
07 準備Plan B:如何設計兜底方案?
這是《如何設計一個秒殺系統》專欄的最後一篇文章,前面我們一起看了很多極致的優化思路,以及架構的優化方案。但是很遺憾,現實中總難免會發生一些這樣或者那樣的意外,而這些看似不經意的意外,卻可能帶來非常嚴重的後果。
我想對於很多秒殺系統而言,在諸如雙十一這樣的大流量的迅猛衝擊下,都曾經或多或少發生過宕機的情況。當一個系統面臨持續的大流量時,它其實很難單靠自身調整來恢復狀態,你必須等待流量自然下降或者人為地把流量切走才行,這無疑會嚴重影響使用者的購物體驗。
同時,你也要知道,沒有人能夠提前預估所有情況,意外無法避免。那麼,我們是不是就沒辦法了呢?當然不是,我們可以在系統達到不可用狀態之前就做好流量限制,防止最壞情況的發生。用現在流行的話來說,任何一個系統,都需要“反脆弱”。
具體到秒殺這一場景下,為了保證系統的高可用,我們必須設計一個Plan B方案來兜底,這樣在最壞情況發生時我們仍然能夠從容應對。今天,我們就來看下兜底方案設計的一些具體思路。
高可用建設應該從哪裡著手
說到系統的高可用建設,它其實是一個系統工程,需要考慮到系統建設的各個階段,也就是說它其實貫穿了系統建設的整個生命週期,如下圖所示:
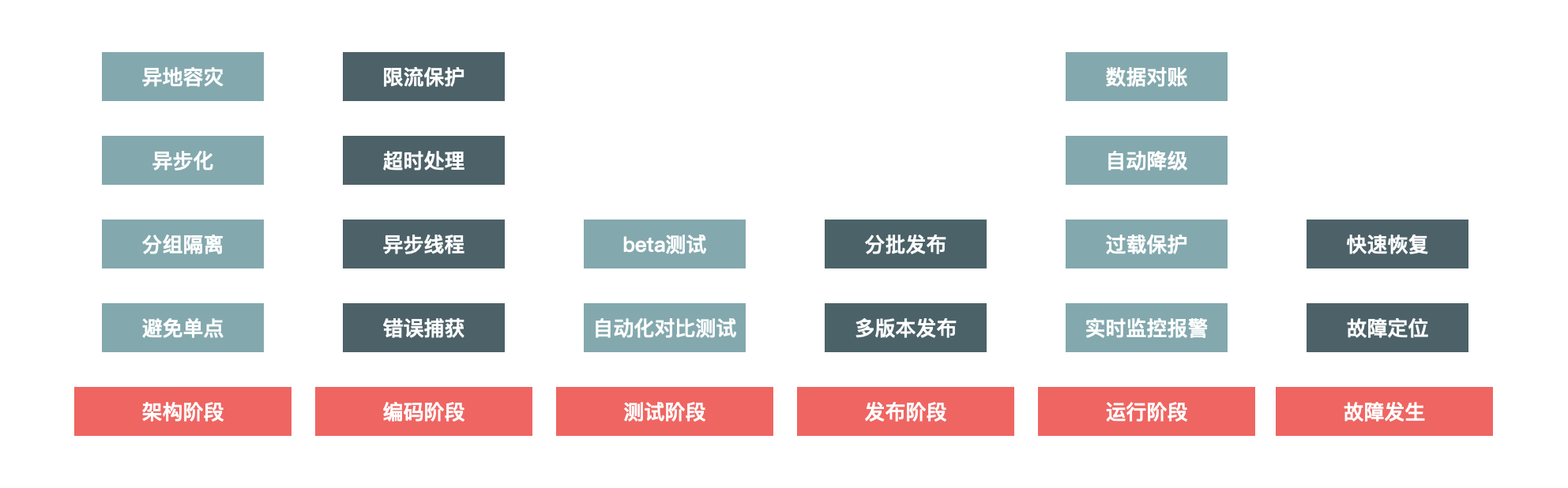
圖1 高可用系統建設
具體來說,系統的高可用建設涉及架構階段、編碼階段、測試階段、釋出階段、執行階段,以及故障發生時。接下來,我們分別看一下。
- 架構階段:架構階段主要考慮系統的可擴充套件性和容錯性,要避免系統出現單點問題。例如多機房單元化部署,即使某個城市的某個機房出現整體故障,仍然不會影響整體網站的運轉。
- 編碼階段:編碼最重要的是保證程式碼的健壯性,例如涉及遠端呼叫問題時,要設定合理的超時退出機制,防止被其他系統拖垮,也要對呼叫的返回結果集有預期,防止返回的結果超出程式處理範圍,最常見的做法就是對錯誤異常進行捕獲,對無法預料的錯誤要有預設處理結果。
