
Hadoop MapReduce之Join示例
阿新 • • 發佈:2019-01-25
關於MR中的資料連線是在資料處理中經常遇到的問題,可以用一些上層框架來實現此功能,比如Hive、Pig等,這裡用MR實現主要是為了理解連線的思路,MR中的連線可以在Reduce端做,也可以在Map端做,本文分別展示兩種連線方式,想了解更多連線的內容可以參考<<hadoop in action>>5.2章節。
reduce端的連線方式
| 使用者訂單表order | 使用者資訊表user | |||||||||||||||||||||||||||||||||||
|
|
要對上面兩個表做關聯,關聯鍵為UserID,輸出結果如下:
| Country | UserName | UserID | OrderID |
| USA | Lamb | 1 | B100001 |
| USA | Lamb | 1 | B100004 |
| Brazil | Daniel | 3 | B100003 |
| Russia | Byrd | 2 | B100002 |
連線思路為Map端讀入兩個檔案的資料,輸出KEY:UserID 輸出Value:Object(包含來自哪個檔案的標記),在Reduce做連線,來自訂單表的每條記錄做一個輸出,格式為上面定義的格式,這裡假設user表的記錄是不重複的。下面看具體操作
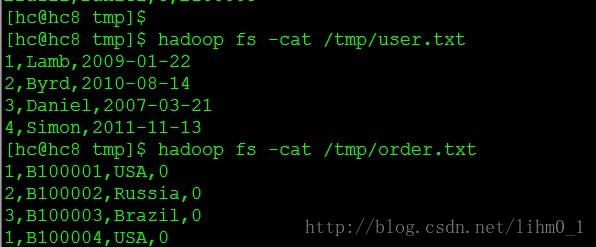
執行作業:

檢視結果:

具體程式碼如下:
map端的操作類:package com.join.reduceside; /** * 該類是一個JAVA BEAN,用於例項化檔案中的每條資料,由於需要在不同節點間傳輸,需要覆蓋Writable方法 */ import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Writable; public class Record implements Writable{ private String userID = ""; private String userName = ""; private String regTime = ""; private String orderID = ""; private String country = ""; private String state = ""; public String getState() { return state; } public void setState(String state) { this.state = state; } private String from; public String getUserID() { return userID; } public void setUserID(String userID) { this.userID = userID; } public String getUserName() { return userName; } public void setUserName(String userName) { this.userName = userName; } public String getRegTime() { return regTime; } public void setRegTime(String regTime) { this.regTime = regTime; } public String getOrderID() { return orderID; } public void setOrderID(String orderID) { this.orderID = orderID; } public String getCountry() { return country; } public void setCountry(String country) { this.country = country; } public String getFrom() { return from; } public void setFrom(String from) { this.from = from; } public Record(Record record) { this.userID = record.userID; this.userName = record.userName; this.regTime = record.regTime; this.orderID = record.orderID; this.country = record.country; this.state = record.state; this.from = record.from; } public Record() { } @Override public String toString() { return "coutry:"+this.getCountry()+" username:"+this.getUserName()+" userid:" + this.getUserID() + " regTime:" + this.getRegTime()+" orderid:"+this.orderID+" state:"+this.state; }; //////////////////////////////////////////////////////// // Writable //////////////////////////////////////////////////////// @Override public void readFields(DataInput din) throws IOException { this.userID = din.readUTF(); this.userName = din.readUTF(); this.regTime = din.readUTF(); this.orderID = din.readUTF(); this.country = din.readUTF(); this.state = din.readUTF(); this.from = din.readUTF(); } @Override public void write(DataOutput dout) throws IOException { dout.writeUTF(this.userID); dout.writeUTF(this.userName); dout.writeUTF(this.regTime); dout.writeUTF(this.orderID); dout.writeUTF(this.country); dout.writeUTF(this.state); dout.writeUTF(this.from); } }
package com.join.reduceside;
/**
* Map端程式碼,讀入order和user資料並例項化,傳輸到Reduce端進行連線
*/
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class JoinMap extends Mapper<LongWritable, Text, Text, Record>{
private static Record record;
protected void map(LongWritable key, Text value, Context context)
throws java.io.IOException ,InterruptedException {
record = new Record();
String line = value.toString();
String[] fields = line.split(",");
if(fields.length == 4){ //來自order表
record.setUserID(fields[0]);
record.setOrderID(fields[1]);
record.setCountry(fields[2]);
record.setState(fields[3]);
record.setFrom("order");//標記來自哪個檔案
context.write(new Text(record.getUserID()), record);
}else{//來自user表
record.setUserID(fields[0]);
record.setUserName(fields[1]);
record.setRegTime(fields[2]);
record.setFrom("user");//標記來自哪個檔案
context.write(new Text(record.getUserID()), record);
}
};
}
Reduce端的操作類,用於資料連線:
package com.join.reduceside;
/**
* Reduce操作類,用於關聯表資料
*/
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class JoinReduce extends Reducer<Text, Record, NullWritable, Text> {
protected void reduce(Text key, java.lang.Iterable<Record> values, Context context)
throws java.io.IOException ,InterruptedException {
Record userRecord = null;
