
Spark-1.6.0中的Sort Based Shuffle原始碼解讀
從Spark-1.2.0開始,Spark的Shuffle由Hash Based Shuffle升級成了Sort Based Shuffle。即Spark.shuffle.manager從Hash換成了Sort。不同形式的Shuffle邏輯主要是ShuffleManager的實現類不同。
在org.apache.spark.SparkEnv類中:
// Let the user specify short names for shuffle managers
val shortShuffleMgrNames = Map(
"hash" -> "org.apache.spark.shuffle.hash.HashShuffleManager" 可以看出,在Spark-1.6.0中可以支援三種模式的Shuffle,分別是hash shuffle,sort shuffle以及tungsten-sort shuffle。預設的是Sort Based Shuffle。
如果需要更改Shuffle型別,需要設定的引數是spark.shuffle.manager,可選的引數有hash,sort(default),tungsten-sort,如果自定義了ShuffleManager型別,比如com.xx.yy.AbcShuffleManager,也可以將該引數設定為com.xx.yy.AbcShuffleManager。SparkEnv會根據配置的引數去查詢該類。
同時,從Spark-1.6.0版本開始,引入了一個動態記憶體分配的功能,該功能預設是開啟的,使用者可以自己選擇是否使用1.6.0之前版本Spark中的記憶體分配策略,通過配置引數spark.memory.useLegacyMode來決定,該引數預設為false。具體可以參考Spark記憶體管理-UnifiedMemoryManager和StaticMemoryManager。
一、Sort Based Shuffle原理
簡單來說,Shuffle過程類似於MR程式中的Map-Reduce過程。可以分為Write和Read兩個階段。
在org.apache.spark.shuffle.sort.SortShuffleManager類的描述中寫道:
在sort-based shuffle中,輸入的records會根據它們key對應的partition ids進行排序,屬於同一partition的記錄不排序。然後將這些記錄輸出到一個map output檔案中。Reducers從該輸出檔案的一個連續檔案片段中讀取屬於它的分割槽的記錄。當map輸出檔案太大記憶體無法裝下時,這些排好序的檔案塊會spill到磁碟上,磁碟上的檔案會最終會合併成一個按分割槽排好序的最終輸出檔案。
Sort-based shuffle的map輸出檔案有兩種輸出方式:
當同時滿足如下三個條件時,以序列化的方式進行排序
1、shuffle過程不需要進行aggregation或者輸出不需要排序
2、shuffle的序列化支援序列化值重新排序(比如KryoSerializer和Spark SQL常用的序列化器)
3、shuffle產生的分割槽數小於16777216個
在上面三個條件之外的情況,都以非序列化的方式進行排序
序列化的排序方式:
在shuffle過程中,當records進入到shuffle writer同時就會被序列化,在整個排序過程中以序列化的形式快取,這種方式的好處是:
1、它的sort操作是在序列化的二進位制資料上完成,而不是Java物件,這樣減少了reduce時的記憶體消耗和GC壓力。但是它會要求序列化器能夠允許序列化的資料在不進行反序列化的操作情況下移動資料位置。
2、它使用了一個ShuffleExternalSorter來對partition id和record pointer進行排序,在ShuffleExternalSorter中對排好序的每一個記錄僅僅只用到8個位元組,所以可以在記憶體中快取更多的記錄。
3、spill過程中會對同一分割槽的序列化好了的記錄在不進行反序列化的情況下進行合併。
4、如果spill過程中的壓縮器支援壓縮資料的合併操作時,spill操作的最後將壓縮好的spill檔案進行合併生成最終spill檔案時就僅僅只需要將每個輸出檔案進行簡單的合併即可。可以避免在merge過程中進行解壓縮和copy操作。
Sort-based Shuffle是在Shuffle過程中有排序的操作,但是這個排序是部分排序。即只根據partition id對每個partition進行排序,但是同一個partition中的記錄並不會被排序。但是如果是sortByKey操作需要對每條記錄進行排序的話的話,各個partition中Record間的排序則在Reducer中完成。也就是說,假如有100條記錄需要進行處理,並且處理後這100條記錄會輸出到10個partition中,假設編號為1~10,那麼只會對1~10這10個輸出分割槽進行排序,同屬於分割槽1的記錄並不會排序。對應下圖中的FileSegment之間會進行排序,但是FileSegment中的記錄不排序。
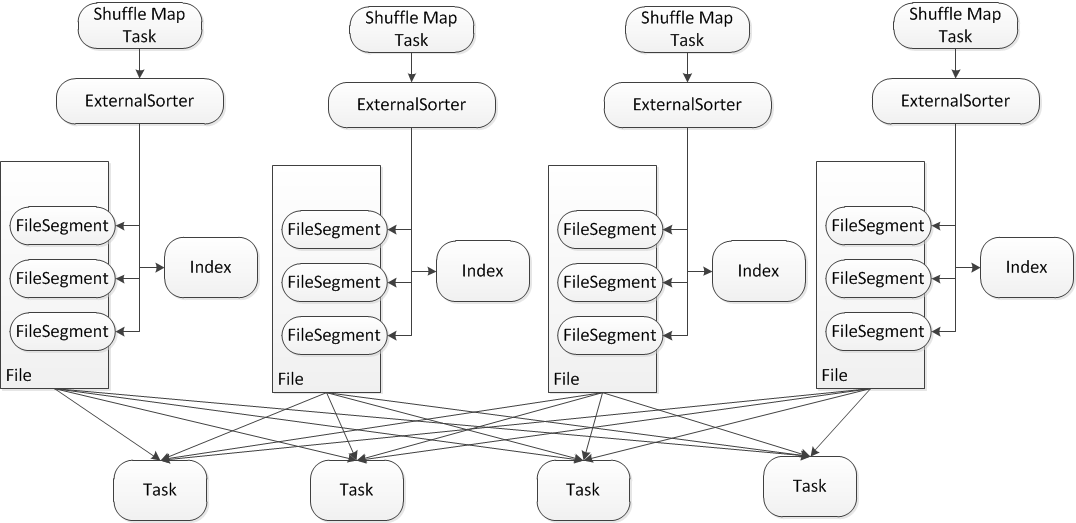