- 測試階段:測試主要是保證測試用例的覆蓋度,保證最壞情況發生時,我們也有相應的處理流程。
- 釋出階段:釋出時也有一些地方需要注意,因為釋出時最容易出現錯誤,因此要有緊急的回滾機制。
- 執行階段:執行時是系統的常態,系統大部分時間都會處於執行態,執行態最重要的是對系統的監控要準確及時,發現問題能夠準確報警並且報警資料要準確詳細,以便於排查問題。
- 故障發生:故障發生時首先最重要的就是及時止損,例如由於程式問題導致商品價格錯誤,那就要及時下架商品或者關閉購買連結,防止造成重大資產損失。然後就是要能夠及時恢復服務,並定位原因解決問題。
為什麼系統的高可用建設要放到整個生命週期中全面考慮?因為我們在每個環節中都可能犯錯,而有些環節犯的錯,你在後面是無法彌補的。例如在架構階段,你沒有消除單點問題,那麼系統上線後,遇到突發流量把單點給掛了,你就只能乾瞪眼,有時候想加機器都加不進去。所以高可用建設是一個系統工程,必須在每個環節都做好。
那麼針對秒殺系統,我們重點介紹在遇到大流量時,應該從哪些方面來保障系統的穩定執行,所以更多的是看如何針對執行階段進行處理,這就引出了接下來的內容:降級、限流和拒絕服務。
降級
所謂“降級”,就是當系統的容量達到一定程度時,限制或者關閉系統的某些非核心功能,從而把有限的資源保留給更核心的業務。它是一個有目的、有計劃的執行過程,所以對降級我們一般需要有一套預案來配合執行。如果我們把它系統化,就可以通過預案系統和開關係統來實現降級。
降級方案可以這樣設計:當秒殺流量達到5w/s時,把成交記錄的獲取從展示20條降級到只展示5條。“從20改到5”這個操作由一個開關來實現,也就是設定一個能夠從開關係統動態獲取的系統引數。
這裡,我給出開關係統的示意圖。它分為兩部分,一部分是開關控制檯,它儲存了開關的具體配置資訊,以及具體執行開關所對應的機器列表;另一部分是執行下發開關資料的Agent,主要任務就是保證開關被正確執行,即使系統重啟後也會生效。
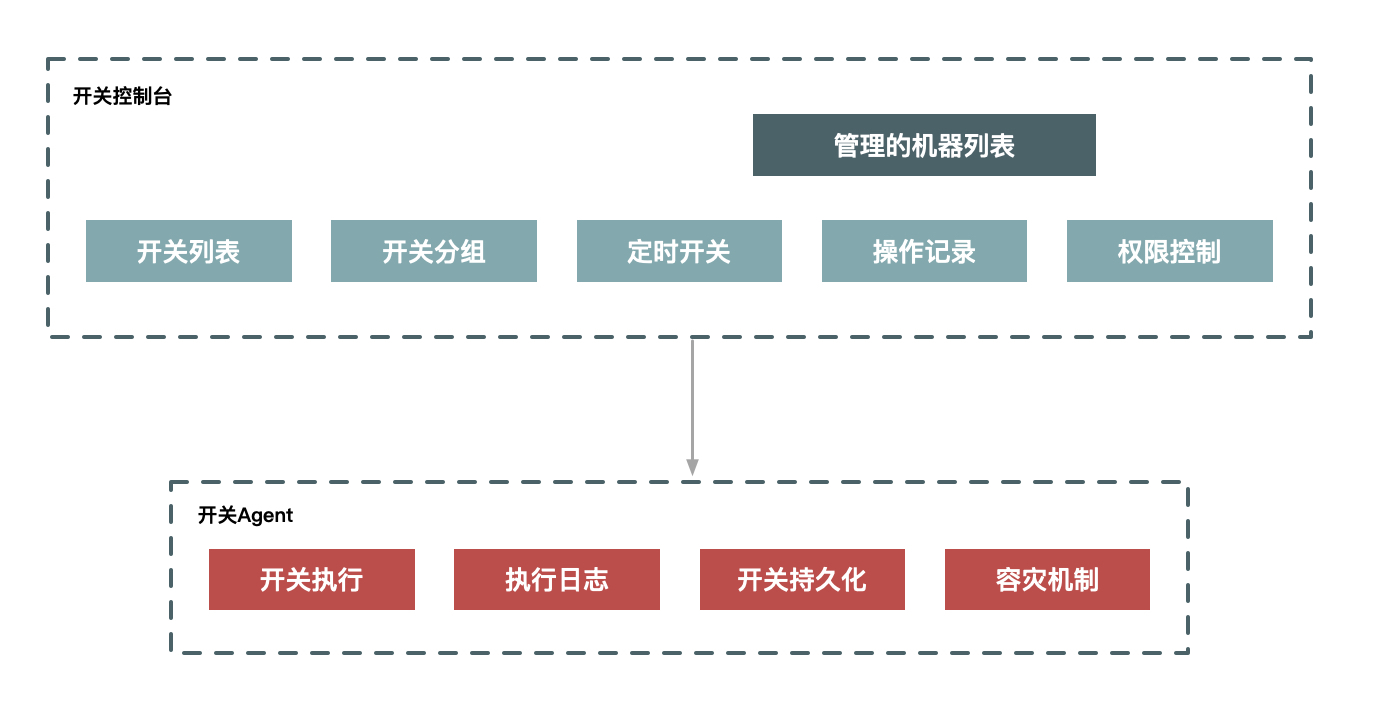
