
Mysql索引---Hash索引和Btree索引區別
| 索引名 | hash | Btree |
|---|---|---|
| 支援最左字首匹配原則? | 不支援,只有索引的全部欄位都用上才會匹配到 | 支援,用上索引的第一個欄位就可以匹配索引 |
| MyISAM和InnoDB是否支援? | 不支援(只有Memory和NDB引擎索引支援) | 支援 |
| 範圍查詢能否命中索引? | 不可以,只有“=”,“IN”,“<=>”(等價於的意思)查詢能命中 | 可以 |
| 一定會全表掃描嗎? | 是 | 否 |
| 資料結構 | hash表,通過鍵去找值的一種資料結構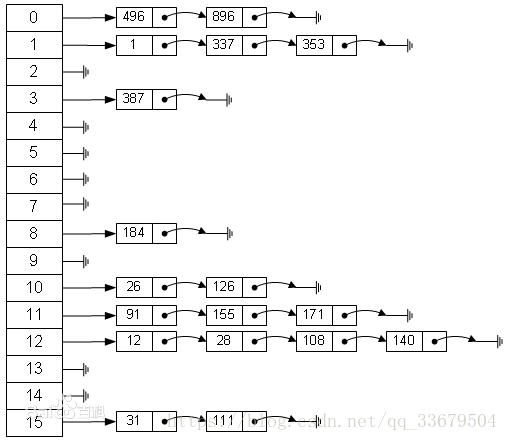 |
B-tree,多路搜尋樹,並不是二叉的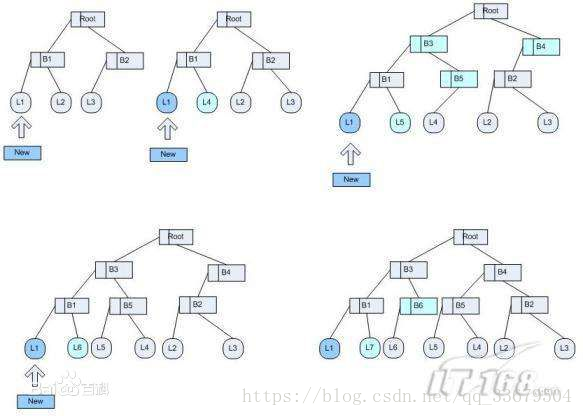 |
相關推薦
Mysql索引---Hash索引和Btree索引區別
索引名 hash Btree 支援最左字首匹配原則? 不支援,只有索引的全部欄位都用上才會匹配到 支援,用上索引的第一個欄位就可以匹配索引 MyISAM和InnoDB是否支援? 不支
mysql的hash索引和btree索引
mysql的hash索引和btree索引 hash 索引有著與剛才所討論特點的相比截然不同的特點: Hash 索引只能夠用於使用 = 或者 <=> 運算子的相等比較(但是速度更快)。Hash 索引不能夠用於諸如 < 等用於查詢一個範圍值的比較運算子。依賴於這種單值查詢
Hash索引和BTree索引區別
索引是幫助mysql獲取資料的資料結構。最常見的索引是Btree索引和Hash索引。 不同的引擎對於索引有不同的支援:Innodb和MyISAM預設的索引是Btree索引;而Mermory預設的索引是Hash索引。 我們在mysql中常用兩種索引演算法BTr
hash索引和btree索引的區別
可 能很多人又有疑問了,既然 Hash 索引的效率要比 B-Tree 高很多,為什麼大家不都用 Hash 索引而還要使用 B-Tree 索引呢?任何事物都是有兩面性的,Hash 索引也一樣,雖然 Hash 索引效率高,但是 Hash 索引本身由於其特殊性也帶來了很多限制和弊端,主要有以下這些。 (1)Has
(ainusers原創)Hash索引和BTree索引
注: Innodb和myisam預設的索引是Btree索引 Hash索引(類比於拼音查詢漢字) BTree(類比於偏旁查詢漢字) 區別(瞭解Innodb和myisam主要還應該從區別開始) 1.主要區別在於:Hash不能用於範圍查詢 2.檢索效率遠高於BTree
MySQL中冗餘和重複索引的區別
MySQL允許在單個列上建立多個索引,無論是有意還是無意,MySQL需要單獨維護這些重複索引,優化器在優化查詢時也需要逐個考慮這會影響MySQL的效能 概念闡述 重複索引: 在相同的列上按照相同的順序建立的相同型別的索引。應該避免建立這樣的重複索引,發現之後也應該立
Hash索引和BTree索引
至於Btree索引,它是以B+樹為儲存結構實現的。 但是Btree索引的儲存結構在Innodb和MyISAM中有很大區別。 在MyISAM中,我們如果要對某張表的某列建立Btree索引的話,如圖: 所以我們經常會說MyISAM中資料檔案和索引檔案是分開的。 因此MyISAM的索引方式也稱
索引的概念和建立索引例子
1 索引的概念 索引是一個單獨的、物理的資料庫結構,它是某個表中一列或若干列值的集合和相應的指向表中物理標識這些值的資料頁的邏輯指標清單。表的儲存由兩部分組成,一部分用來存放資料頁面,另一部分存放索引頁面。通常,索引頁面相對於資料頁面來說小得多。資料檢索花費的大部分開銷
Mysql存儲過程和函數區別介紹
fill get .com href 參數 tle gravity 由於 target 原文鏈接 存儲過程是用戶定義的一系列sql語句的集合,涉及特定表或其它對象的任務,用戶可以調用存儲過程,而函數通常是數據庫已定義的方法,它接收參數並返回某種類型的值並且不涉及特定用戶表。
mysql之觸發器before和after的區別
