
普通索引和唯一索引的區別、效能差異,以及其他索引簡介
今天在我的虛擬機器中佈置了環境,測試抓圖如下:
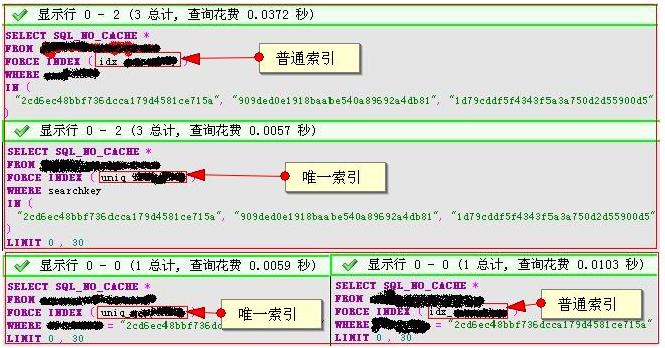
抓的這幾個都是第一次執行的,刷了幾次後,取平均值,效率大致相同,而且如果在一個列上同時建唯一索引和普通索引的話,mysql會自動選擇唯一索引。
谷歌一下:
唯一索引和普通索引使用的結構都是B-tree,執行時間複雜度都是O(log n)。
1、普通索引
普通索引(由關鍵字KEY或INDEX定義的索引)的唯一任務是加快對資料的訪問速度。因此,應該只為那些最經常出現在查詢條件(WHEREcolumn=)或排序條件(ORDERBYcolumn)中的資料列建立索引。只要有可能,就應該選擇一個數據最整齊、最緊湊的資料列(如一個整數型別的資料列)來建立索引。
2、唯一索引
普通索引允許被索引的資料列包含重複的值。比如說,因為人有可能同名,所以同一個姓名在同一個“員工個人資料”資料表裡可能出現兩次或更多次。
如果能確定某個資料列將只包含彼此各不相同的值,在為這個資料列建立索引的時候就應該用關鍵字UNIQUE把它定義為一個唯一索引。這麼做的好處:一是簡化了MySQL對這個索引的管理工作,這個索引也因此而變得更有效率;二是MySQL會在有新記錄插入資料表時,自動檢查新記錄的這個欄位的值是否已經在某個記錄的這個欄位裡出現過了;如果是,MySQL將拒絕插入那條新記錄。也就是說,唯一索引可以保證資料記錄的唯一性。事實上,在許多場合,人們建立唯一索引的目的往往不是為了提高訪問速度,而只是為了避免資料出現重複。
3.主索引
在前面已經反覆多次強調過:必須為主鍵欄位建立一個索引,這個索引就是所謂的"主索引"。主索引與唯一索引的唯一區別是:前者在定義時使用的關鍵字是PRIMARY而不是UNIQUE。
4.外來鍵索引
如果為某個外來鍵欄位定義了一個外來鍵約束條件,MySQL就會定義一個內部索引來幫助自己以最有效率的方式去管理和使用外來鍵約束條件。
5.複合索引
索引可以覆蓋多個數據列,如像INDEX(columnA, columnB)索引。這種索引的特點是MySQL可以有選擇地使用一個這樣的索引。如果查詢操作只需要用到columnA資料列上的一個索引,就可以使用複合索引INDEX(columnA, columnB)。不過,這種用法僅適用於在複合索引中排列在前的資料列組合。比如說,INDEX(A,
B, C)可以當做A或(A, B)的索引來使用,但不能當做B、C或(B, C)的索引來使用。
6全文索引
文字欄位上的普通索引只能加快對出現在欄位內容最前面的字串(也就是欄位內容開頭的字元)進行檢索操作。如果欄位裡存放的是由幾個、甚至是多個單詞構成的較大段文字,普通索引就沒什麼作用了。這種檢索往往以LIKE %word%的形式出現,這對MySQL來說很複雜,如果需要處理的資料量很大,響應時間就會很長。
這類場合正是全文索引(full-text index)可以大顯身手的地方。在生成這種型別的索引時,MySQL將把在文字中出現的所有單詞建立為一份清單,查詢操作將根據這份清單去檢索有關的資料記錄。全文索引即可以隨資料表一同建立,也可以等日後有必要時再使用下面這條命令新增:
ALTER TABLE tablename ADD FULLTEXT(column1, column2)
有了全文索引,就可以用SELECT查詢命令去檢索那些包含著一個或多個給定單詞的資料記錄了。下面是這類查詢命令的基本語法:
SELECT * FROM tablename
WHERE MATCH(column1, column2) AGAINST('word1', 'word2', 'word3')
上面這條命令將把column1和column2欄位裡有word1、word2和word3的資料記錄全部查詢出來。
註解:InnoDB資料表不支援全文索引。
查詢和索引的優化
只有當資料庫裡已經有了足夠多的測試資料時,它的效能測試結果才有實際參考價值。如果在測試資料庫裡只有幾百條資料記錄,它們往往在執行完第一條查詢命令之後就被全部載入到記憶體裡,這將使後續的查詢命令都執行得非常快--不管有沒有使用索引。只有當資料庫裡的記錄超過了1000條、資料總量也超過了MySQL伺服器上的記憶體總量時,資料庫的效能測試結果才有意義。
在不確定應該在哪些資料列上建立索引的時候,人們從EXPLAIN SELECT命令那裡往往可以獲得一些幫助。這其實只是簡單地給一條普通的SELECT命令加一個EXPLAIN關鍵字作為字首而已。有了這個關鍵字,MySQL將不是去執行那條SELECT命令,而是去對它進行分析。MySQL將以表格的形式把查詢的執行過程和用到的索引(如果有的話)等資訊列出來。
在EXPLAIN命令的輸出結果裡,第1列是從資料庫讀取的資料表的名字,它們按被讀取的先後順序排列。type列指定了本資料表與其它資料表之間的關聯關係(JOIN)。在各種型別的關聯關係當中,效率最高的是system,然後依次是const、eq_ref、ref、range、index和All(All的意思是:對應於上一級資料表裡的每一條記錄,這個資料表裡的所有記錄都必須被讀取一遍--這種情況往往可以用一索引來避免)。
possible_keys資料列給出了MySQL在搜尋資料記錄時可選用的各個索引。key資料列是MySQL實際選用的索引,這個索引按位元組計算的長度在key_len資料列裡給出。比如說,對於一個INTEGER資料列的索引,這個位元組長度將是4。如果用到了複合索引,在key_len資料列裡還可以看到MySQL具體使用了它的哪些部分。作為一般規律,key_len資料列裡的值越小越好(意思是更快)。
ref資料列給出了關聯關係中另一個數據表裡的資料列的名字。row資料列是MySQL在執行這個查詢時預計會從這個資料表裡讀出的資料行的個數。row資料列裡的所有數字的乘積可以讓我們大致瞭解這個查詢需要處理多少組合。