Record tmpRecord = null;
List<Record> records = new ArrayList<Record>();
Iterator<Record> it = values.iterator();
while(it.hasNext()){
tmpRecord = it.next();
if(tmpRecord.getFrom().equals("user") && null == userRecord){//來自使用者表
userRecord = new Record(tmpRecord);//注意這裡一定要新建立一個Record記錄,負責會被覆蓋,因為這裡的Iterator已經被重寫
}else{//來自訂單表
records.add(new Record(tmpRecord));
}
}
//遍歷order記錄並輸出,空白欄位從user例項中獲取
for(Record orderRecord : records){
context.write(NullWritable.get(),
new Text(orderRecord.getCountry() + "," +
userRecord.getUserName() +"," +
userRecord.getUserID() +"," +
orderRecord.getOrderID()
));
}
}
}作業啟動:
public class JoinJob {
/**
* @param args
*/
public static void main(String[] args) throws Exception {
// 建立一個job
Configuration conf = new Configuration();
Job job = new Job(conf, "Join");
job.setJarByClass(JoinJob.class);
// 設定輸入輸出型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Record.class);
// 設定map和reduce類
job.setMapperClass(JoinMap.class);
job.setReducerClass(JoinReduce.class);
// 設定輸入輸出流
FileInputFormat.addInputPath(job, new Path("/tmp/user.txt"));
FileInputFormat.addInputPath(job, new Path("/tmp/order.txt"));
FileOutputFormat.setOutputPath(job, new Path("/tmp/output"));
job.waitForCompletion(true);
return;
}
}Map端的連線方式
package com.join.mapside;
/**
* Map端程式碼,利用快取中的記錄迴圈比較讀入的行記錄,符合條件的做Map輸出
*/
import java.io.BufferedReader;
import java.io.FileReader;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import com.join.reduceside.Record;
public class JoinMap extends Mapper<LongWritable, Text, Text, Record>{
//小表資料快取在Map中,每個Map在setup中做一次即可
private Map<String,Record> users = new HashMap<String,Record>();
private static Record record;
protected void setup(Context context) throws java.io.IOException ,InterruptedException {
String recordLine;
String[] recordFields;
//獲得小表資料檔案
Path[] userFiles = DistributedCache.getLocalCacheFiles(context.getConfiguration());
System.out.println(userFiles);
Path userFile = userFiles[0];
BufferedReader br = new BufferedReader(new FileReader(userFile.toString()));
//迴圈讀取資料,並存放在Map中
while(null != (recordLine = br.readLine())){
recordFields = recordLine.split(",");
users.put(recordFields[0], new Record(recordFields[0],recordFields[1],recordFields[2]));
}
};
protected void map(LongWritable key, Text value, Context context)
throws java.io.IOException ,InterruptedException {
record = new Record();
String line = value.toString();
String[] fields = line.split(",");
if(users.containsKey(fields[0])){
record.setCountry(fields[2]);
record.setUserName(users.get(fields[0]).getUserName());
record.setUserID(fields[0]);
record.setOrderID(fields[1]);
context.write(new Text(record.getUserID()), record);
}
};
}
package com.join.mapside;
/**
* Reduce操作類,輸出已經連線好的資料
*/
import java.util.Iterator;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import com.join.reduceside.Record;
public class JoinReduce extends Reducer<Text, Record, NullWritable, Text> {
protected void reduce(Text key, java.lang.Iterable<Record> values, Context context)
throws java.io.IOException ,InterruptedException {
Record resultRecord ;
Iterator<Record> it = values.iterator();
while(it.hasNext()){
resultRecord = it.next();
context.write(NullWritable.get(), new Text(resultRecord.getCountry()+ ","
+ resultRecord.getUserName()+","
+ resultRecord.getUserID() +","
+ resultRecord.getOrderID()
));
}
}
}package com.join.mapside;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.filecache.DistributedCache;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import com.join.reduceside.Record;
public class JoinJob {
/**
* @param args
*/
public static void main(String[] args) throws Exception {
// 建立一個job
Configuration conf = new Configuration();
Job job = new Job(conf, "Join_Map_Side");
job.setJarByClass(JoinJob.class);
// 設定輸入輸出型別
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Record.class);
// 設定map和reduce類
job.setMapperClass(JoinMap.class);
job.setReducerClass(JoinReduce.class);
//新增快取檔案
DistributedCache.addCacheFile(new Path("/tmp/user.txt").toUri(),
job.getConfiguration());
// 設定輸入輸出流
FileInputFormat.addInputPath(job, new Path("/tmp/order.txt"));
FileOutputFormat.setOutputPath(job, new Path("/tmp/output"));
job.waitForCompletion(true);
return;
}
}