
實習期間關於VC/C++的一點學習筆記
實習期間,用到了VC++,一點總結如下,以作備份。只是自己的理解,不一定權威正確。請讀者慎重,請諒解。
一、p->a p為指標,呼叫p指向物件的a方法
char *s字串
二、..\表示專案檔案所在目錄向上一級目錄下的目錄。即當前目錄(親兄弟)
..\...\表示專案檔案所在目錄向上二級目錄之下的目錄。(親堂弟)
三、
CString轉為int:intnport=_ttoi(port)
int轉為CString:str1.Format(_T("%d"),intnum1);
TCHAR字元陣列轉為CString:TCHAR str2[10];
Cstring str ;
CString轉為TCHAR字元陣列:_tcscpy(目的str2,str);
string轉為int: inttmp; string str; tmp = atoi(str.c_str());
Char陣列轉為string:stringstr;str = ch;
AfxMessageBox不能輸出int變數?
Tchar陣列轉長整形long:_wtol(Tchar*)
TCHAR陣列清空
TCHAR preStr[20]memset(preStr,0,20*sizeof(TCHAR));
兩個Tchar字串是一樣:
_tcscmp(
Unicode字串的實際長度,即結尾符'\0'前內容的長度,不包括結尾符'\0',Tchar*字串也能用。
_tcslen(preStr)《《《》》》非Unicode的strlen一樣
Memset
memset(void *buffer, int c, int count);
功能:用來對一段記憶體空間全部設定為某個字元。把buffer所指記憶體區域的前count個位元組設定成字元,為c的ASCII碼值的字元。
針對string的兩個字串複製函式:
strcpy和memcpy都是從一塊記憶體複製一段連續的資料到另一塊記憶體
memcpy(dest,src,count);
由src所指記憶體區域複製count個位元組到dest所指記憶體區域。
strcpy(dest,src);
strcpy不需要指定長度,它遇到被複制字元的串結束符"\0"才結束,所以容易溢位。memcpy是根據其第3個引數決定複製的長度。
CString和string雖然是類,但它們的複製:直接等號複製,值拷貝,各有不同的記憶體。
Cstringa=_T("hello"),b;
b=a;
改變a的值,b不變。
另附:
關於物件的賦值
物件2 = 物件1;
在C++中:將物件1的成員變數值一一複製給物件2的對應成員變數(只針對成員變數,不針對成員函式!)。但兩個物件具有各自的記憶體。如果再改變物件1的成員變數值,物件2不變。
而在C#和Java中,當將一個物件賦值給另一個物件時,他們指向同一塊記憶體的地址,即兩個物件是相同的,只是不同的引用。
Java中的引用型別變數:它的值是所引用物件的地址。如 Person p1,p2; 兩個引用。 若p1=p2;則p1也指向了p2的物件。
四、
char *s 和 char s[]的區別
char *s1 ="hello";
char s2[] = "hello";【區別所在】
char *s1的s1,而指標是指向一塊記憶體區域,它指向的記憶體區域的大小可以隨時改變,它是指向字串常量的首地址的指標,編譯器將字串常量放在只讀資料段.裡面的資料是不可更改的。該記憶體裡的值不可以改變了,但是可以改變s1指向其他字串。
char s2[]的s2是陣列對應著一塊記憶體區域,其地址和容量在生命期裡不會改變,只有陣列的內容可以改變
在只讀取不修改時,兩個一樣。
【記憶體模型】
+-----+ +---+---+---+---+---+---+
s1: | *======> | h |e | l | l | o |\0 |
+-----+ +---+---+---+---+---+---+
+---+---+---+---+---+---+
s2: | h | e | l | l | o |\0 |
+---+---+---+---+---+---+
場景一)
char *s1 ="hello";
char s2[] = "well";
s2=s1; //編譯ERROR相當於改變s2指向別的字串,錯誤的,
s1=s2; //OK改變s1指向s2指向的字串現在s1指向"well"
分析:s2其地址和容量在生命期裡不能改變
場景二)
char s2[] ="hello";
char *s1 = s2; //編譯器做了隱式的轉換 實際為&s2
或
char *s1 = &s2;
分析:以上兩個指標復值完全等價,由於編譯器會做這個隱式轉換也容易導致初學者誤認為char *s 與char s[]是一回事。
另用第二種在一些編譯器甚至會報警告資訊。
