
Linux下程序相關:fork(),wait(),exec()
1採用命令列操作時,所建立程序的pid編號、程序執行、撤銷過程;
為實現此部分要求,我們編寫一小段程式。它的設計想法是,接收使用者的輸入,直到得到我們需要的輸入,才退出。當我們完成程式程式碼編寫,併成功編譯,執行這段可執行程式時,就建立了一個程序。程序建立後,可以通過ps命令檢視到該程序的資訊。該程式在接收到需要的輸入後正常退出,當然,也可以通過終端強制結束,這也就是程序的撤銷過程。
按照上述的思路,設計的程式程式碼如下:
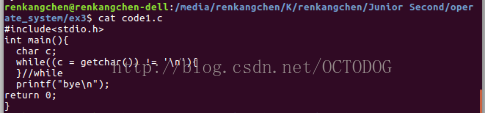
圖1:code1 程式程式碼
編譯執行該程式

圖2:code1 程式的執行
通過在命令列啟動該程式,我們建立了一個程序,此時,通過ps命令來檢視該程序的資訊。

圖3:code1 程序資訊
這裡,我們用到ps命令來進行程序的檢視,這個命令和top命令的區別在於:ps命令像為系統程序資訊拍了張快照,而top命令則像是”現場直播“,也就是說ps得到的是靜態的結果,而top得到的是實時的,動態的結果。
ps命令有許多的引數,常用的引數如下:
|
引數 |
含義 |
|
a |
顯示當前終端機下所有程式 |
|
u |
以使用者為主的格式來顯示程式狀況 |
|
x |
顯示所有的程式,不以終端機為區分 |
|
e |
顯示程式的環境變數 |
|
f |
以ascii字元顯示樹狀結構,顯示程式間的相互關係 |
|
l |
顯示詳細資訊 |
|
c |
顯示程式真正的指令名稱,而不包含路徑,引數等標示 |
表格1:ps命令引數
常用的組合為ps aux ,ps ef,這裡我們使用了ps aux來檢視剛才建立的程序的資訊。使用管道和grep命令結合,以方便檢視。從圖3可以看到,我們建立的程序的pid編號為16588。

圖4:code1的正常執行和退出
從圖4可以看到,我們連續的輸入一串字元,在輸入回車後,程式正常退出,此時再檢視程序資訊

圖5:code1正常退出
從圖5可以看到,程式正常退出後,再次檢視此時系統的程序資訊,此時已經沒有名為code1的程序。
再次執行該code1程式,這次我們使用終端強制終止的方法來結束建立的程序。
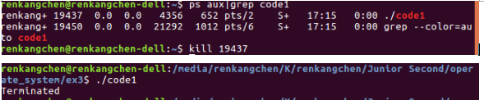
圖6:code1 終結
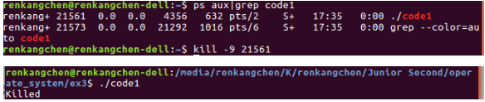
圖7:code1
和之前介紹的類似,我們使用ps命令來檢視code1程序的資訊。通過kill命令來強制終止該程序。
Kill命令可以用來強制終結一個程序,它包含很多可以使用的訊號,但我們一般只會用到15 和 9,通過kill -l可以檢視所有的訊號。訊號15,SIGTERM,這個訊號用來請求停止執行一個程序,但並不是強制停止,程序可以有時間來完成資源釋放等工作後,再停止。和訊號15不同的,訊號9,SIGKILL,這個訊號強制程序立刻停止。Kill命令的使用格式為kill [訊號/選項] PID,預設的訊號是15,如果無效時,可以使用訊號9。
從圖6可以看出,我們使用了kill命令(訊號15)來終結code1,程式提示Terminated,而我們使用帶訊號9的kill命令時,程式提示為,killed。
2採用系統函式呼叫時,程序的pid號、子程序建立前後的變化;
根據實驗指導的提示,編寫此部分的程式。其中關鍵之處為fork()函式的使用。fork()函式通過系統呼叫來建立一個和原程序幾乎一樣的程序。由fork()函式建立的新程序稱為子程序。子程序是父程序的克隆(副本),它可以獲得父程序的資料空間、棧、堆等資源的副本。fork()函式呼叫一次,能夠返回兩次,返回值有以下的三種情況
a 在父程序中返回建立的子程序的PID
b 在子程序中返回0
c 錯誤情況下,返回負值
編譯執行編寫的程式碼,通過檢視執行情況來加深對上述fork()函式相關內容的理解。
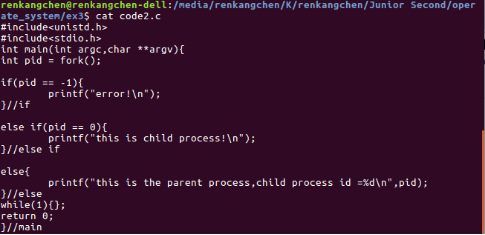
圖8:code2.c

