
Spark單機與叢集安裝與簡單命令列使用
參考自書籍《Hadoop+Spark 大資料巨量分析與機器學習》
環境依賴:
jdk 1.7
scala 2.11.6
spark 2.1.2
1 安裝scala
$ wget https://www.scala-lang.org/files/archive/scala-2.11.6.tgz $ tar xvf scala-2.11.6.tgz $ sudo mv scala-2.11.6 /usr/local/scala //新增scala環境變數 $ vim ~/.bashrc //新增如下內容 #SCALA export SCALA_HOME=/usr/local/scala export PATH=$PATH:$SCALA_HOME/bin $ source ~/.bashrc //使其生效
2 測試scala
$ scala
3 安裝Spark
檢視hadoop版本 $ hadoop version //我這裡是2.8.4 選擇對應版本安裝spark(下載官網) $ wget https://archive.apache.org/dist/spark/spark-2.1.2/spark-2.1.2-bin-hadoop2.7.tgz $ tar zxf spark-2.1.2-bin-hadoop2.7.tgz $ sudo mv spark-2.1.2-bin-hadoop2.7 /usr/local/spark //新增spark環境變數 $ vim ~/.bashrc //新增如下內容 #SPARK export SPARK_HOME=/usr/local/spark export PATH=$PATH:$SPARK_HOME/bin $ source ~/.bashrc //使其生效
4 啟動spark-shell互動介面
$ spark-shell
5 設定spark-shell顯示資訊
$ cd /usr/local/spark/conf
$ cp log4j.properties.template log4j.properties
$ sudo vim log4j.properties
將log4j.rootCategory=INFO 改為 WARN
$ spark-shell //然後就發現現實的東西少了很多,沒這麼礙眼
6 啟動hadoop然後本地執行spark-shell

讀取HDFS檔案
> val textFile=sc.textFile("hdfs://192.168.80.100:9000/user/hduser/wordcount/input/LICENSE.txt") //這裡ip是對應master,可見hadoop core-site.xml配置 > textFile.count
7 Hadoop YARN執行spark-shell
$ SPARK_JAR=/usr/local/spark/yarn/spark-2.1.2-yarn-shuffle.jar HADOOP_CONF_DIR=/home/hadoop/hadoop/etc/hadoop MASTER=yarn-client /usr/local/spark/bin/spark-shell然後可見下面scala>提示符
讀取本地檔案
scala>
> val textFile=sc.textFile("file:/home/hadoop/hadoop/LICENSE.txt");
> textFile.count讀取hdfs檔案
> val textFile=sc.textFile("hdfs://192.168.80.100:9000/user/hduser/wordcount/input/LICENSE.txt") //這裡ip是對應master,可見hadoop core-site.xml配置