上圖簡單描述了Sort Based Shuffle的過程。每個Shuffle Map Task不會為每個Reducer單獨產生一個檔案,而是一個Map Task只生產一個最終檔案,這個檔案中根據不同partition id進行排序,然後有一個Index引導檔案使得每個Reducer能很快的定位到其需要處理的FileSegment。
二、Sort Based Shuffle Write
先找到Shuffle過程的入口。
1、ShuffleMapTask類
在Scheduler模組中,一個DAG中除了最後一個Stage是FinalStage外,中間依賴的Stage都是ShuffleMapStage,在這個Stage中對應的Task型別都是ShuffleMapTask。ShuffleMapTask在Executor上執行時,最終呼叫的方法是ShuffleMapTask#runTask。
其中主要的程式碼如下
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get從SparkEnv中獲得manager,即上文中提到的org.apache.spark.shuffle.SortShuffleManager。然後由該manager為當前ShuffleMapTask所對應的分割槽生成一個writer物件,這個writer是SortShuffleWriter型別。最後呼叫writer.write方法,將該分割槽迴圈寫出。
2、SortShuffleWriter
SortShuffleWriter#write方法的原始碼如下:
override def write(records: Iterator[Product2[K, V]]): Unit = {
sorter = if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
sorter.insertAll(records)
// Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
val tmp = Utils.tempFileWith(output)
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
} 這裡面前半段主要是生成一個sorter物件,根據是否有mapSideCombine來生成不同的ExternalSorter物件。不做mapSideCombine的話,在構造ExternalSorter時不會傳入聚合函式,也不對這個partition中的記錄進行排序。如果該map task是由sortByKey操作觸發的,那麼根據key的排序會在reduce端進行。
得到sorter物件後,呼叫insertAll方法對records做進一步處理。
Map端Combine
在PairRDDFunctions#combineByKey中我們可以看到:
def combineByKey [C](
createCombiner: V => C,
mergeValue: ( C, V ) => C,
mergeCombiners: ( C, C ) => C,
partitioner: Partitioner ,
mapSideCombine: Boolean = true,
serializer: Serializer = null): RDD[(K , C)] = self.withScope {
combineByKeyWithClassTag(createCombiner, mergeValue, mergeCombiners ,
partitioner , mapSideCombine, serializer)(null)
}
該方法有一個Boolean的傳入值mapSideCombine,並且預設為true。也就是說,在預設情況下呼叫該方法時就會執行mapSideCombine操作了。
mapSideCombine會使一個maptask輸出的值在進行reduce操作之前先進行一定的合併。相當於先對一個分割槽的資料根據傳入引數進行一次reduce操作,這樣資料量會縮減,提高後續shuffle操作從效能。
3、ExternalSorter
(1)map和buffer物件
在ExternalSorter中有兩個比較重要的屬性,map和buffer,這兩個屬性在後面有很重要的作用。定義如下:
private var map = new PartitionedAppendOnlyMap[K, C]
private var buffer = new PartitionedPairBuffer[K, C]雖然分別實現的類是PartitionedAppendOnlyMap和PartitionedPairBuffre,但是在這兩個類的原始碼中還是能夠看出,這兩個類的特性在類名中得到了很好的體現。
對map來說,只會儲存key不同的值,如果遇到相同的key,會把key對應的value進行更新。其底層儲存資料的結構還是一個Array型別的data變數,偶數位存的是key的值,基數位存的是value。當需要更新時,可以看下面這段邏輯,根據k找到其在Array中的位置,然後更新key和value的值。從0位開始,偶數位儲存的是key值,緊隨其後的那位上儲存的是value值。
data(2 * pos) = k