圖9:code2執行情況
從圖9可以看出,在執行code2後,輸出了兩條結果,根據我們之前的學習,這裡顯示了一條父程序的輸出和子程序的輸出。分析這個簡單的程式,不難知道,在我們呼叫fork()函式以前,只有一個程序(父程序)在執行這段程式碼,而在呼叫結束後,這時便由父程序建立了一個新的子程序。子程序和父程序共享程式碼段,在子程序中,fork()返回的值為0,故輸出“this is child process!”。在父程序中,fork()返回的值為子程序的PID,故輸出為“..child process id = 9617”。
在這裡,最開始比較難於理解的便是這個程式的執行結果。因為else if{}和else這是兩句互斥的選擇語句,怎麼也不可能在一個程式執行過程中同時被執行。雖然我們根據實驗指導書知道,該函式呼叫一次,返回兩次,但怎麼返回的,為什麼會輸出兩句,其中的具體細節,請我們還是很模糊。在學習了書中的相關理論後,我們在code2的基礎上增加兩句話。
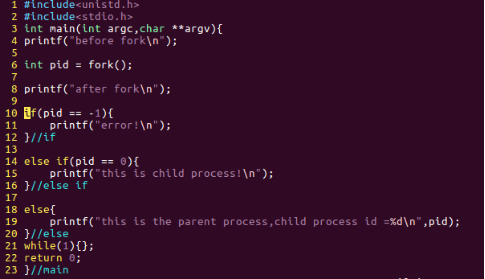
圖10:code2 new
即是如圖10所示中的第4 和第8行處的句子。可以推斷,這個執行code2的結果應該是:
before fork
after fork
this is the parent process,child process id=***
after fork
this is child process!
推出這樣的結果的根據是:在fork()函式之前,是父程序在執行,會輸出一句“before fork”,而一旦執行到fork(),系統會建立和父程序幾乎一樣的子程序,這個時候,父程序和子程序誰先執行就不得而知了,要看系統的排程策略。特別注意的是,fork()建立的子程序是針對父程序執行到fork()時的當前的狀態建立的,也就是說,在這個函式以前的程式碼,是不關子程序的事的。就像兒子沒法時光倒流去幹涉父親十幾歲的事,因為那個時候兒子都還沒出生。而一旦子程序產生,父子倆就分道揚鑣(如圖12所示),各幹各的,這也就是fork()函式為什麼叫fork的原因了。所以,至此,我們最開始的疑惑也就明白了,這不是程式的一次執行,而是對應著兩次執行過程——父子程序,在父程序中選擇分支選擇了else{},而在子程序中選擇分支選擇了else if{}。
圖12:fork示意
我們執行一下修改後的code2:

圖13:code2 new執行結果
從執行結果來看,我們的推斷基本正確。
除了這種方式外,我們還可以通過GDB來程序多程序的除錯。為了使用gdb除錯,我們需要在編譯時候加入除錯選項-g,然後根據實驗指導書的提示,設定多程序除錯模式,並進行相應的除錯工作。
通過ps命令來檢視程序的情況。

