
大型廣告系統架構概述
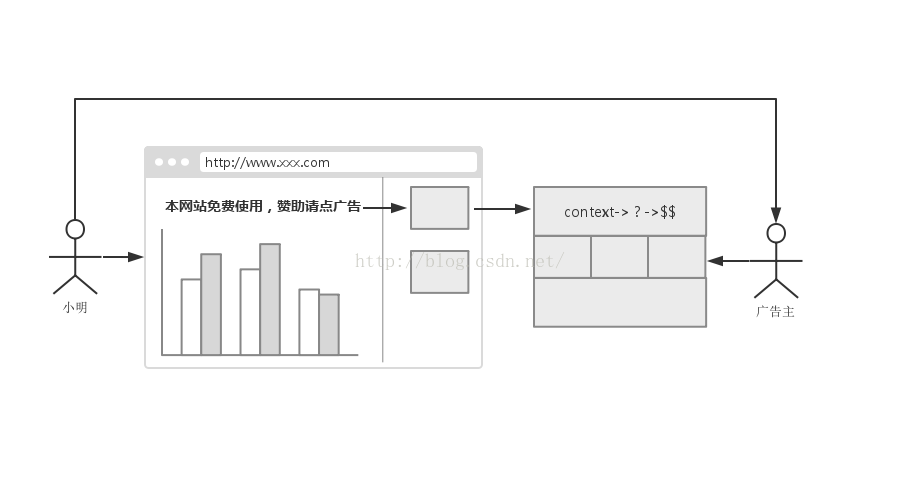
在網際網路江湖中,始終流傳著三大賺錢法寶:廣告、遊戲、電商。三傑之中,又以大哥廣告的歷史最為悠久,地位也最為不可撼動。君不見很多電商和遊戲公司,也通過廣告業務賺的盆滿鉢滿。其發跡於Y公司,被G公司發揚光大,又在F公司階段性地完成了其歷史使命。F公司,在移動網際網路興起之際,利用其得天獨厚的資料優勢,終於能夠回答困擾了廣告主幾百年的問題:我的廣告究竟被誰看到了?浪費的一半的錢到底去了哪裡?
從使用者角度來看,廣告其實是充斥著網際網路的每個角落,但正如習慣成自然一樣,對於越常見的事物,越少有人究其根本。對於網際網路技術人員來說,由於廣告業務具有高度的壟斷性,能夠接觸到其本質的工程師相對較少,尤其有過大型系統經驗的人更加稀缺。本文的目的在於對大型廣告系統的整體架構和其中的設計權衡點有一個全面的介紹,為有志從事該行業的工程師提供一套思考的思路。
另外有幾點說明。第一,廣告系統一般分為搜尋廣告和上下文廣告,由於上下文廣告系統面臨的問題要比搜尋廣告系統更加豐富,因此本文專注於討論上下文廣告系統。第二,本文適合對廣告業務有一定了解的工程師,對於業務不瞭解的同學,推薦閱讀劉鵬博士的<<計算廣告>>。
俗話說,離開業務談架構都是耍流氓。用一句標準的報告性語言介紹大型廣告系統的特點就是:處理的資料量特別巨大,響應速度要求特別快,資料實時性要求特別高,系統可用性要求特別高。面對種種不可思議的困難,最初的一批誤打誤撞進入廣告行業的的網際網路工程師們,本著賺錢的目的,通過演雜技一般的對各種技術的拼接,出色地完成了任務
-
資料量特別巨大
在上下文廣告中,系統中一般主要包含四種資料(廣告系統所有問題的討論一般都圍繞這四種資料展開)
廣告本身的資料。一般包括名字、出價、投放時間、有效性(預算)、標題、描述、跳轉連結、圖片、視訊等。這裡的資料量一般不會特別巨大。幾十萬的廣告主,已經足以支撐起業內頂尖的廣告公司,廣告的數量會比廣告主的數量大2個數量級左右。
廣告的定向資料。其資料量和系統提供的定向維度有關。例如使用者的搜尋記錄定向,網頁分詞定向,購買的商品記錄定向,APP安裝列表定向,使用者人群定向等。其中每一種定向維度中,廣告主都可以設定大量的定向資料。例如搜尋記錄定向中,廣告+關鍵詞的組合個數甚至會超過int最大值,如果在記憶體中高效地組織這些資料,是一個挑戰。
插一條案例。在團購大戰時代,某美國團購鼻祖高調殺入中國,曾經創下過購買百萬級關鍵詞的記錄,當然最後被中國的資本市場實實在在地教訓了一把,結果大家都知道。類似的不理智行為還曾發生在視訊大戰、電商大戰、分類資訊網站大戰,最終要麼合併,要麼抱大腿,唯留得廣告公司內心竊喜,期待下一場大戰爆發。