場景三)
char *s1 ="hello";
char s2[] ="hello";
s1[0]='a'; //×執行ERROR(不可以改變s1指向的內部的值,但不改變,輸出某個字元是可以的)
s2[0]='a'; //OK
分析:執行時會報錯,原因在於企圖改變s1的內容,由於s1指向的是常量字串,其內容是不可修改的,因此在執行時不會通過。而s2指向的是變數區字串,可以修改。
下面是一些char *s1 和 chars2[]相同的地方(同樣編譯器對char[]做了隱式變化):
1)作為形參完全相同
如:
void function(char *s1);
void function(char s1[]);
2)只讀取不修改的時候
如:
char *s1="hello";
char s2[]="hello";
printf("s1[1]=[%c]\n",s1[1]); //s1[1]=[e]
printf("s2[1]=[%c]\n",s2[1]); //s2[1]=[e]
printf("s1=[%s]\n",s1); //s1=[hello]
printf("s2=[%s]\n",s2); //s2=[hello]
講2:
#include<stdio.h>
intmain(int argc, char *argv[])
{
char day[15] = "abcdefghijklmn";
char* strTmp = "opqrstuvwxyz";
printf("&day is %x\n",&day);
printf("&day[0] is %x\n",&day[0]);
printf("day is %x\n",day);
printf("\n&strTmpis %x\n",&strTmp);
printf("&strTmp[0] is %x\n",&strTmp[0]);
printf("strTmp is %x\n",strTmp);
getchar();
return 0;
}
執行後螢幕上得到如下結果:
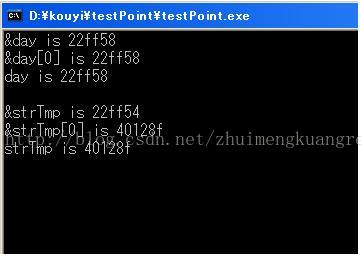
其實看到結果估計很多東西就好明白了,
先看看前三個輸出也就是關於變數day的,在 char day[15] = "abcdefghijklmn";這個語句執行的時候,系統就分配了一段長15的記憶體,並把這段記憶體起名為day,裡面的值為"abcdefghijklmn",如下圖所示:

再看程式,第一個輸出,&day,&號是地址運算子,也就是day這個變數的記憶體地址,很明顯,在最前面,也就是a字元所在位元組的地址;
對於第二個輸出也就好理解了,&day[0],就是day陣列中第一個變數(也就是a)的地址,因此他們兩個是一樣的;
第三個輸出是day,對於陣列變數,可以使用變數名來索引變數中的內容,其實這裡的day可以理解成陣列變數退化的指標,並且指向陣列的開頭,既然把它理解成指標,那麼它的值肯定是地址了,所以他的值和上面兩個也一樣。
再看看後面三個輸出,關於字串指標strTmp,在執行char* strTmp = "opqrstuvwxyz";後,記憶體的圖示如下:

如圖所示,記憶體分配了兩段記憶體,一個名為strTmp,型別是一個字元指標,另外一段是一個字串常量,且strTmp裡面存放著字元常量的首地址,注意這裡無法通過strTmp修改這段字串,因為是常量;於是程式中的後面三個輸出就好理解了;
&strTmp:strTmp這個字元指標的地址
&strTmp[0]:strTmp所指字元常量第一個字元的地址
strTmp:strTmp這個字元指標的值,即字元常量的首地址
因此,最後兩個的值是一樣的。
指標可以這樣理解,指標這種型別,和int,char,double等等是一樣的,只是它用來儲存地址值的,而int變數儲存整數,char變數儲存字元,僅此而已,就char型指標或者int指標,本質是一樣的,都是存放的地址,只不過那個地址所裡面的變數型別不同而已,還有一種void型指標,就是可以放任何型別變數的地址。
五、
指向字元的指標和指向字串的指標:都是連續的,它自己找是存的字元還是字串。
Vc6.0標頭檔案名不區分大小寫,但函式和變數名稱區分大小寫
windows檔案路徑不區分字母大小寫,Linux區分字母大小寫
六、匈牙利命名
命名:
函式:各首字母大寫
變數:小駝峰:型別字首+第一個字母小寫
全域性變數必須要以 g_ 開頭:
指標以p開頭,int以n開頭
類:以C開頭,各首字母大寫
六、
在CList中查詢某項,或者在某索引處插入要先找POSITION
POSITION position = contact.m_userList.FindIndex(i);
然後
m_userList.GetAt(position)
七、
類的成員函式的定義實現時,要加類名:: 找了好久,囧!!