圖14:code2程序
可以看到PID為9617的子程序和它的父程序。
3父程序與子程序併發執行(父子程序完成相同計算量的任務,單個任務計算時間大於3秒),分兩種情況:程序數量少於空閒cpu數目、程序數量大於空閒cpu數目兩種情況,比較一個程序完成時間,給出時間差別的解釋。
首先分析第三步我們需要做的事情,首先需要父子程序併發執行,我們知道fork()產生的子程序和父程序就是併發執行的;而在需要完成的計算任務設計上,參考上學期的演算法設計課程,選取一個較為耗時的演算法即可,比如某種排序演算法;我們知道在單處理器上,多程序併發就是實際上就是時間片的輪換利用,而這個輪換也是需要需要時間的,也就是我們的處理機資源只有一個,不能做到“真正的併發”,而在多處理器機器上,多工的多程序併發優勢可以得到很好的體現,因為可以將多個程序分配到不同的處理器上,從而可以提交執行效率,這應該也是為什麼實驗指導中需要我們考慮程序數量和空閒處理器的緣故。在對要求有了一定的瞭解後,下面開始此部分的實驗。
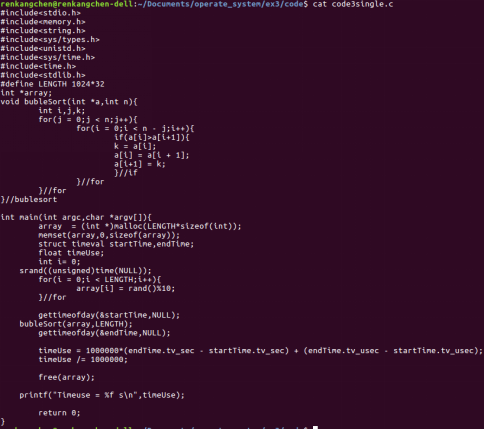
圖15:code3single
圖15展示了一個簡單的排序程式,為了達到單個任務計算時間超過3s的要求,我們使用了較大的資料規模,並用了最簡單也是效率最低的簡單氣泡排序。

圖16:code3single執行結果
圖16展示了我們編寫的code3single的執行時間結果,可以看到,程式完成1024*32個數據的排序,共用時約3.7s。
根據實驗指導書的提示,我們將上面的程式碼修改為父程序建立一個子程序,然後父子程序完成相同計算任務的程式碼。
虛擬碼如下:
//code3.c
begin
pid = fork();
if pid == -1 then
return error;
else if pid == 0 then
sort();
else then
sort();
end
因為程式較為簡單,就不展示完整的程式碼,code3.c和code3signal.c的區別僅僅在於,我們建立了一個子程序,並在父程序和子程序都進行了排序工作。
在執行code3前,檢視cpu的使用情況:
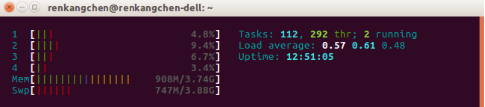
圖17:CPU使用情況
我們通過htop工具來檢視cpu的使用情況,可以看到,實驗機器為4核處理器,且均未完全使用。
接著我們執行code3,也就是此時,空閒cpu數是多於我們的建立的程序數(父程序和子程序,兩個)的。

圖18:code3執行結果
code3的執行結果顯示,不論是父程序還是子程序,執行和code3single同樣的計算任務,時間差別並不是很大,當同時在兩個終端下執行code3和code3single,兩者得到的時間差更小。再來看看,如果我們的建立的程序數多餘空閒的cpu數時,程式執行的情況。
可以通過減少空閒cpu數和增加程序的方法來滿足實驗要求的條件,我們先選擇減少空閒的cpu數,即用其他的計算任務來佔據空閒的CPU資源。
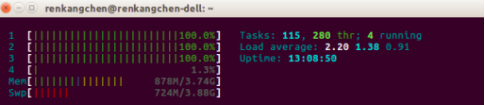
圖19:CPU使用情況2
從圖19可以看到,我們通過執行其他的計算任務,使得,空閒的cpu數為1,也就是圖中看到的,1,2,3號均達到了100%的使用率,這時候,我們再執行code3,看看結果如何。

圖20:code3執行結果2
從圖20的結果來看,此時父程序和子程序的執行時間大概是圖18展示的code3在cpu有較多空閒的情況下的執行時間的三倍。
我們再嘗試增加程序數,比如增加到五個(超過空閒cpu數,4個)。這裡為了增加結果的可靠性,我們併發執行五個子程序,它們完成相同的計算任務,而在父親程序中,我們利用waitpid方法來進行阻塞,父親程序在所有程序完成後,再進行子程序相同的計算任務。
//code3more.c
Begin
int pid1 = fork();
if pid1 == 0 then
sort();
exit();
int pid2 = fork();
if pid2 == 0 then
sort();
exit();
...
waitpid(pid1,NULL,0);
waitpid(pid2,NULL,0);
.....
sort();
End
code3more.c的虛擬碼如上,我們建立了五個子程序,它們會併發執行,多於空閒的cpu數4,而父程序等待子程序完成後,再完成計算任務,當然,此時進行我們計算的程序數(只有父程序)少於空閒CPU數。值得注意的是,我們沒有讓子程序和父程序併發,這裡和題目要求略有差別

