hive 操作(三)——hive 的資料模型
大的分類可分為:
(1)受控表(MANAGED_TABLE)
- 內部表
- 分割槽表
- 桶表
(2)外部表(external table)
和受控表不同,對外部表刪除,僅刪除引用,而不刪除真實儲存的資料;
內部表
(1)表定義
表定義,自然包含欄位定義,也即列定義;
hive> create table t1(id int); hive> show tables;我們也可進入瀏覽器端,輸入
hadoop0:50070,然後瀏覽檔案系統(Browse File System),進入/hive,會發現一個名為t1的資料夾。至此我們說,現在的hive使用的是mysql作為自己的metastore(對映工具);(2)載入資料
hive> load data local inpath 檔案 into table 表名; 如 hive> load data local inpath '/root/id' into table t1; # local:表示從本地的磁碟檔案進行載入 # 如果不帶local,表示從hdfs進行載入命令中含不含local,表示著兩種資料的載入方式。所以如果使用
hadoop fs -put id /hive/t1/id2(也即會從hdfs中載入資料),表t1也會將id2中的資料吸收進來。(3)定義多欄位表
hive> create table t2(id int, name string) row format delimited fields terminated by '\t'; # 以製表符區分不同的欄位在 hive 中除
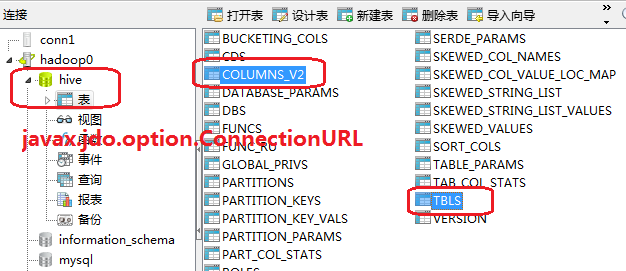
select *以外的操作,均走的是MapReduce的流程,因為select *是全表掃描?是否在新版的 hive 中,對查詢語句的支援有所提升,也即並非只有select *很快給出結果,不走MapReduce流程的不只select *一個;在對映工具metastore所在的倉庫,也即mysql中,此環境中的hive資料庫的TBLS表會對hive所建的表有所顯示(顯示的是表名),在COLUMNS_V2會顯示錶的欄位資訊;
分割槽表
可以根據欄位對資料分割槽;
(1)建立分割槽表
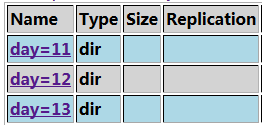
hive> create table t3(id int) partitioned by (day int); # 分割槽資訊形式上其實是一個欄位 # 這樣我們才可在select中利用where進行查詢;(2)載入資料到分割槽表
hive> load data local inpath '/root/id' into table t3 partition (day=11);我們可以將同樣的資料根據分割槽資訊載入到不同的檔案:
hive> load data local inpath '/root/id' into table t3 partition (day=12); hive> load data local inpath '/root/id' into table t3 partition (day=13);
這樣,根據某一劃分標準(比如按小時、按天),方便我們按照這一標準進行查詢(
select ** from table ** where day = 12;);所建的分割槽表,則就要利用分割槽資訊進行查詢,因為高效,如果還是用普通的欄位查詢的話,效率會很低,喪失建分割槽表的意義;
分割槽欄位選取的依據在於查詢的頻率,也即查詢頻率越高的資訊越作為分割槽欄位;
(3)桶表
常用在錶鏈接時;
和分割槽表一樣,也是對資料進行劃分,只不過劃分的依據有所不同。
桶表是對資料進行雜湊取值,然後放到不同檔案中儲存;
(1)建立桶表
hive> create table t4(id int) clustered by(id) into 4 buckets;(2)載入資料
a. 啟動桶機制,也即預設是不使用桶的
set hive.enforce.bucketing = true;b. 載入資料
insert into table t4 select id from t3;
(4)外部表
所謂的外部其實是指hdfs檔案系統;
[root@hadoop0 ~]# hadoop -put id /external/idhive> create external table t5(id int) location '/external';對外部表的刪除動作,僅刪除引用,而不會到外部檔案處,真正刪除資料。
hive> drop table t5;