data(2 * pos + 1) = value.asInstanceOf[AnyRef]對buffer來說,遇到的每一個值都會寫入其中。其底層也是維持了一個Array型別的資料結構,但是其插入邏輯如下,在當前Array最後儲存新增的key和value:
data(2 * curSize) = (partition, key.asInstanceOf[AnyRef])
data(2 * curSize + 1) = value.asInstanceOf[AnyRef](2)insertAll(records: Iterator[Product2[K, V]])方法
在該方法中,對有mapSideCombine和沒有mapSideCombine採取了不同的處理方法。
- 有mapSideCombine
// Combine values in-memory first using our AppendOnlyMap
val mergeValue = aggregator.get.mergeValue
val createCombiner = aggregator.get.createCombiner
var kv: Product2[K, V] = null
val update = (hadValue: Boolean, oldValue: C) => {
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
}
while (records.hasNext) {
addElementsRead()
kv = records.next()
map.changeValue((getPartition(kv._1), kv._1), update)
maybeSpillCollection(usingMap = true)
} 迴圈處理records中的每一條記錄,處理一條記錄就在addElementsRead()中將_elementsRead加1,記錄處理的記錄數,然後更新map中的值。這裡傳入的update是一個方法,進行map端的combine操作,如果遇到記錄過的相同key,就將value使用傳入的aggregator進行聚合,如果遇到一個新key,就將該key對應的value計入一個新的combiner中。
PartitionedAppendOnlyMap的類繼承關係,及如下圖changeValue的呼叫如下圖:
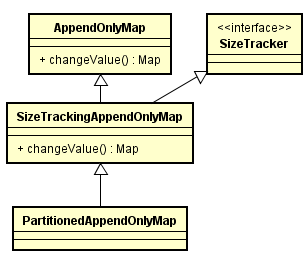
該方法最終進入AppendOnlyMap#changeValue方法中,按照在3.(1)提到的data物件進行更新。每次更新完一條記錄後,會對該記錄進行判斷,滿足抽樣條件的話就會進行一次抽樣。這裡的抽樣過程主要是為了後續判斷該data使用的記憶體大小所用,在後面會有詳細介紹。
- 沒有mapSideCombine
這裡的主要邏輯是:
while (records.hasNext) {
addElementsRead()
val kv = records.next()
buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C])
maybeSpillCollection(usingMap = false)
}仍然是迴圈取出records中的每一條記錄。取出一條便將_elementsRead加1,然後將資料存入上面的buffer變數中。buffer.insert方法處理過程如下:
/** Add an element into the buffer */
def insert(partition: Int, key: K, value: V): Unit = {
if (curSize == capacity) {
growArray()
}
data(2 * curSize) = (partition, key.asInstanceOf[AnyRef])
data(2 * curSize + 1) = value.asInstanceOf[AnyRef]
curSize += 1
afterUpdate()
} curSize記錄當前data物件中儲存記錄的個數,插入一條記錄就會加1。capacity是當前data中能夠儲存的記錄總個數。data的初始長度是2 * 64,即能儲存64個record的key-value對。data中儲存record的上限是2^30 -1個,當不超過該上限時,growArray方法會以當前capacity兩倍(但是最多達到上限)容量建立一個新的data陣列將原來data中的資料copy到新陣列中,同時會對新的data進行取樣。有關取樣的過程及用途,在後面記憶體分析時會講到。
然後直接在data最後新增兩位儲存新的key和value值,更新curSize。每插入一條記錄最後呼叫afterUpdate方法,對當前data中的記錄進行一次判斷是否需要進行一次取樣。
(3)maybeSpillCollection判斷是否需要spill
在(2)中insertAll方法對map和buffer進行更新後,接下來就會呼叫maybeSpillCollection方法決定map和buffer是否需要進行spill。
/**
* Spill the current in-memory collection to disk if needed.
