
Mysql全文索引之-深入理解原理
我們前面介紹過mysql全文檢索的一個外掛Onesql,瞭解了全文檢索
其實Mysql的Innodb引擎預設也是支援全文檢索的,只支援英文。其背後的原理都是倒排索引
本文預設Mysql支援的全文檢索
倒排索引
倒排索引跟B+樹一樣,也是一種資料結構。
一般利用關聯陣列,在輔助表中儲存單詞與文件中所在位置的對映。
-- 建立索引 CREATE TABLE test( title VARCHAR(40), FULLTEXT(title) ); -- 插入資料 INSERT INTO test VALUES('Some like it hot, Some like it cold'), ('Some like it in the pot'), ('Nine days old'), ('Pease porridge in the pot'), ('Pease porridage hot, pease porridge cold'), ('Nine days old');
然後檢視一下information_schema下的INNODB_FT_INDEX_TABLE表.如果不允許訪問
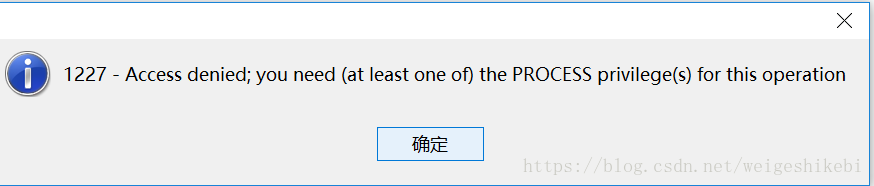
就設定一下:SET GLOBAL innodb_ft_aux_table = 'test/test';
然後再檢視一下INNODB_FT_INDEX_TABLE或者INNODB_FT_INDEX_CACHE表
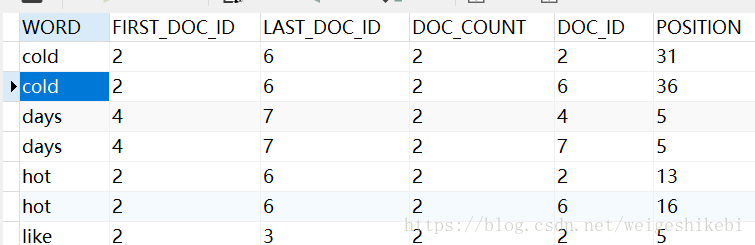
會出現類似的記錄,表明已經建立了對映關係
Innodb採用的是full inverted index的儲存方式。這種方式會佔用更多的空間,因為它不僅會儲存單詞和單詞所在文件的ID,還會儲存單詞所在文件的ID中具體的位置。可以用一個簡單的表格來解釋
| Number | Text | Documents |
| 1 | cold | (2:31),(6:36) |
| 2 | days | (4:5),(7:5) |
| 3 | hot | (2:13),(6:16) |
| 4 | like | (2:5) |
相對的,還有一種儲存方式:inverted file index,只儲存單詞及對應的單詞所在文件。這種理節省空間,但是查詢時,只能根據關鍵字得到相應文件,現進行查詢
分詞
通過上面的例子,我們發現,innodb會把單詞拆分進行儲存,查詢時,根據單詞匹配(預設是英文符號)
- 但是有一些詞,我們可能是不能索引查詢的,比如'to',這稱之為stopword;
-- 預設停止詞 SELECT * FROM information_schema.INNODB_FT_DEFAULT_STOPWORD;
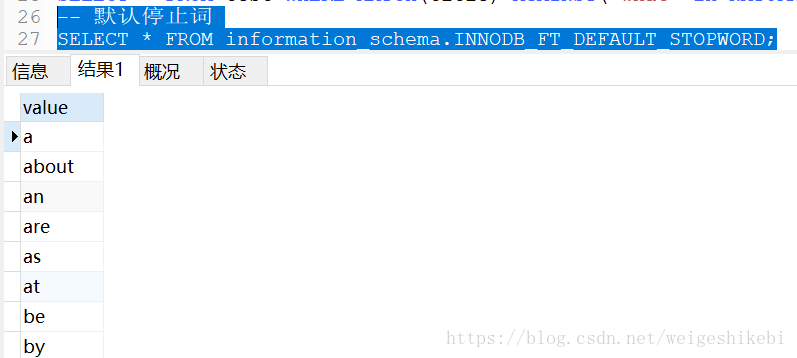
- 或者word的字元長度不在innodb_ft_min_token_size到innodb_ft_max_token_size。預設是3-84個字元區間
INSERT INTO test VALUES
-- 90字元
('123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890'),
-- 80字元
('12345678901234567890123456789012345678901234567890123456789012345678901234567890');插入一個80,90的字元長度,會現在只有80的字元被分詞了:INNODB_FT_INDEX_CACHE表可查,
同理,也只有80的字元記錄被索引
SELECT * FROM test
WHERE MATCH(title) AGAINST('12345678901234567890123456789012345678901234567890123456789012345678901234567890');當然,也可以定製stopword,可以參考mysql stopwords
相關性
如果一個查詢,匹配到多條記錄,是怎麼返回呢?根據相關性
-- 查詢相關性
SELECT title, MATCH(title) AGAINST('like') AS relevance
FROM test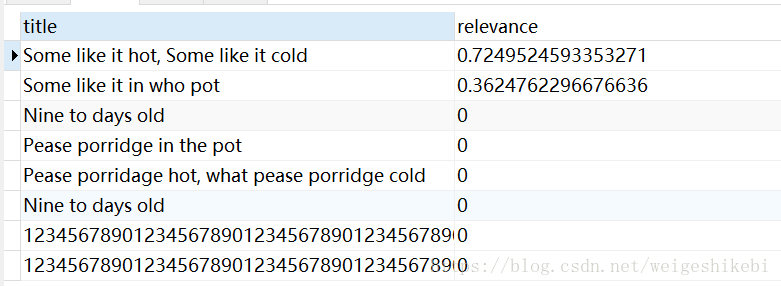
發現只有前面2條記錄的相關性>0,推斷查詢結果就是取相關性>0的記錄,其實也正是如此。那相關性是怎麼計算呢
- word(查詢關鍵字)是否在文件中出現
- word在文件中出現的次數
- word在索引列中的數量
- 多少個文件包含該word
所以Some like it hot, Some like it cold,出現了2次like,相關性高
Some like it in who pot出現了1次,相關性低
而其它記錄沒有相關性
檢索模式
Natural Language
上面的例子我們是用的預設的檢索模式,Natural Language模式!表示查詢帶有指定word的文件。下面2種方式是等價的
SELECT * FROM test WHERE MATCH(title) AGAINST('what' in NATURAL LANGUAGE MODE);
SELECT * FROM test WHERE MATCH(title) AGAINST('what');Boolean
當使用這種模式時,表示字串前後的字元有特殊含義。比如要查詢有Pease單詞的記錄
SELECT * FROM test WHERE MATCH(title) AGAINST('+Pease' in BOOLEAN MODE);
假設,我們需要查詢有Pease,但是沒有hot的記錄呢?用+,-符號,分別表示一定存在,或者一定不存在
SELECT * FROM test WHERE MATCH(title) AGAINST('+Pease -hot' in BOOLEAN MODE);