八、
當某類的成員函式的形參有該種類型的物件時,要定義類的預設拷貝建構函式
CContact(constCContact& );
九、
除錯:
VC6.0
F9——插入刪除斷點,斷點位置為游標所在行
F5——除錯go,開始執行,到斷點會自動停止,沒有斷點,會執行完
Ctrl F5——直接執行,到斷點不會停止
F10——向前走一步,不進入函式內部
F11——向前走一步,如果由函式就進入內部
未開始除錯的情況下,按F10或者F11,會自動開始除錯,滑鼠自動定位到頭部
Shift+F11——如果進入了函式,執行到中間,想跳出來,就按這個
Ctrl+F10——執行到游標,個人覺得這個很好用,覺得哪一行可能會出問題,在這一行前點一下滑鼠,然後按下這倆鍵,就執行到這裡了,不用設定斷點。
F5——執行到下一個斷點
至於查值,說的是在上述除錯執行到某一行的過程中,檢視某個變數的值,這個可以通過下方出現的Variable和Watch視窗檢視,Variable不能輸入,自動出現相關變數的值,watch視窗,可以自己輸入變數名稱,檢視執行到某一步時的變數值。
如果沒有這兩個視窗,可以在選單欄右側右鍵,勾選variable和watch,就會出現。在VS中按下CTRL+D+W,也會出現watch視窗。
十、
truct結構體中定義建構函式和解構函式
structCTest
{
CTest();
~CTest();
int num;
};
CTest::CTest()
{
}
CTest::~CTest()
{
}
[...]
struct CTest * pTest = new struct CTest();
[...]
和class幾乎沒有區別。
十一、
結構體可以new,也可以不new。new與不new的區別是,new為會每一個成員欄位賦一個預設初值(還記得default關鍵字嗎),而不new則不會這麼做。
十二、
漢字、字元、位元組、位之間的關係
1位元組8位天經地義永不變 O(∩_∩)O哈哈~
1個漢字 = 1個字 = 1個字元
1個字元 = 1個位元組 =8bit(ACSII碼下)
1個字元 = 2個位元組 =16bit(Unicode碼下)
處理漢字時,會預設將 編碼方式調整為Unicode碼,所以一個漢字始終是2位元組,英文字元還分ACSII和Unicode
十四、
引用
對一個數據可以使用“引用 ”(reference) ”,這是 C++ 對 C的一個重要擴充 的一個重要擴充 ,引用是一種新的變數型別,它的作用是為一個變數 起別名。假如有a,想給它起一個別名給它起一個別名 b,可以這樣寫 :
int a;
int &b=a; // 宣告b是a的引用
以上語句聲明瞭以上語句聲明瞭 b是 a的引用 ,即 b是 a的別名。
b和a佔記憶體中的同一個儲單元 ,它們具有同一地址。
十五、
C++多型性:
在基類的函式前加上virtual關鍵字,在派生類中重寫該函式,執行時就會根據物件的實際型別來確定呼叫相對應的函式。
重寫分兩種,直接重寫成員函式和重寫虛擬函式。只有重寫了虛擬函式的才能算作是體現了C++多型性。過載也沒有體現多型性,過載是允許有多個同名的函式,而這些函式的引數列表不同,允許引數個數不同,引數型別不同,或者兩者都不同。編譯器會根據這些函式的不同列表,將同名的函式的名稱做修飾,從而生成一些不同名稱的預處理函式,來實現同名函式呼叫時的過載問題。
十六、
建構函式和解構函式:
建構函式:不需要使用者來呼叫它,而是在建立物件時自動執行。如果要執行初始化賦值等操作時,必須要自定義建構函式;系統預設生成的建構函式是空的,什麼都不幹。
解構函式:當物件的生命期結束時,會自動執行解構函式。解構函式的作用並不是刪除物件,完成清理工作,使這部分記憶體可以被程式分配給新物件使用。
A類建構函式和解構函式中不用顯式寫父類和物件成員的構造、解構函式,具有好的品質,尊老愛幼,會先自動呼叫父類的建構函式,再物件成員的建構函式(物件成員中按宣告的先後順序,解構函式反過來),最後自己的建構函式,先別人最後自己。解構函式順序完全相反。
十六、
C++類有物件成員,其建構函式與解構函式:
建構函式:
例如,一個矩形資料可用兩個點資料成員,分別表示矩形的左上角點和右下角點:
class Rectangle {
public:
Rectangle (intleft, int top, int right, int bottom);
//...
private:
Point topLeft;
Point botRight;
};
矩形的建構函式也應該初始化兩個類物件成員,假定Point類有建構函式,矩形兩個資料成員topLeft和botRight可放在Rectangle建構函式的初始化表中初始化:
Rectangle::Rectangle(int left, int top, int right, int bottom)
:topLeft(left,top), botRight(right,bottom)
{
}
如果Point建構函式沒有引數,或所有引數都有預設的引數,上面的成員初始化表可以省略,但是,建構函式仍然被隱含地呼叫。在建立類Rectangle 的物件(呼叫類Rectangle的建構函式)時,會自動呼叫類Point 的建構函式(topLeft的和botRight的)。在類Point的建構函式為無參時,先自動呼叫Point的建構函式,再呼叫Rectangle自己的,不用在Rectangle的建構函式中加上:Point() Point建構函式。會自動呼叫!!