* * @param usingMap whether we're using a map or buffer as our current in-memory collection
*/
private def maybeSpillCollection(usingMap: Boolean): Unit = {
var estimatedSize = 0L
if (usingMap) {
estimatedSize = map.estimateSize()
if (maybeSpill(map, estimatedSize)) {
map = new PartitionedAppendOnlyMap[K, C]
}
} else {
estimatedSize = buffer.estimateSize()
if (maybeSpill(buffer, estimatedSize)) {
buffer = new PartitionedPairBuffer[K, C]
}
}
if (estimatedSize > _peakMemoryUsedBytes) {
_peakMemoryUsedBytes = estimatedSize
}
} 傳入引數usingMap是用來標識使用的是map還是buffer物件,對前面有印象的話應該知道使用map物件還是buffer物件是由有沒有mapSideCombine來決定的,由於map和buffer物件底層還是一個Array型別的data物件,只是對資料更新和插入的處理方式有些不同。所以接下來都以buffer來作進一步的分析。
這裡的主要邏輯是,首先呼叫buffer的estimateSize方法,計算當前buffer物件的記憶體大小estimatedSize,然後根據該大小呼叫方法maybeSpill判斷是否需要進行spill操作,spill後會把buffer清空,重新進行下一輪的操作。那麼接下來就有兩個重點:計算buffer的大小和判定是否需要spill。
- buffer.estimateSize方法計算記憶體
PartitionedPairBuffer和PartitionedAppendOnlyMap都繼承了trait SizeTracker。所以,不管是map還是buffer呼叫的estimateSize都是相同的。
應該還記得前面提到過對buffer插入資料時,會有一個取樣的操作。有關取樣的相關過程也在SizeTracker中。
SizeTracker中的屬性:
private val samples = new mutable.Queue[Sample]//一個佇列,用於儲存對資料的取樣樣本
private val SAMPLE_GROWTH_RATE = 1.1//取樣間隔次數增長率
private var bytesPerUpdate: Double = _//根據samples中最後兩個樣本計算出的記錄記憶體平均增長率
private var numUpdates: Long = _//buffer的更新次數
private var nextSampleNum: Long = _//下一次取樣操作的次數
......