> textFile.count然後訪問:http://192.168.80.100:8088/cluster/apps,顯示如下(192.168.80.100是hadoop的master的伺服器ip)
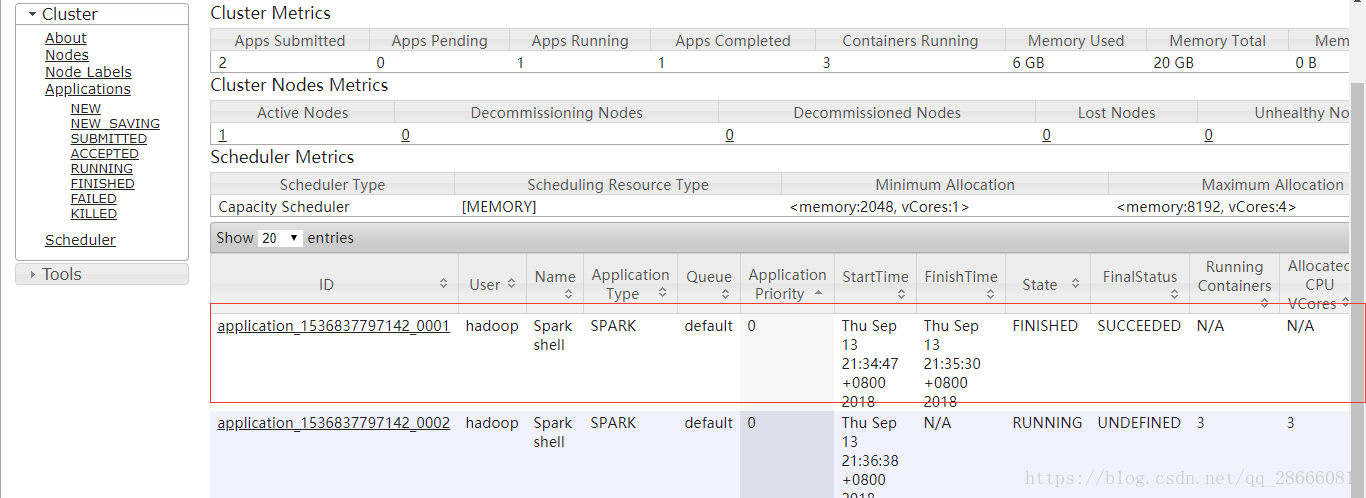
8 構建Spark Standalone Cluster執行環境
//在master虛擬機器中設定spark-env.sh
$ cp /usr/local/spark/conf/spark-env.sh.template /usr/local/spark/conf/spark-env.sh
$ sudo vim /usr/local/spark/conf/spark-env.sh //新增如下內容
export SPARK_MASTER_IP=192.168.80.100 #設定master的ip或伺服器名稱 這裡對應hosts中的master
export SPARK_WORKER_CORES=1 #設定每個worker使用的cpu核心
export SPARK_WORKER_MEMORY=500m #設定每個worker使用記憶體 --800m推薦
export SPARK_WORKER_INSTANCES=2 #設定多個worker例項然後拷貝到對應的hadoop slave伺服器
$ ssh 192.168.80.101 //slave1伺服器
$ sudo mkdir /usr/local/spark
$ sudo chown hadoop:hadoop /usr/local/spark
$ exit;
//退出後回到master伺服器
$ sudo scp -r /usr/local/spark [email protected]:/usr/local //遠端拷貝spark到slave伺服器
$ cp /usr/local/spark/conf/slaves.template /usr/local/spark/conf/slaves
$ vim /usr/local/spark/conf/slaves //編輯並新增你的slave伺服器ip
192.168.80.101在spark standalone執行spark-shell
$ /usr/local/spark/sbin/start-all.sh //然後就可以看到啟動了1個master、2個worker
$ /usr/local/spark/sbin/start-master.sh -h 192.168.80.100
$ /usr/local/spark/sbin/start-slave.sh spark://192.168.80.100:7077
-------------以下是可不操作命令------------------
$ /usr/local/spark/sbin/start-master.sh //啟動master服務
$ /usr/local/spark/sbin/start-slaves.sh //啟動slaves服務
$ /usr/local/spark/sbin/stop-all.sh //停止所有服務注:為什麼是兩個ip192.168.80.101的worker,衛視在spark-env.sh設定了SPARK_WORKER4_INSTANCES=2,所以一個從伺服器會產生兩個例項。
在spark standalone中執行spark-shell程式