如果類Point的建構函式為有參函式時,通常採用初始化表的方式來呼叫建構函式。初始化化的順序如下:首先topLeft的建構函式被呼叫,接著呼叫botRight的建構函式,最後呼叫Rectangle的建構函式。TopLeft初始化在botRight之前的原因不是因為:在成員初始化表中,TopLeft位於botRight之前,而是因為在Rectangle類的定義中,TopLeft位於botRight之前。所以,如果建構函式的定義改成下面的形式,並不會影響到建構函式呼叫的順序。
Rectangle::Rectangle(int left, int top, int right, int bottom)
:botRight(right,bottom), topLeft(left,top)
{
}
在與建構函式賦值相比,成員初始化列表佔用較少的開銷,因此具有較高的效率。更重要的是成員初始化列表是用來初始化類的const或引用型別資料成員的唯一方法,它們不能採用賦值操作。
解構函式:解構函式也是,不用在Rectangle 解構函式中,寫~Point()。會自動呼叫!!
在類定義中含有物件成員,則在建立類物件時先呼叫物件成員的建構函式,再呼叫類本身的建構函式;析構時
先呼叫自己的解構函式,再物件成員的。與建構函式順序完全相反。
十七、
CList、list的建構函式和解構函式
CList和list都有自己的建構函式,會構造一個空的有序列表。不用顯式構造;
都有預設解構函式,不用重寫解構函式。
十八、
判斷Tchar陣列為空Tchartext[10]:
If(text[0]==_T('\0'))
法二、
CStringstr=_T("");
str.Format(L"%s",preStr);
if (str.IsEmpty())
{
TRACE(_T("空"));
}
十九、
控制代碼:要對某個視窗進行操作,首先就要得到這個視窗的控制代碼。其它各種資源(視窗,圖示,游標等),系統在建立這些資源時會為它們分配記憶體,並返回標識這些資源的標識號,即控制代碼。是視窗,圖示,游標等的標識號,不是記憶體的地址或標識。
二十、
vc++結構體的定義
typedefstruct Student
{
int a;
int b;
}Stu;
於是在宣告變數的時候就可:Stustu1; 這裡的Stu實際上就是struct Student的別名。這裡也可以不寫Student
如果沒有typedef就必須用structStudent stu1;來宣告
二十一、
windows是事件驅動方式的程式設計
WinMain函式是Windows程式入口點函式,與dos的main相同,當winmain函式結束或返回時,windows應用程式結束。
二十二、
記憶體洩露:
用動態儲存分配函式動態開闢的空間,在使用完畢後未釋放,結果導致一直佔據該記憶體單元。直到程式結束。(其實說白了就是該記憶體空間使用完畢之後未回收)即所謂記憶體洩漏。
記憶體溢位:
記憶體不夠,通常在執行大型軟體或遊戲時,軟體或遊戲所需要的記憶體遠遠超出了你主機內安裝的記憶體所承受大小,就叫記憶體溢位。此時軟體或遊戲就執行不了,系統會提示記憶體溢位,有時候會自動關閉軟體,重啟電腦或者軟體後釋放掉一部分記憶體又可以正常執行該軟體或遊戲一段時間。
二十三、
C++在類中定義成員變數時不可以賦值,靜態成員變數可以,而Java行,語法決定。呵呵
二十四、
TRACE("DDDDDDDDDDD");
TRACE("wewe%d",333);
同樣還存在TRACE0,TRACE1,TRACE2。。。分別對應0,1,2。。個引數
TRACE0 ,就是不帶動態引數輸出字串, 類似C的printf("輸出字串");
TRACE1 中的字串可以帶一個引數輸出 ,類似C的printf("...%d",變數);
TRACE2 可以帶兩個引數輸出,類似C的printf("...%d...%f",變數1,變數2);
TRACE3 可以帶三個引數輸出,類似C的printf("...%d,%d,%d",變數1,變數2,變數3);
CListControl控制元件的使用:
一、
int nLine = m_list.GetItemCount();列表多少行?
int nCol = m_list.GetHeaderCtrl()->GetItemCount();列表多少列
二、插入行,插入在首行
int nRow = m_ctrlList.InsertItem(i,“第一行第一列值”);//i表示在資料在CListCtrl中的索引為行,返回插入的行
m_ctrlList.SetItemText(nRow,1, “第一行第二列值”);
m_ctrlList.SetItemText(nRow,2, “第一行第三列值”);
三、GetNextSelectedItem這個函式
看msdn的用法,其實是返回第一個的index,然後走到下一個選中的行去。
刪除第0行以後,下面的行會往上移,那麼原來的第1行就變成了第0行。遞迴的