使用者的特徵資料。其資料量和麵向的市場有關。如果面向的是中國市場,那麼就要做好處理世界上最複雜問題的準備(下一個這樣體量的市場是印度)。君不見各家PR稿,沒有3億使用者都不好意思出來打招呼,且不說資料量是真是假以及是否有用,起碼這表明了大家都認可“使用者數量是衡量廣告系統優劣的一大標準”。進一步說,特徵資料是根據使用者的行為資料計算出來的(例如瀏覽過哪些頁面,購買過什麼物品)。數億的使用者,一般都會用歷史一段時間的行為資料和當天的行為資料,計算出使用者的歷史特徵和實時特徵。注意,使用者的行為資料包括使用者在廣告系統內部和外部兩種行為資料。使用者在廣告系統內部的行為資料包括使用者看到廣告的展示、點選廣告、以及發生轉化行為(CPA結算方式)等。使用者在廣告系統外部的行為資料包括網頁瀏覽記錄、交易記錄、APP使用記錄等。總體資料量是TB級別,而且也涉及到大量的計算,如何高效地計算和儲存這些資料,並且保證高效的查詢,是使用者資料處理的核心問題。當然,使用者資料是需要實時更新的,如果保證實時性在下文中討論。
廣告展示環境的特徵資料。展示環境一般分為網頁和APP。處理方法和使用者特徵資料類似,區別在於量級更加大,涉及的運算更加多。試想,將中國所有(重要的)網站的頁面爬取下來並分詞,再從其中提取出頁面的特徵資訊,需要處理的資料量級有多少。同時,頁面可能會經常變化,因此這項工作需要定期重做。這裡存在著投入和產出的衡量,例如訪問量很小的網站就沒必要抓取;小說類網站頁面量巨大,但對廣告投放的指導性很差,也可以不抓取;但垂直類網站一般都包含了明確的定向資訊,是處理的重點。
一般來說,使用者特徵和廣告展示環境特徵的資料會儲存在獨立的分散式叢集中。資料儲存在記憶體和磁碟兩級,記憶體中存放熱點資料,磁碟中存放全量資料。同時,記憶體中的資料包括歷史資料和實時資料兩部分,實時資料流會更新實時資料,在查詢的時候,叢集負責同時查歷史和實時兩份資料,合併後將結果返回。
廣告資料和廣告的定向資料一般儲存在檢索服務內部,在初期都是全記憶體的資料結構。當資料逐漸增長,超出單機記憶體儲存極限之後,可以先進行水平拆分,即多個檢索伺服器組成一個分組,一個分組維護全庫資料,在查詢時同時查詢一個分組內的每臺機器,由上游機器對結果做合併。再進一步,因為並不是所有資料都可以進行拆分,資料仍然可能超出單機儲存極限,這時可以採用記憶體-磁碟兩級儲存的結構,也可以拆分出單獨的服務。由於廣告系統一般都存在熱點資料,因此記憶體-磁碟兩級儲存是優先的考慮方案。同時,仔細地設計記憶體中的資料結構,高效地建立索引,能帶來巨大的收益。
一般系統使用的儲存結構是B+樹,如果使用不當會造成記憶體的巨大浪費,在後續的文章中會有專門的篇幅討論這個問題
-
響應速度要求特別快
這一點毋庸置疑,廣告對於網站或者APP是附加功能,只能比內容更快地展現給使用者。同時,一些特定的廣告形式對使用者有跳出感,例如開屏、插屏廣告,對響應時間要求更加短。另外,在RTB系統中,由於exchange的存在,增加了一次網路請求,DSP系統的響應時間就要更加短。一般來說,一次對廣告系統的請求必須在100ms以內完成。其中60%-70%的時間消耗在網路中,另外的部分是主要消耗在核心檢索模組中。
網路包括媒體和廣告系統之間的網路,和廣告系統各模組之間的網路互動。在設計架構時,既要保持系統一定的可擴充套件性和可伸縮性,也要考慮儘可能地減少內部網路請求次數。同時,在設計和選擇RPC框架時,要充分考慮QPS,latency,請求長度三個因素。
