
Python爬蟲----爬蟲入門(4)---urllib2 模擬登陸
阿新 • • 發佈:2019-01-25
開發環境,ubuntu 14.0.1自帶python 2.7.6
接下來要開始抓取需要登陸才能抓取的頁面:
這裡先抓一個不需要驗證的網站:學校的官網:
找到登陸框,輸入密碼賬號,登陸。(先開啟開發者工具)
推薦谷歌和火狐瀏覽器:
Network–>找到登陸請求的post資料–>Formdata:
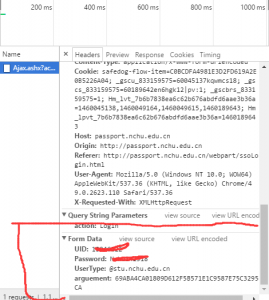
接下來就要構造formdata資料,然後post上傳;
具體程式碼如下:(首先找到登陸地址)
PostUrl = "http://passport.****.edu.cn/Ajax.ashx?action=Login"
cookie = cookielib.CookieJar()
handler = urllib2.HTTPCookieProcessor(cookie)
opener = urllib2.build_opener(handler)
# 將cookies繫結到一個opener cookie由cookielib自動管理 具體解釋檢視註釋即可,我們通過post登陸成功得到cookie,儲存好(也可以輸出到文字)就能使用這個cookie登陸其他需要登陸才能訪問的頁面。
cookie使用方法如下:
#使用cookie
response = opener.open(CaptchaUrl)
print response.read()這樣就能成功的返回資訊(具體結果不貼,隱私問題)
接下來嘗試一個需要驗證碼登陸的網站:
思路就是先把驗證碼下載到本地,檢視然後登陸(關於驗證碼識別,那又是一門學問了,能寫一本書)
(這裡有個問題,因為每次重新整理的驗證碼路徑是不同的,所以要先獲得驗證碼,在提交表單)
使用正則:
def getImg(html):
reg = r'="/V.+"\s+id'
imglist = re.findall(imgre,html)
return imglist[0]#分析原始碼,獲取驗證碼地址 Mahtml='http://www.pceggs.com'+
getImg(html)[2:][:-5]
print Mahtml這樣就能得到驗證碼檔案地址,下載下來即可。其他地方和前面一樣‘
#coding=utf-8
import urllib2
import cookielib
import urllib
import re
PostUrl = "http://www.pceggs.com/"
cookie = cookielib.CookieJar()
handler = urllib2.HTTPCookieProcessor(cookie)
opener = urllib2.build_opener(handler)# 將cookies繫結到 #一個opener cookie由cookielib自動管理txt_UserName='*****'
txt_PWD='*****'#由於該網站的驗證碼地址是隨機的,所以必須先獲得源
#碼,分析出驗證碼地址才可以
response = urllib2.urlopen(PostUrl)
html=response.read()
def getImg(html):
reg = r'="/V.+"\s+id'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
print Mahtml
#驗證碼下載#
urllib.urlretrieve(Mahtml,'yanma.jpg','wb')
#用openr訪問驗證碼地址,獲取
cookiepicture = opener.open(Mahtml).read()
# 用openr訪問驗證碼地址,獲取
cookielocal = open('image.gif', 'wb')
local.write(picture)local.close()# 儲存驗證碼到本地SecretCode = raw_input('輸入驗證碼: ')
# 開啟儲存的驗證碼圖片 輸入#
print SecretCode
postData = {'__VIEWSTATE': '/wEPDwUKMTI3ODYxNzg2OGQYAQUeX19Db250cm9sc1JlcXVpcmVQb3N0QmFja0tleV9fFgEFDExvZ2luX1N1Ym1pdHhnq1J+1JgPIoSYyL3EBi6sUrdm','__VIEWSTATEGENERATOR':'90059987','Head2$WithdrawCount':'4089800','txt_UserName': txt_UserName,'txt_PWD': txt_PWD,'txt_VerifyCode':SecretCode,'Login_Submit.x':'63','Login_Submit.y':'11','SMONEY':'ABC'}# 根據抓包資訊 構造表單
headers = {'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8','Accept-Language': 'zh-CN,zh;q=0.8','Connection': 'keep-alive','Content-Type': 'application/x-www-form-urlencoded','User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/46.0.2490.86 Safari/537.36',}#
根據抓包資訊 構造headers
request = urllib2.Request(PostUrl, data, headers)# 構造request請求
try: response = opener.open(request)
result = response.read()
print result # 列印登入後的頁面except urllib2.HTTPError,e:
print e.code#登入成功後便可以利用該openr訪問其他需要登入才能訪
#的頁面
res = opener.open("http://www.pceggs.com/Gain/Gnmain.aspx")
resu = response.read()print resu結果顯示成功