case class Sample(size: Long, numUpdates: Long) 在上面的程式碼片段中有一些屬性和Sample類結構。這些在estimateSize方法中都有用到。在Spark中,對shuffle過程資料的記憶體大小,是根據取樣樣本的大小來估算的。
從前面我們知道,buffer中每插入一條記錄都會判斷是否需要取樣,在SizeTracker#afterUpdate方法中取樣的依據是當前buffer的更新次數numUpdates是否等於下一次進行取樣操作的次數nextSampleNum,如果等於,則呼叫SizeTracker#takeSample方法進行一次取樣,然後nextSampleNum變成ceil(numUpdates * SAMPLE_GROWTH_RATE)。然後根據samples中最後兩個樣本計算出buffer每次更新的記憶體平均增長率bytesPerUpdate = (latest.size - previous.size).toDouble / (latest.numUpdates - previous.numUpdates)。從這裡可以看出,當buffer中記錄比較少時,取樣非常頻繁,但是如果該buffer中容納的記錄越多,到後面進行一次取樣的間隔次數就會越多。
估算的記憶體大小為:
def estimateSize(): Long = {
assert(samples.nonEmpty)
val extrapolatedDelta = bytesPerUpdate * (numUpdates - samples.last.numUpdates)
(samples.last.size + extrapolatedDelta).toLong
} 由samples中最後一個樣本的大小,加上buffer記錄距離上次取樣的次數numUpdates - samples.last.numUpdates,乘以buffer每次新增一個record時的記憶體平均增長率bytesPerUpdate。這樣可以在最短的時間內對儲存了大量record的buffer記憶體佔用大小進行計算,但是由於是基於取樣的方法估算的記憶體大小,有時候會由於資料本身的問題導致計算不準確等問題。有可能偶爾出現OOM的情況。
- maybeSpill方法判斷是否進行spill
在Spark-1.6之前,可以由引數spark.shuffle.spill設定為true或者false來選擇開啟或者關閉記憶體資料spill到磁碟的功能,但是在1.6版本中,該引數預設為true,並且即使設定為false,也不會起作用了,spark在需要時會把記憶體資料spill到磁碟。
根據上一步估算到的當前map或buffer的記憶體大小estimatedSize,如果達到spill的條件,將該map或者buffer中的資料spill到磁碟,然後重新初始化一個新的map或buffer,在下面maybeSpill方法中傳入引數c就是當前的buffer物件,currentMemory是上一步估算的buffer佔用的記憶體大小estimateSize。
protected def maybeSpill(collection: C, currentMemory: Long): Boolean = {
var shouldSpill = false
//buffer中每插入32條記錄,並且當前估算的buffer記憶體達到了spill的記憶體閾值
if (elementsRead % 32 == 0 && currentMemory >= myMemoryThreshold) {
// Claim up to double our current memory from the shuffle memory pool
val amountToRequest = 2 * currentMemory - myMemoryThreshold
val granted =
taskMemoryManager.acquireExecutionMemory(amountToRequest, MemoryMode.ON_HEAP, null)
myMemoryThreshold += granted
// If we were granted too little memory to grow further (either tryToAcquire returned 0,
// or we already had more memory than myMemoryThreshold), spill the current collection
shouldSpill = currentMemory >= myMemoryThreshold
}
shouldSpill = shouldSpill || _elementsRead > numElementsForceSpillThreshold
// Actually spill
if (shouldSpill) {
_spillCount += 1
logSpillage(currentMemory)
//ExternalSorter#spill方法
spill(collection)
_elementsRead = 0
_memoryBytesSpilled += currentMemory
releaseMemory()
}
shouldSpill
} 雖然前面記憶體估算是基於取樣來進行的,但是如果對buffer中每新增一條記錄就判斷一次是否需要spill肯定是一個很耗費時間與資源的過程。從上面的程式碼可以看出,根據buffer中插入記錄的數目elementRead,每32次並且如果estimateSize達到了spill的記憶體閾值myMemoryThreshold才會判斷是否spill。myMemoryThreshold由引數spark.shuffle.spill.initialMemoryThreshold(預設值5 * 1024 * 1024,5MB)來確定。