圖2 開關係統
執行降級無疑是在系統性能和使用者體驗之間選擇了前者,降級後肯定會影響一部分使用者的體驗,例如在雙11零點時,如果優惠券系統扛不住,可能會臨時降級商品詳情的優惠資訊展示,把有限的系統資源用在保障交易系統正確展示優惠資訊上,即保障使用者真正下單時的價格是正確的。所以降級的核心目標是犧牲次要的功能和使用者體驗來保證核心業務流程的穩定,是一個不得已而為之的舉措。
限流
如果說降級是犧牲了一部分次要的功能和使用者的體驗效果,那麼限流就是更極端的一種保護措施了。限流就是當系統容量達到瓶頸時,我們需要通過限制一部分流量來保護系統,並做到既可以人工執行開關,也支援自動化保護的措施。
這裡,我同樣給出了限流系統的示意圖。總體來說,限流既可以是在客戶端限流,也可以是在服務端限流。此外,限流的實現方式既要支援URL以及方法級別的限流,也要支援基於QPS和執行緒的限流。
首先,我以內部的系統呼叫為例,來分別說下客戶端限流和服務端限流的優缺點。
- 客戶端限流,好處可以限制請求的發出,通過減少發出無用請求從而減少對系統的消耗。缺點就是當客戶端比較分散時,沒法設定合理的限流閾值:如果閾值設的太小,會導致服務端沒有達到瓶頸時客戶端已經被限制;而如果設的太大,則起不到限制的作用。
- 服務端限流,好處是可以根據服務端的效能設定合理的閾值,而缺點就是被限制的請求都是無效的請求,處理這些無效的請求本身也會消耗伺服器資源。
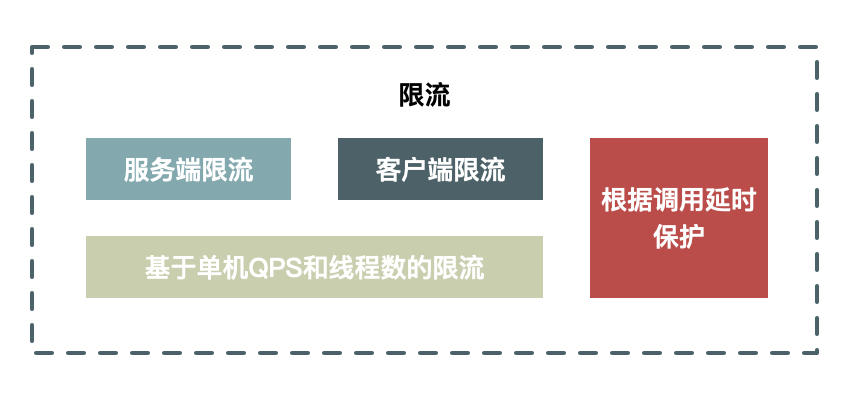
圖3 限流系統
在限流的實現手段上來講,基於QPS和執行緒數的限流應用最多,最大QPS很容易通過壓測提前獲取,例如我們的系統最高支援1w QPS時,可以設定8000來進行限流保護。執行緒數限流在客戶端比較有效,例如在遠端呼叫時我們設定連線池的執行緒數,超出這個併發執行緒請求,就將執行緒進行排隊或者直接超時丟棄。