核心檢索模組中,一次請求會觸發多個定向策略同時檢索,因此索引資料設計的是否高效是決定檢索性效能的核心要素。因為大量的查詢操作,CPU往往會成為檢索系統的瓶頸,所以很多檢索模組的QPS並不高。在實戰中,對索引的使用不當也會造成效能的下降,因此需要工程能力比較強的人做 code review 把關。
-
實時性要求特別高
實時性是指資料更新的實時性。下面逐條討論。
廣告資料的實時性。這裡最頻繁變化的是廣告有效性和出價。例如,廣告必須在廣告主指定的時間段內投放,時間變化時,必須及時上下線。廣告主出價發生變化時,必須立即反饋到系統中。廣告預算消費完畢後,必須立即將廣告下線。
以CPC系統為例,曾經有很長一段時間,很多廣告主利用廣告系統計費的延遲性騙取大量的點選。例如,給廣告設定一個很小的預算(可能只夠一次點選),實際產生點選和檢索系統接收到計費資料之間,可能會有分鐘級的延遲,這期間發生的其他點選,產生的費用廣告主就無需支付。
廣告定向資料的實時性。與廣告資料類似,不展開討論。
使用者特徵資料的實時性。使用者特徵資料往往是根據使用者的歷史行為計算出的一些興趣點資料,在起初對實時性的要求並不是很高,主要是因為使用者的興趣點形成往往是一個長期過程,並且變化很平緩。例如,喜歡足球的使用者可能每天都會看一下體育新聞的足球頁面,餐飲、母嬰、裝修、軍事等垂直領域的使用者,也會長期關注相關網站。然而隨著電商的興起,以及移動網際網路將時間更加碎片化,使用者的興趣點轉移變得非常快。例如,某使用者最近對相機比較感興趣,在某電商網站瀏覽了10分鐘相機產品後離開,開啟入口網站開始瀏覽新聞,這時如果出現了相機廣告,將很可能引起轉化,這其實是電商類廣告最有效的定向方式——retargeting。當然,這只是為了說明實時性的重要程度而舉的一個非常粗淺的例子,其中有很多細節有待考量。例如使用者如果發生了購買行為之後,顯然不應該再推送相機廣告。有些快消類產品,重複購買率高,可以定期給使用者推薦,但類似相機、汽車、房產等大宗商品,在使用者發生購買後,顯然不應該再繼續投放,而應該投放與此相關的其他廣告。在策略處理上,對不同型別的興趣點的時效性應該區別對待。
另外,在RTB系統中,這一點尤為重要。試想相機的例子,當用戶已經發生購買之後,DSP如果沒有識別出該行為,認為使用者仍然具有該興趣點,繼續出高價購買流量,顯然是收益極低甚至可能虧損的。
廣告展示環境的特徵資料的實時性。網頁和APP的內容一般不經常發生變化,抓取一次可以在很長一段時間內是有效的。比較特殊的是新頁面,尤其是內容類網站(例如旅遊攻略,實時新聞),每天會產生大量的新頁面,如果不能及時抓取,在廣告投放過程中就無法利用廣告展示環境的資料。尤其在移動端,使用者的場景化更加強烈,在未來場景定向的重要程度很可能會超過使用者定向。在傳統的PC廣告系統中,一般是將網站分級,優先順序越高的網站爬去的頻率越高,甚至是API對接。在移動端,有一種方案是在請求中帶入網頁的重要特徵,例如標題、重要關鍵詞等,這需要媒體的支援,廣泛使用還有待時日。另外,實戰中還往往採用 near line 的設計模型,即當發現請求中出現了新的頁面,實時通知爬蟲立即爬去並分析,在處理後續的請求中使用。