圖21:code3more執行結果
如果我們讓父子程序併發,即註釋掉waitpid部分,執行結果如下:
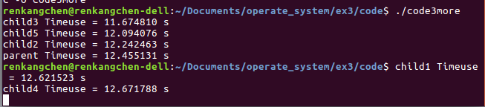
圖22:code3more執行結果2
可以看出,和圖21所示的結果相比較,最大的區別在於,父程序會出現先於子程序完成,子程序變成了孤兒程序,當然,這是我們不太希望看到的,所以,此處根據實際情況,只讓幾個子程序進行併發。
再來看圖21的結果,和圖18cpu空閒狀態下,父子程序併發執行的時間相比,幾個子程序耗費的時間均在9~10s大於圖18中的4s。分析可能的原因是,當cpu空閒數較多的時候,我們的這幾個計算程序不需要進行過多的程序排程,因而完成計算任務花費時間較少,和單個程序的時間幾乎相同,而當我們的計算程序多於空閒cpu數時,發生了較多的程序排程,而程序排程是需要較大的時間開銷的,所以,此時完成計算任務所需的時間就會多些。圖20的結果也說明了這一點,圖20的結果是在我們用其他計算任務佔用cpu,使得空閒cpu數為1的時候得到的,此時會發生的排程會更多,因而時間開銷也略會更大一些。
4父程序等待子程序完成(可以使用阻塞的wait()呼叫),觀察記錄父子程序的就緒和阻塞狀態變化過程(用/proc檢視程序的狀態);
首先使用搜索引擎查閱wait()函式相關的知識。
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int *status);
pid_t waitpid(pid_t pid,int * status,int options);
提到wait函式就不得不談到waipid函式,從系統的角度看,兩個函式的功能是一樣的(只是waitpid多了兩個供使用者選擇的引數),那就是分析當前程序的某個子程序是否已經退出,如果已經子程序退出,wait(或者waitpid)就會收集這個子程序的資訊,並且把它銷燬,然後返回,如果沒有這樣一個子程序,wait(或者waitpid)就會一直阻塞當前程序,直到出現一個這樣的子程序。
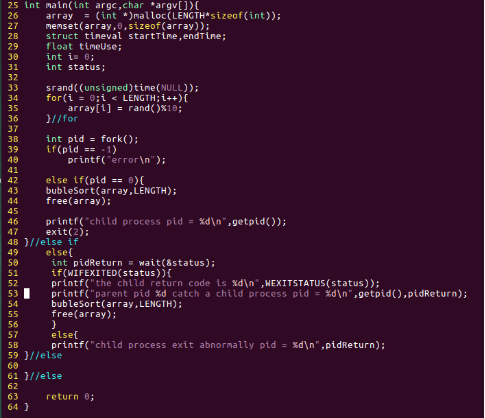
圖23:code4.c程式碼片段
我們直接在code3.c的基礎上,稍微了修改一下,用作本部分的實驗程式碼,所以,僅僅給出主函式部分。在父程序中,呼叫wait()方法,阻塞父程序,此時父程序只有等待子程序完成後,才能就緒,執行。為了便於觀察,我們讓父程序在輸出子程序返回資訊後,繼續執行一段計算程式碼。也就是說,我們看到父程序打印出了子程序的返回資訊時,就知道子程序已近執行完畢,這時父程序應該不再是阻塞狀態了。在子程序的退出時,返回2,在父程序中利用去得到子程序退出時的返回值。這裡用到了兩個巨集,WIFEXITED(int status),當子程序正常退出("exit"或"_exit"),此巨集返回非0;WEXITSTATUS(int status),獲得子程序exit()返回的結束程式碼。

