rerank+Generation效果對比
此模型在阿里小蜜中上線後,示例如圖16所示。在阿里小蜜中,針對之前的IR模型和AliMe Chat模型,利用線上流量做了A/B Test,結果如圖17所示。從使用者日誌中隨機選擇2 136條資料,其中1 089是採用IR模型回答,另外1 047是採用AliMe Chat回答,AliMe
Chat Top1答案的準確率(accuracy)是60.36%,遠遠好於IR的40.86%。

圖16AliMe Chat在阿里小蜜中上線後的聊天示例

圖17 阿里小蜜中IR方法與AliMe Chat方法A/BTest結果
2.4對話管理
對話管理根據語言理解的結構化語義表示結果以及上下文,來管理整個對話的狀態,並決定下一步採取什麼樣的動作。
下面來看一個簡單的對話例子。
U:我要去杭州,幫我訂一張火車票
A:請問你什麼時間出發?
U:明天上午
A:為你找到了以下火車票:
U:我要第二個
A:第二個是……,您是否要購買?
U:我要購買
對話互動分成兩個階段,第一階段,通過多輪對話互動,把使用者的需求收集完整,得到結構化的資訊(出發地、目的地、時間等);第二階段就是請求服務,接著還要去做選擇、確定、支付、購買等後面一系列的步驟。
傳統的人機對話,包括現在市面上常見的人機對話,一般都是隻在做第一階段的對話,第二階段的對話做得不多。對此,我們設計了一套對話管理體系,如圖18所示,這套對話管理體系具有以三個特點。
第一,設計了一套面向Task Flow的對話描述語言。該描述語言能夠把整個對話任務流完整地表達出來,這個任務流就是類似於程式設計的流程圖。對話描述語言帶來的好處是它能夠讓對話引擎和業務邏輯實現分離,分離之後業務方可以開發指令碼語言,不需要修改背後的引擎。
第二,由於有了Task Flow的機制,我們在對話引擎方帶來的收益是能夠實現對話的中斷和返回機制。在人機對話當中有兩類中斷,一類是使用者主動選擇到另外一個意圖,更多是由於機器沒有理解使用者話的意思,導致這個意圖跳走了。由於我們維護了對話完整的任務流,知道當前這個對話處在一個什麼狀態,是在中間狀態還是成功結束了,如果在中間狀態,我們有機會讓它回來,剛才講過的話不需要從頭講,可以接著對話。
第三,設計了對話面向開發者的方案,稱之為OpenDialog,背後有一個語言理解引擎和一個對話引擎。面向開發者的語言理解引擎是基於規則辦法,能夠比較好地解決冷啟動的問題,開發者只需要寫語言理解的Grammar,基於對話描述語言開發一個對話過程,並且還有對資料的處理操作。這樣,一個基本的人機對話就可以完成了。
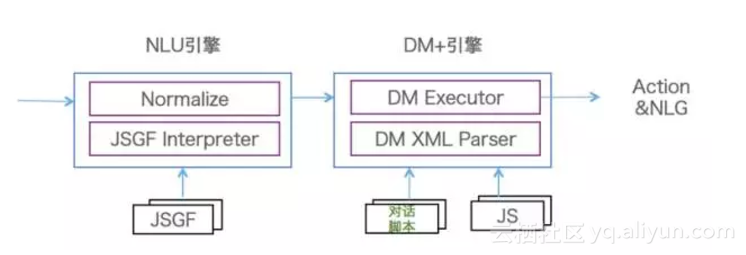
圖18 對話管理框架圖
3、阿里巴巴智慧對話互動產品
3.1智慧服務——小蜜家族