使用者特徵資料和網頁/APP的特徵資料往往資料量巨大,為了能夠高效地利用記憶體,儲存這些資料的快取叢集往往使用了只能提供讀取功能的資料結構。因此,一般是將歷史的特徵和實時的特徵分開儲存在不同的資料結構中,實時的特徵可以隨時更新,只儲存當天資料,在查詢時,同時查詢兩個資料結構,將結果合併後返回。
-
系統可用性要求特別高
這一點比較容易理解,分分鐘都是錢,所以廣告系統一般都有大量的熱備冗餘機器,部署在多地多個機房。除了常見的分散式系統高可用方案之外,廣告系統還有如下兩個重要的方案。
自動降級。由於上文討論的實時性問題,廣告系統很難像傳統使用者類網站一樣,提供一些靜態的只讀內容,以備在叢集全體宕機的時候使用。但在系統內部設計中,可以做到模組級別的容災,系統化點的稱為叫自動降級。即當某些模組出現問題的時候,或者系統資源不夠用的時候,系統能夠自動地移除出問題的模組,或者非核心模組,保證基本功能可用。比較典型的例子是,如果某一種策略的計算邏輯出現問題,或者CTR預估叢集整體宕機,系統還能夠正常返回廣告,只是收益不如原來高。當然,自動降級只是一種防禦手段,當發生這種情況的時候,應該視為線上叢集整體宕機同等嚴重的事故,必須第一時間處理。例外的情況是自動降級是人為預期的,例如有些業務激增場景一年只發生一次,公司不可能為此常年準備大量機器,此時也可以用自動降級的手段保證業務基本可用。
減少啟動時間。前文提到,大型廣告系統使用的資料量甚至會超過單機記憶體極限,這時系統的啟動時間會非常可觀。例如筆者曾經開發過的廣告系統,即使進行了水平拆庫,單機使用記憶體仍然達到50G以上,啟動時間在30分鐘左右,經過後續的優化減少到15分鐘。減少啟動時間,主要好處有兩個:減少運維成本,減少容災成本。
減少運維成本。和其他網際網路系統一樣,廣告系統也會採用快速迭代的上線方案。有幾千臺伺服器的廣告系統,可能會一週多次上線。上線時,為了使服務仍然可用,會分批操作,例如一次只操作5%的機器。這對運維人員是非常痛苦的一個過程。例如1000臺機器,每次操作5%,每臺機器啟動時間在30分鐘,整體上線流程將達到10小時,這樣的事情每週發生幾次,顯然是無法接受的。當然,可以選擇流量低谷的時間段上線,增加每次操作的機器數量,這樣又引入了運維成本。因此減少系統啟動時間意義重大。
減少容災成本。很長的啟動時間,會使系統在請求量激增的情況下無法及時使用冷備機器擴容,而增加很多熱備機器,第一會增加成本,第二實際情況還是可能會超出預留。而且,當熱備機器也難以處理所有請求時,很可能會導致剛剛啟動完畢的機器也被打滿而無法正常提供服務,觸發雪崩效應。此時,必須切斷所有服務,重啟叢集,等所有服務都重啟並檢驗資料完畢後,才能開始對外提供服務。一般來說,當我們聽說一些大型網站發生整體宕機,若干小時後才恢復,很可能都是發生了雪崩事故。
據說,歷史上某E字輩美國購物網站曾經發生過一次這樣的案例,導致整體服務宕機8小時。近兩年Amazon的公開的幾次事故恢復時間也都在小時甚至天級別,都和複雜的啟動流程有關。
作為大型廣告系統架構的開篇,本文主要闡述了大型廣告系統面臨的核心問題的業務來源、處理方案、以及選擇方案的時候考慮的一些權衡點。在接下來的文章中,會深入每個模組,詳細地討論技術細節。下一篇會重點討論檢索模組,歡迎關注。