【筆記】Mapreduce資料傾斜與優化
一、資料傾斜
資料分佈:
正常的資料分佈理論上都是傾斜的,就是我們所說的20-80原理:80%的財富集中在20%的人手中, 80%的使用者只使用20%的功能 , 20%的使用者貢獻了80%的訪問量 。
1.產生原因:
Mapreduce程式在執行的時候,運行了大部分,但是還有部分reduce還在執行,甚至長時間執行,最終導致整個程式執行時間很長才結束。
造成這種現象的主要原因是:
reduce程式處理的key的條數比其他key的條數大很多,這也就造成了分配到資料巨大的key的節點長時間執行。本質講資料傾斜就是資料分佈不均。
2.出現場景
不同的資料欄位可能的資料傾斜一般有兩種情況:
一種是唯一值非常少,極少數值有非常多的記錄值(唯一值少於幾千)
一種是唯一值比較多,這個欄位的某些值有遠遠多於其他值的記錄數,但是它的佔比也小於百分之一或千分之一。
3.解決方案
方式1:增加reduce 的jvm記憶體
既然reduce 本身的計算需要以合適的記憶體作為支援,在硬體環境容許的情況下,增加reduce 的記憶體大小顯然有改善資料傾斜的可能,這種方式尤其適合資料分佈第一種情況,單個值有大量記錄, 這種值的所有紀錄已經超過了分配給reduce 的記憶體,無論你怎麼樣分割槽這種情況都不會改變。
方式2: 增加reduce 個數
這個對於資料分佈第二種情況有效,唯一值較多,單個唯一值的記錄數不會超過分配給reduce 的記憶體. 如果發生了偶爾的資料傾斜情況,增加reduce 個數可以緩解偶然情況下的某些reduce 不小心分配了多個較多記錄數的情況. 但是對於第一種資料分佈無效。
方式3: 自定義partition
如果map輸出鍵的單詞來源於一本書。其中大部分必然是省略詞(stopword: a,the,or )。那麼就可以將自定義分割槽將這部分省略詞傳送給固定的一部分reduce例項。而將其他的都發送給剩餘的reduce例項。
方式4:設定combiner
減少流向reduce的檔案數量,從而減輕reduce資料傾斜。
二、MapReduce 優化
Combiner的位置和作用
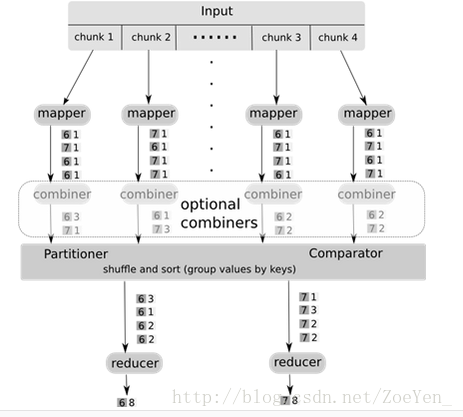
Combiner介於 Mapper和Reducer之間,combine作為 Map任務的一部分,執行完 map 函式後緊接著執行combine,而reduce 必須在所有的 Map 任務完成後才能進行。 而且還可以看出combine的過程與reduce的過程類似,都是對相同的單詞key合併其詞頻,很多情況下可以直接使用reduce函式來完成Combiner過程。
深入理解 Combiner元件:
1、Combiner可以看做區域性的Reducer(local reducer)。
1)Combiner作用是合併相同的key對應的value。
2)在Mapper階段,不管Combiner被呼叫多少次,都不應改變 Reduce的輸出結果。
3)Combiner通常與Reducer的邏輯是一樣的,一般情況下不需要單獨編寫Combiner,直接使用Reducer的實現就可以了。
4)Combiner在Job中是如下設定的。
job.setCombinerClass(Reducer.class);//Combiner一般情況下,預設使用Reducer的實現2.Combiner的好處
1)能夠減少Map Task輸出的資料量(即磁碟IO)。我們前面提到Map Task 將輸出的資料寫到本地磁碟,它輸出的資料量越多,它寫入磁碟的資料量就越大,那麼開銷就越大,速度就越慢。
2)能夠減少Reduce-Map網路傳輸的資料量(網路IO)。這個很好理解,Map Task 輸出越少,Reduce從Map結果中拉取的資料量就越少,自然就減少了網路傳輸的資料量。
3、Combiner 的使用場景
1)並不是所有的場景都可以使用Combiner,必須滿足結果可以累加。
2)適合於Sum()求和,並不適合Average()求平均數。例如,求0、20、10、25和15的平均數,直接使用Reduce求平均數Average(0,20,10,25,15),得到的結果是14, 如果先使用Combiner分別對不同Mapper結果求平均數,Average(0,20,10)=10,Average(25,15)=20,再使用Reducer求平均數Average(10,20),得到的結果為15,很明顯求平均數並不適合使用Combiner。
Partitioner
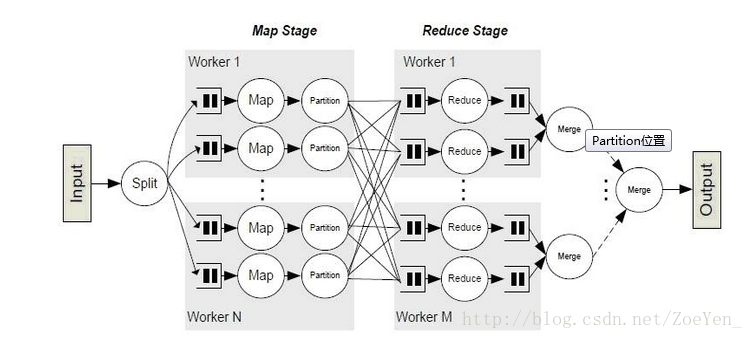
Partitioner 處於 Mapper階段,當Mapper處理好資料後,這些資料需要經過Partitioner進行分割槽,來選擇不同的Reducer處理,從而將Mapper的輸出結果均勻的分佈在Reducer上面執行。
深入理解 Partitioner元件:
1、Partitioner決定了Map Task 輸出的每條資料交給哪個Reduce Task 來處理。Partitioner 有兩個功能:
1)均衡負載。它儘量將工作均勻地分配給不同的 Reduce。
2)效率。它的分配速度一定要非常快。
2、Partitioner 的預設實現:hash(key) mod R,這裡的R代表Reduce Task 的數目,意思就是對key進行hash處理然後取模。很多情況下,使用者需要自定義 Partitioner,比如“hash(hostname(URL)) mod R”,它確保相同域名下的網頁交給同一個 Reduce Task 來處理。 使用者自定義Partitioner,需要繼承Partitioner類,實現它提供的一個方法:
getPartition(Text key, Text value, int numPartitions);前兩個引數分別為Map的key和value。numPartitions 為 Reduce 的個數,使用者可以自己設定。
Partitioner 和 Combiner 先後關係