如果同時滿足上面兩個條件,就會向taskMemoryManager申請,申請的是Execution部分的記憶體。這裡的taskMemoryManager,以及記憶體申請的過程,可以參考文章Spark記憶體管理-UnifiedMemoryManager和StaticMemoryManager,如果記憶體不足,則分配到的記憶體granted為0。申請的記憶體總數是amountToRequest,計算公式是amountToRequest = 2 * currentMemory - myMemoryThreshold。這裡可以把myMemoryThreshold理解為當前Executor可提供給當前shuffle操作的最少記憶體數,每隔32次插入資料,如果當前buffer使用的記憶體數仍然比myMemoryThreshold小,那麼myMemoryThreshold就可以繼續寫入記錄,直到記憶體使用量超過myMemoryThreshold時才會嘗試向taskMemoryManagre申請記憶體,申請到記憶體後,myMemoryThreshold就會增大,增大後,如果仍然不足以儲存新插入資料的buffer,那麼就會觸發spill操作。對buffer來說,每次spill都會重新初始化一次,那麼上一次spill時buffer中的所有資料,可以是32次,64次,96次…插入後的結果,最壞的情況是32次插入就會導致currentMemory > myMemoryThreshold如果此次不spill,Spark會認為下次再經過32次插入後,buffer的currentMemory會翻番,所以向Execution記憶體池申請能夠儲存2 * currentMemory記憶體的空間。申請到記憶體後,將granted累加到myMemoryThreshold上,如果分配到的記憶體太少,即使加上新分配的記憶體,myMemoryThreshold仍然不足currentMemory,就會觸發spill操作。
觸發spill操作的另一個條件是_elementsRead > numElementsForceSpillThreshold,,當前buffer中的記錄數超過引數spark.shuffle.spill.numElementsForceSpillThreshold(預設值是Long.MaxValue)。
在觸發spill操作後,spill次數_spillCount累加,並記錄此次spill出去的資料大小。呼叫spill方法進行spill操作,然後通過releaseMemory方法把Execution記憶體池的ON_HEAP記憶體釋放,重置myMemoryThreshold為引數設定值。繼續進行下一輪。
4、Sort Based Shuffle Write記憶體分析
這個過程中最耗記憶體的物件是上面的map或者buffer,這部分記憶體再加上spill操作時的快取記憶體基本上就構成了Shuffle Wtire過程中整個記憶體的使用情況。
buffer中的記憶體大小是上面提到的PartitionedAppendOnlyBuffer佔用的實際記憶體大小,如果一個Executor有C個Core,則C個Core共享整個Executor的記憶體,並且同時處理Task,所以buffer部分所有記憶體大小為C * PartitionedAppendOnlyBuffer。
在spill過程中,呼叫的是ExternalSorter#spill方法,我們來看一下spill的過程,
首先由diskBlockManager建立一個shuffle臨時檔案,生成blockId和file,
val (blockId, file) = diskBlockManager.createTempShuffleBlock()blockId和file如下圖所示:

然後獲取一個往磁碟寫臨時檔案的DiskBlockObjectWriter型別的diskWriter物件,
writer = blockManager.getDiskWriter(blockId, file, serInstance, fileBufferSize, spillMetrics)writer並不是接收到一條記錄就往磁碟寫一條記錄,在裡面有一個fileBuffer來快取,每裝滿一次才會真正往磁碟spill一次,這個fileBufferSize的大小可以由引數spark.shuffle.file.buffer(預設值為32K)來確定。
同時,在spill的過程中,每接收一條記錄寫入fileBuffer中的同時,也會記錄fileBuffer中的記錄數objectsWritten。每一個batch的資料寫入磁碟時需要進行序列化,為了避免序列化過程中出現記憶體不足的情況,對每一個batch中的記錄數也作了一個限制spark.shuffle.spill.batchSize(預設為10000),這個引數不宜設定為過小,太小的話頻繁的序列化反序列化也是很耗費時間的。可以隨著上面的file.buffer一起增大或減小。每寫滿10000條記錄,上面程式碼中的writer物件會呼叫flush方法往磁碟寫入一次,然後重新生成一個writer物件。
最後在spills變數中記錄每次spill的相關記錄
private val spills = new ArrayBuffer[SpilledFile]在本次除錯過程中,spills中的內容如下:
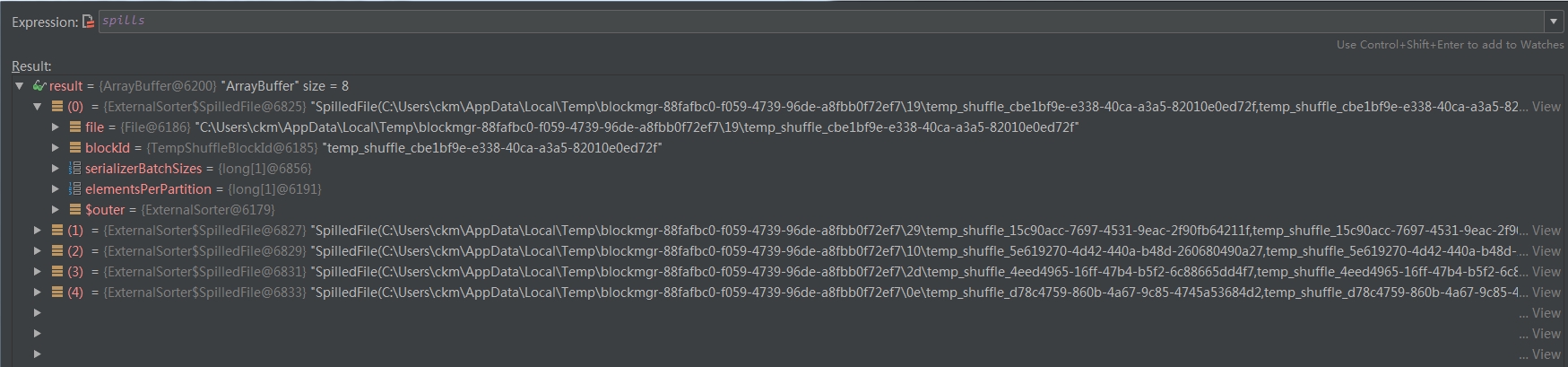
對應spill到磁碟上的檔案:

三、Sort Based Shuffle Read
Sort Based Shuffle Read類似於Write過程,從獲取Reader物件開始。