mysql 訂單 負數 values 完成 -1 class 大於 nbsp 我們先做個測試: 接上篇日誌建的商品表g和訂單表o和觸發器 假設:假設商品表有商品1,數量是10; 我們往訂單表插入一條記錄: insert into o(gid,much) value
正確理解MySQL中的where和having的區別(轉載)
pri keyword 均值 VG pan group 解釋 having sele 下面以一個例子來具體的講解: 1. where和having都可以使用的場景 select goods_price,goods_name from sw_goods where g
mysql中find_in_set使用和in的區別
插入三條資料; INSERT INTO `test` VALUES (1, 'name', 'daodao,xiaohu,xiaoqin'); INSERT INTO `test` VALUES (2, 'name2', 'xiaohu,daodao,xiaoqin'); INSERT
MYSQL儲存引擎innodb和myisam的區別
innodb:預設事務型引擎,最重要最廣泛的儲存引擎,效能非常優秀,資料庫儲存在共享表空間,可以通過配置分開。對主鍵查詢的效能高於其他型別的儲存引擎。它內部做了很多優化,從磁碟讀取資料時自動在記憶體構建hash(雜湊)索引,插入資料時自動構建插入緩衝區。它可以通過一些機制和工具支援真正的熱備份,支援
MySQL中no action和restrict的區別
在MySQL中,如果兩個表存在主外關係,則有五種引用操作,分別是 cascade、no action、restrict、set null和set default,有很多人對no action的restrict區別搞不清楚,其實在MySQL中是一樣的,原因如下:re
MySQL中CREATE DATABASE和CREATE SCHEMA區別
在使用MS SQL的時候,一般建立資料庫我們都習慣於使用CREATE DATABASE 來完成,而使用CREATE SCHEMA來建立架構,但是在MySQL中,官方的中文文件在 CREATE DATABASE 語法一節中寫了一句:也可以使用CREATE SCHEMA。那麼
mysql儲存方式MyISAM 和 InnoDB的區別
MyISAM 和 InnoDB 講解: InnoDB和MyISAM是許多人在使用MySQL時最常用的兩個表型別,這兩個表型別各有優劣,視具體應用而定。基本的差別為:MyISAM型別不支援事務處理等高階處理,而InnoDB型別支援。MyISAM型別的表強調的
正確理解MySQL中的where和having的區別
以前在學校裡學習過SQLserver資料庫,發現學習的都是皮毛,今天以正確的姿態談一下MySQL中where和having的區別。 誤區:不要錯誤的認為having和group by 必須配合使用。 下面以一個例子來具體的講解:
mysql資料庫的 varchar 和 char 的區別 以及char(20)的理解
char是儲存字元(無論字母還是漢字都最多存255個) char(20)表示這個欄位最多存20個字元 如果存了16個字元 那麼也會佔用20個字元的空間varchar是儲存位元組(1個字母1個位元組 1個漢字3個位元組)
MySQL的btree索引和hash索引的區別
class 操作 麻煩 關系 進行 特殊性 檢索 www. 創建 MySQL的btree索引和hash索引的區別 ash 索引結構的特殊性,其檢索效率非常高,索引的檢索可以一次定位,不像B-Tree 索引需要從根節點到枝節點,最後才能訪問到頁節點這樣多次的IO
mysql索引型別Normal,Unique,Full Text區別以及索引方法btree索引和hash的區別
一.mysql索引型別Normal,Unique,Full Text區別 (1)Normal: 表示普通索引,大多數情況下都可以使用 (2)Unique: 約束唯一標識資料庫表中的每一條記錄,即在單表中不能用每條記錄是唯一的(例如身份證就是唯一的),Unique(要求列唯一)和Primary K