$ spark-shell --master spark://192.168.80.100:7077然後開啟web輸入 http://192.168.80.100:8080可見如下:
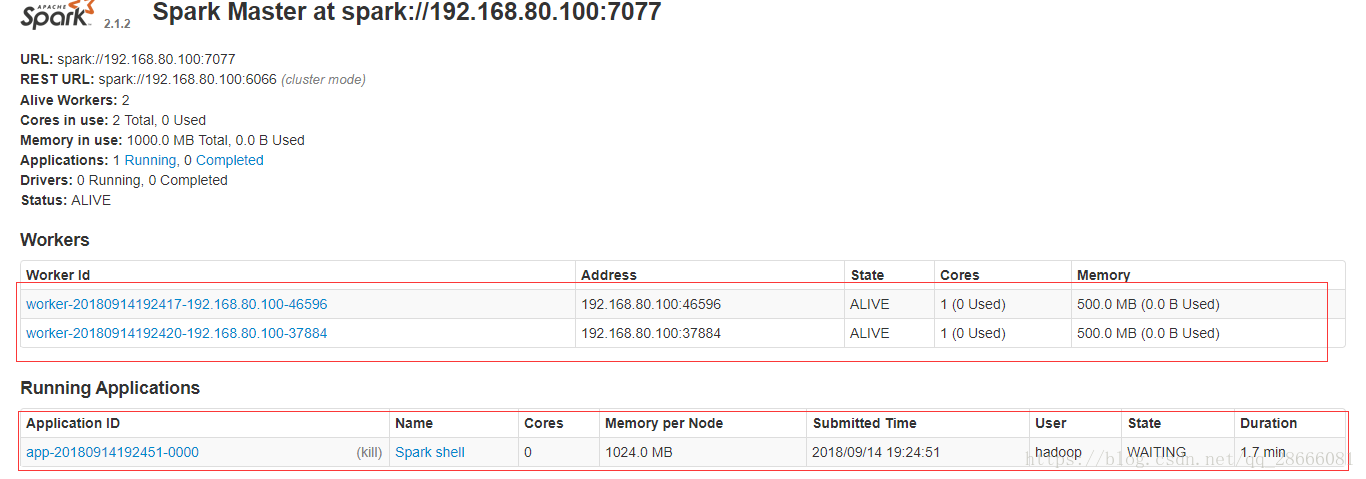
相關推薦
Spark單機與叢集安裝與簡單命令列使用
參考自書籍《Hadoop+Spark 大資料巨量分析與機器學習》 環境依賴: jdk 1.7 scala 2.11.6 spark 2.1.2 1 安裝scala $ wget https://www.scala-lang.org/files/archiv
對於mongodb在linux上的的安裝與其簡單命令列操作的學習回顧
今天培訓主要學習了MongoDB的安裝與簡單操作以及關於NoSQL的一點概念性的知識,在此對所操作的MongoDB命令進行簡單回顧 1.MongoDB的安裝 與網上的教程無太多出入,Linux系統下直接通過終端輸入命令列 sudo apt-get install m
Kubernetes學習系列之簡單叢集安裝與配置
環境配置 CentOS Linux release 7.3.1611 (Core) etcd-v3.2.6 docker-ce-17.03.2.ce kubernetes-v1.6.9 192.168.108.128 節點1 192.168.108.129 節點2 19
spark叢集安裝與配置
Spark有三種執行模式,分別為: local模式-只執行在本地,相當於偽分散式 standalone模式-這種模式只需要安裝Spark即可,使用自帶的資源管理器 Spark on yarn/mesos模式-這種模式Spark將使用yarn/mesos作為資源管理器 一般來
Spark 2.2.0 安裝與配置
mem p s template .sh org uri 文件 圖片 with 下載Spark 解壓並移動到/software目錄: tar -zxvf spark-2.2.0-bin-without-hadoop.tgz mv spark-2.2.0-bin-withou
MySQL Galera 叢集安裝與配置
galera 叢集概述與搭建 Galera replication原理 從客戶端看整體的流程 其中對應的角色分為2個:協調者和參與者 協調者: 1、 接收客戶端請求 2、 廣播請求到其他參與者(包括自己) 3、 作為參與者進行資料更新 4、 更新失敗
Linux(centos7) Elasticsearch6.5叢集安裝與Kibana視覺化
必須要先安全JDK1.8或以上版本,記憶體配置1G以上,最好2G https://www.elastic.co/cn/downloads/elasticsearch#ga-release 官網下載tar 上傳到linux 解壓 tar -zxvf elasticsearch-
redis3.0.0 叢集安裝與整理總結
叢集搭建 http://blog.csdn.net/xu470438000/article/details/42971091 redis window安裝與使用 遠端連線 1) 預設無許可權控制: 遠端服務連線: $ redis-cli -h 127.0.0.1
storm概述、叢集安裝和簡單的命令列操作
http://storm.apache.org Apache Storm是一個免費的開源分散式實時計算系統。Storm可以輕鬆可靠地處理無限資料流,實現Hadoop對批處理所做的實時處理。Storm非常簡單,可以與任何程式語言一起使用,並且使用起 來很有趣! Storm有許多用例:實時分析,
ZooKeeper叢集安裝與配置(ZooKeeper3.4.6)