1、ShuffledRDD
read過程從ShuffledRDD#compute方法開始,首先獲取Reader物件。
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
} 從前面提到的SortShuffleManager類的getReader獲取到Reader物件後呼叫read方法開始讀取shuffle write過程中spill到磁碟的臨時檔案。
Reader物件是BlockStoreShuffleReader型別。
2、BlockStoreShuffleReader
接下來進入BlockStoreShuffleReader#read方法中。
override def read(): Iterator[Product2[K, C]] = {...}該方法最終返回一個Iterator物件,這個Iterator物件會經過下面一系列的轉換:
var blockFetcherItr = new ShuffleBlockFetcherIterator(...)
val wrappedStreams = blockFetcherItr.map { ... }
val recordIter = wrappedStreams.flatMap { ... }
val metricIter = CompletionIterator[(Any, Any), Iterator[(Any, Any)]] (...)
val interruptibleIter = new InterruptibleIterator[(Any, Any)](context, metricIter)經過上面程式碼中的一系列變換後,最後得到一個aggregatedIter變數。接下來重點分析該變數中的過程。
val aggregatedIter: Iterator[Product2[K, C]] = if (dep.aggregator.isDefined) {
if (dep.mapSideCombine) { //如果需要進行map端combine
// 獲得的是已經聚合了的記錄
val combinedKeyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, C)]]
dep.aggregator.get.combineCombinersByKey(combinedKeyValuesIterator, context)
} else { //不需要map端combine
val keyValuesIterator = interruptibleIter.asInstanceOf[Iterator[(K, Nothing)]]
dep.aggregator.get.combineValuesByKey(keyValuesIterator, context)
}
}在上面的過程中,對於有map端combine的讀入記錄,由於在map時已經對相同key的值進行了一定的處理,所以得到的combinedKeyValuesIterator物件是一個Value不為空的iterator,接下來呼叫Aggregator#combineCombinersByKey,而對於沒有map端combine的記錄,combinedKeyValuesIterator物件的Value為Nothing,接下來呼叫Aggregator#combineValuesByKey方法。
(1)Aggregator#combineCombinersByKey和Aggregator#combineValuesByKey
在combineCombinersByKey方法中
def combineCombinersByKey(
iter: Iterator[_ <: Product2[K, C]],
context: TaskContext): Iterator[(K, C)] = {
val combiners = new ExternalAppendOnlyMap[K, C, C](identity, mergeCombiners, mergeCombiners)
combiners.insertAll(iter)
updateMetrics(context, combiners)
combiners.iterator
}在combineValuesByKey方法中
def combineValuesByKey(
iter: Iterator[_ <: Product2[K, V]],
context: TaskContext): Iterator[(K, C)] = {
val combiners = new ExternalAppendOnlyMap[K, V, C](createCombiner, mergeValue, mergeCombiners)
combiners.insertAll(iter)
updateMetrics(context, combiners)
combiners.iterator
}上面兩個方法,首先獲得一個ExternalAppendOnlyMap型別的combiners變數,然後呼叫combiners.insertAll方法處理讀入記錄。上面兩個方法中的不同之處在於,構造ExternalAppendOnlyMap時的傳入引數不同。
(2)ExternalAppendOnlyMap
在ExternalAppendOnlyMap#insertAll方法中會將Shuffle Read讀取的記錄,插入一個currentMap物件中
private var currentMap = new SizeTrackingAppendOnlyMap[K, C]
private val spilledMaps = new ArrayBuffer[DiskMapIterator]
......