2015年7月,阿里巴巴推出了自己的智慧服務助理-阿里小蜜,一個圍繞著電子商務領域中的服務、導購,以及任務助理為核心的智慧對話互動產品。通過電子商務領域與智慧對話互動領域的結合,帶來傳統服務行業模式的變革與體驗的提升。在2016年的雙“十一”期間,阿里小蜜整體智慧服務量達到643萬,其中智慧解決率達到95%,智慧服務在整個服務量(總服務量=智慧服務量+線上人工服務量+電話服務量)佔比也達到95%,成為了雙“十一”期間服務的絕對主力。阿里小蜜主要服務阿里國內業務和阿里國際化業務,國內業務如淘寶、天貓、飛豬、健康、閒魚、菜鳥等,國際化業務如Lazada、PayTM、AE等。
隨著阿里小蜜的成功,將智慧服務能力賦能給阿里生態圈商家及阿里生態之外的企業和政府部門,便成了必然的路徑。店小蜜主要賦能阿里生態中的商家,雲小蜜則面向阿里之外的大中小企業、政府等。整個小蜜家族如圖19所示。
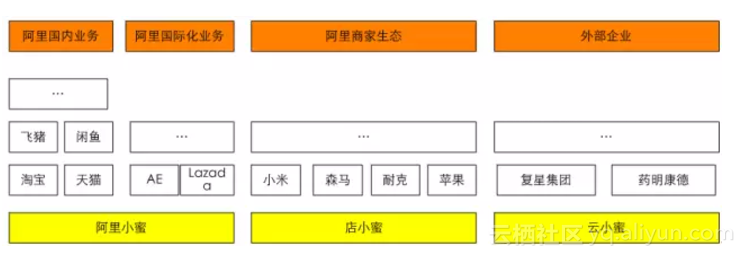
圖19 小蜜家族
3.2 智慧裝置
過去3~4年,我們可以看到,連線網際網路的裝置發生了很大變化,裝置已經從PC和智慧手機延伸到更廣泛的智慧裝置,比如智慧音箱、智慧電視、機器人、智慧汽車等裝置。智慧裝置的快速發展正在改變著人和裝置之間的互動方式。
我們研發的智慧對話互動平臺為各種裝置提供對話互動能力,目前在YunOS手機、天貓魔盒、網際網路汽車等裝置上已經大量應用。比如在天貓魔盒中,使用者通過對話互動可以完成搜視訊、查音樂、問天氣等,可以進行閒聊,還可以進行購物。
4 總結與思考
過去幾年中,結合阿里巴巴在電商、客服、智慧裝置方面的剛性需求和場景,我們在智慧對話互動上做了大量的探索和嘗試,構建了一套相對完整的資料、演算法、線上服務、離線資料閉環的技術體系,並在智慧服務和智慧裝置上得到了大規模的應用,簡單總結如下。
(1)自然語言理解方面,通過CNN/Bi-LSTM-CRF等深度學習模型、分散式表示和符號表示的融合、多粒度的wordembedding、基於上下文的意圖排序等方法,構建了規則和深度學習模型有機融合的自然語言理解系統。
(2)智慧問答方面,成功的將機器閱讀理解應用在了小蜜產品中。
(3)智慧聊天方面,提出了AliMe Chat模型,融合了搜尋模型和生成模型的優點,大大提高了閒聊的精度。
(4)對話管理方面,設計了基於Task Flow的對話描述語言,將業務邏輯和對話引擎分離,並能實現任務的中斷返回和屬性的carry-over等複雜功能。
在智慧互動技術落地應用的過程,我們也在不斷思考怎麼進一步提高智慧互動技術水平和使用者體驗。
第一,堅持使用者體驗為先。堅持使用者體驗為先,就是產品要為使用者提供核心價值。
第二,提高語言理解的魯棒性和領域擴充套件性。
第三,大力發展機器閱讀理解能力。
第四,打造讓機器持續學習能力。
第五,打造資料閉環,用資料驅動效果的持續提升。
目前的人工智慧領域仍然處在弱人工智慧階段,特別是從感知到認知領域需要提升的空間還非常大。智慧對話互動在專有領域已經可以與實際場景緊密結合併產生巨大價值,尤其在智慧客服領域(如阿里巴巴的小蜜)。隨著人工智慧技術的不斷髮展,未來智慧對話互動領域的發展還將會有不斷的提升。