限流無疑會影響使用者的正常請求,所以必然會導致一部分使用者請求失敗,因此在系統處理這種異常時一定要設定超時時間,防止因被限流的請求不能fast fail(快速失敗)而拖垮系統。
拒絕服務
如果限流還不能解決問題,最後一招就是直接拒絕服務了。
當系統負載達到一定閾值時,例如CPU使用率達到90%或者系統load值達到2*CPU核數時,系統直接拒絕所有請求,這種方式是最暴力但也最有效的系統保護方式。例如秒殺系統,我們在如下幾個環節設計過載保護:
在最前端的Nginx上設定過載保護,當機器負載達到某個值時直接拒絕HTTP請求並返回503錯誤碼,在Java層同樣也可以設計過載保護。
拒絕服務可以說是一種不得已的兜底方案,用以防止最壞情況發生,防止因把伺服器壓跨而長時間徹底無法提供服務。像這種系統過載保護雖然在過載時無法提供服務,但是系統仍然可以運作,當負載下降時又很容易恢復,所以每個系統和每個環節都應該設定這個兜底方案,對系統做最壞情況下的保護。
總結一下
網站的高可用建設是基礎,可以說要深入到各個環節,更要長期規劃並進行體系化建設,要在預防(建立常態的壓力體系,例如上線前的單機壓測到上線後的全鏈路壓測)、管控(做好線上執行時的降級、限流和兜底保護)、監控(建立效能基線來記錄效能的變化趨勢以及線上機器的負載報警體系,發現問題及時預警)和恢復體系(遇到故障要及時止損,並提供快速的資料訂正工具等)等這些地方加強建設,每一個環節可能都有很多事情要做。
另外,要保證高可用建設的落實,你不僅要做系統建設,還要在組織上做好保障。高可用其實就是在說“穩定性”。穩定性是一個平時不重要,但真出了問題就會要命的事兒,所以很可能平時業務發展良好,穩定性建設就會給業務讓路,相關的穩定性負責人員平時根本得不到重視,一旦遇到故障卻又成了“背鍋俠”。
而要防止出現這種情況,就必須在組織上有所保障,例如可以讓業務負責人背上穩定性KPI考核指標,然後在技術部門中建立穩定性建設小組,小組成員由每個業務線的核心力量兼任,他們的KPI由穩定性負責人來打分,這樣穩定性小組就可以把一些體系化的建設任務落實到具體的業務系統中了。