spilledMaps.append(new DiskMapIterator(file, blockId, batchSizes)) 這個SizeTrackingAppendOnlyMap在前面shuffle write中也提到過,是PartitionedAppendOnlyMap的父類。接下來的過程也與shuffle write過程類似,當currentMap申請不到足夠的記憶體時,就會觸發spill操作,伴隨著每一次的spill,會有一個ArrayBuffer型別的spilledMaps記錄每次spill到磁碟上的檔案的詳細資訊。和writer過程的spill不同的是,shuffle read的每次spill都會將記憶體中的記錄排好序,具體程式碼可以參考ExternalSorter#spill方法。
combine完成後,返回一個iterator給前面程式碼中的aggregatedIter變數。aggregatedIter的型別由當前shuffle read過程是否發生過spill行為來決定。
if (spilledMaps.isEmpty) {
CompletionIterator[(K, C), Iterator[(K, C)]](currentMap.iterator, freeCurrentMap())
} else {
new ExternalIterator()
}如果發生過spill,那麼aggregatedIter的型別是ExternalIterator的,這個型別的iterator會將spill到磁碟上的資料以及記憶體中的資料進行合併。如果沒有發生過spill,由於資料都在記憶體中,所以只需要一個CompletionIterator讀取記憶體中的資料就行。
(3)ExternalIterator型別
ExternalIterator型別是ExternalAppendOnlyMap的內部類。由於涉及到處理spill到磁碟上的資料,以及記憶體中的資料,過程比較複雜,所以接下來會對這個型別進行梳理。
在這個類中,唯一一個耗費記憶體資源的是mergeHeap優先佇列,
private val mergeHeap = new mutable.PriorityQueue[StreamBuffer]這個StreamBuffer是ExternalIterator的內部類,每個StreamBuffer物件中儲存了on-disk或者in-memory資料流中的所有資料。StreamBuffer的建構函式中iterator是用來構造該StreamBuffer物件的資料流中資料的引用,pairs儲存的是這個iterator中key的hash值最小的那一組key-value,如果存在hash衝突的話,pairs中儲存的則是hash值相同的多組key-value對。
private class StreamBuffer(
val iterator: BufferedIterator[(K, C)],
val pairs: ArrayBuffer[(K, C)])
extends Comparable[StreamBuffer] StreamBuffer實現了Comparable#compareTo方法,兩個StreamBuffer物件的大小通過比較pairs中第一個值(即某個key值)的hash值大小來確定。
在ExternalIterator中,會將currentMap中的記錄在記憶體中進行排序,然後將spill到磁碟上的檔案spilledMaps載入進來。
對in-memory的SizeTrackingAppendOnlyMap物件currentMap的排序,實現方法在AppendOnlyMap#destructiveSortedIterator中。將currentMap的底層實現data陣列中的記錄,null值全部後移之後,呼叫TimSort#sort方法進行排序。
(4)CompletionIterator型別
是一個抽象類,其中有一個未實現的completion方法。
abstract class CompletionIterator[ +A, +I <: Iterator[A]](sub: I) extends Iterator[A] {
// scalastyle:on
private[this] var completed = false
def next(): A = sub.next()
def hasNext: Boolean = {
val r = sub.hasNext
if (!r && !completed) {
completed = true
completion()
}
r
}
def completion(): Unit
}
private[spark] object CompletionIterator {
def apply[A, I <: Iterator[A]](sub: I, completionFunction: => Unit) : CompletionIterator[A, I] = {
new CompletionIterator[A, I](sub) {
def completion(): Unit = completionFunction
}
}
}在構造CompletionIterator型別的物件時,會同時傳入一個completionFunction方法,如前面程式碼所示,傳入的是currentMap.iterator。