環境 同時需要在/etc/profile檔案中增加 export JAVA_HOME=/usr/java/jdk1.8.0_65 export CLASSPATH=.:$JAVA_HOM
Redis單機多實體安裝與主從配置
上一篇文章講解了Centos上的redis安裝。 現在我們來說一下redis單機多例項的安裝 首先關閉redis 根據上一篇redis的安裝的配置檔案位置 首先我們複製redis 的配置檔案 cp/etc/redis/6379.conf /etc/redis
Linux-7.2 下 Solr4.10.4 單機模式的安裝與部署圖文詳解
《 Linux下Solr4.10.4搜尋引擎的安裝與部署 》 瞭解Solr: Solr是來自Apache Lucene專案的流行的,快速的,開源的NoSQL搜尋平臺。它的主要功能包括強大
Storm 單機環境的安裝與配置
好久沒寫部落格了,這一段時間一直被導師push著做畢業設計。由於目前的方向偏向於影象識別檢索,畢設打算做一個基於分散式計算平臺的影象檢索系統,查閱相關資料發現Hadoop不適用於實時的計算環境,而Twitter Storm卻能夠滿足自己的需求。我花了大概3~4天的時間,才
spark history server叢集配置與使用(解決執行spark任務之後沒有顯示的問題)
在你的spark路徑的conf檔案中,cp拷貝spark-defaults.conf.template為spark-defaults.conf 並在檔案後面加上 spark.eventLog.enabled true spark.eventLog.di
Kafka_2.10-0.10.0.0叢集安裝與配置
上文已經講過如何安裝Zookeeper叢集,因為Kafka叢集需要依賴Zookeeper服務,雖然Kafka有內建Zookeeper,但是還是建議獨立安裝Zookeeper叢集服務,此處不再贅述 kafka叢集還是安裝在10.10.16.170 、
kafka叢集安裝與使用
kafaka中的名詞: Broker:安裝kafka服務大那臺機器就是一個broker (id要唯一) Producer:訊息的生產者,負責將資料寫入到broker中(push) Consumer:訊息的消費者,負責從kafka中讀取資料(pull),老版本 的消費者依賴zk,新
19 大資料hbase-叢集安裝與常見問題解決
首先說明,要使用hbase是需要先安裝hadoop和zookeeper的(也可以使用自帶的但是不建議),參考[zookeeper叢集安裝] [hadoop叢集安裝] 我用的是三臺機器,mini1,mini2,mini3 Hbase的安裝流程 1、將hbase上傳到hadoop叢集,我這裡上傳的是
hadoop 叢集安裝與部署(大資料系列)
什麼是大資料 基本概念 《資料處理》 在網際網路技術發展到現今階段,大量日常、工作等事務產生的資料都已經資訊化,人類產生的資料量相比以前有了爆炸式的增長,以前的傳統的資料處理技術已經無法勝任,需求催生技術,一套用來處理海量資料的軟體工具應運而生,這就是大資料!
zookeeper-3.4.8單機與主從安裝與配置
ZooKeeper is a centralized service for maintaining configuration information, naming, providing distributed synchronization, and providin
Hadoop本地模式、偽分散式和全分散式叢集安裝與部署
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/template/css/