圖24:code4執行結果1
從執行結果可以看到,父程序只有等到子程序執行完成後(獲得了子程序退出時返回的結束程式碼),才能就緒,執行。

圖25:code4 ps結果
我們可以在code4執行時候,使用ps命令簡單地檢視一下父子程序的狀態,可以看到pid號為29270的程序(也就是父程序),是處於S狀態的,而子程序正在執行。當然我們也可以通過/proc來檢視程序的詳細資訊。
執行code4,然後使用命令cat /proc/[pid]/status來檢視對應程序的狀態資訊。
這條命令會返回pid對應的程序(如果存在的話)的詳細資訊,這裡整理處幾個常用的資訊。
|
引數 |
含義 |
|
Name |
應用程式或命令的名字 |
|
State |
任務的狀態,執行/睡眠/僵死/ |
|
Tgid |
執行緒組號 |
|
Pid |
任務ID |
|
Ppid |
父程序ID |
|
VmRSS(KB) |
應用程式正在使用的實體記憶體的大小 |
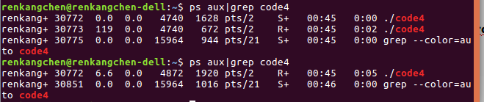
圖26:code4執行2
我們利用ps命令來檢視code4的程序號,這裡也可以看到,在code4剛開始執行時,有兩個程序,程序號分別為30772和30773,其中30772為我們的父程序,此時,它被wait()阻塞,所以是S狀態,子程序30773正處於執行狀態,等到子程序結束後,父程序結束阻塞狀態,就緒,執行,所以,我們可以看到,此時,30772狀態變為R。再來看看,由/proc得到的結果。
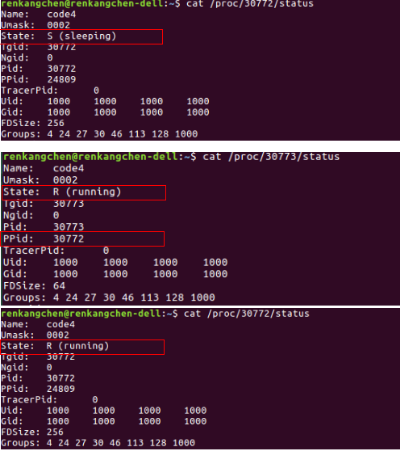
圖27:code4 /proc狀態檢視結果
從圖25可以看出,30772(父程序)剛開始處於S狀態,而此時的子程序30773處於R狀態,圖中圈出,30773的Ppid,也就是是父程序pid為30772。而等到子程序執行完畢,再次檢視30772的狀態,可以看到,變為了R狀態。
5父子程序執行不同的可執行檔案(需要利用exec()呼叫),完成不同功能;
先查閱相關的資料。
Linux中並沒有一個名為“exec”的函式,而是六個以exec開頭的函式族,它們是:
|
標頭檔案 |
#include<unistd.h> |
|
函式原型 |
int execl(const char *path, const char *arg, ...) |
|
int execv(const char *path, char *const argv[]) |
|
|
int execle(const char *path, const char *arg, ..., char *const envp[]) |
|
|
int execve(const char *path, char *const argv[], char *const envp[]) |
|
|
int execlp(const char *file, const char *arg, ...) |
|
|
int execvp(const char *file, char *const argv[]) |
|
|
返回值 |
成功:不返回 |
|
失敗:返回-1 |
表中前四個函式以完整的檔案路徑進行檔案查詢,後兩個以p結尾的函式,可以直接給出檔名,由系統從$PATH中指定的路徑進行查詢。這裡不同的函式字尾,代表著的含義是:
|
字尾 |
含義 |
|
l |
接收以逗號分隔的引數列表,列表以NULL指標作為結束標誌 |
|
v |
接收到一個以NULL結尾的字串陣列的指標 |
|
p |
是一個以NULL結尾的字串陣列指標,函式可以通過$PATH變數查詢檔案 |
|
e |
函式傳遞指定引數envp,允許改變子程序的環境,無後綴e時,子程序使用當前程式的環境 |
值得注意的是:這六個函式中真正的系統呼叫只有execve(),其他的都是庫函式,它們最終都會呼叫到execve();exec函式常常會因為找不到檔案,或者沒有對應檔案的執行許可權等原因而執行失敗,所以,在使用是最好加上錯誤判斷語句。
fork()函式產生的子程序和父程序幾乎一樣,也就是父子程序完成相同的工作,而exec()函式則可以讓子程序裝入或執行其他的程式,也就是可以做和父程序不一樣的事。根據對查閱的資料理解,結合前面部分的實驗,得到本部分的實驗程式碼:
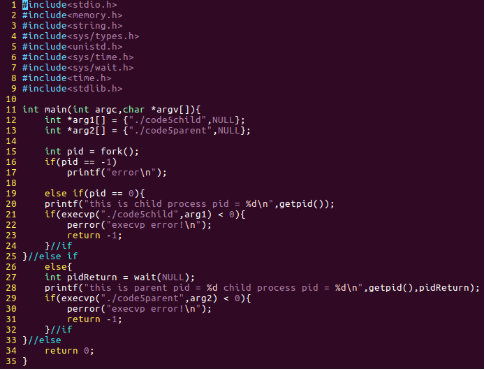
圖28:code5.c程式碼片段
我們在子程序中呼叫了execvp()函式,根據前面的資料,這個函式的第一個引數就是我們呼叫的shell命令或者是要執行的檔案;第二個引數表示這個函式希望接收一個
NULL結尾的字串陣列的指標,我們這裡定義了char *arg1[] = {"./code5child", , NULL},char *arg2[] = {"./code5parent", , NULL};為了便於觀察,我們使用wait()函式,使得子程序執行完畢,父程序再繼續執行。
code5child,code5parent為兩個我們的測試檔案,它們的執行結果為:

圖29:code5child,code5parent執行結果
編譯執行code5

圖30:code5:執行結果
從圖27可以看到,我們讓子程序執行了“./code5child”,列印了一句“this is child here!”;而父程序則沒有做這項工作,它執行了“./code6parent”,列印了一句“this is parent here!”。可以看出,我們通過exec()函式呼叫來實現父子程序執行不同可執行檔案的目的。
當然,我們也可以讓子程序執行一條shell命令,比如下面的圖28所示的結果:
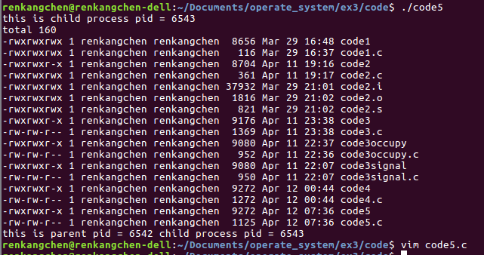
圖31:子程序執行shell命令
6生成3層或以上的父子程序樹,用/proc檔案檢視它們的父子關係。
當父程序呼叫fork()函式的時候,便建立了一個子程序,而父子程序是相對的,也就是子程序中再呼叫fork()時,子程序就建立了它自己的子程序,它是該子程序的父程序。
本部分的實驗程式碼如下:
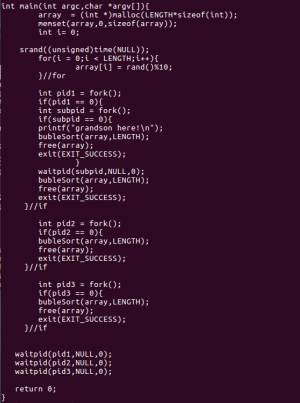
圖32:code6.c程式碼片段
從圖32的程式碼片段可以看出,我們在一個父程序下建立了三個子程序,pid1,pid2,pid3,然後,在pid1下,又建立了一個子程序subpid,它是pid1的子程序,父程序的“孫程序”。
我們先使用pstree命令來檢視樹狀的程序關係。

圖33:pstree得到的程序樹
從圖33的結果可知,我們建立了五個程序,21244有3個子程序,它們是21245,21246,和21248,而21247為21245的子程序。當然,我們也可以使用/proc來檢視程序之間的父子關係,如圖27中展示的那樣。
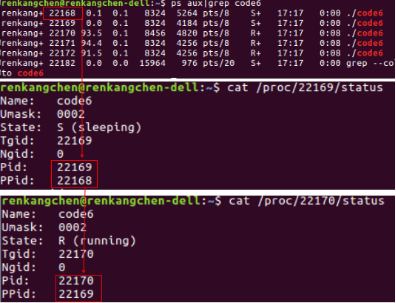
圖34:/proc檢視code6
從圖34可以看出,22168為父程序,它是22169的父程序,22169又是22170的父程序(圖中PPid表示父程序pid號的意思)。
實驗原始碼:連結: https://pan.baidu.com/s/1kV7Jfq3 密碼: itiz