
RDBMS分散式兩階段提交與Zookeeper的Paxos同步演算法
一 Oracle分散式事務和兩階段提交(2PC)
分散式事務是指發生在多臺資料庫之間的事務,Oracle中通過dblink方式進行事務處理,分散式事務比單機事務要複雜的多。大部分的關係型資料庫通過兩階段提交(2 Phase Commit 2PC)演算法來完成分散式事務,下面重點介紹下2PC演算法。
1、分散式事務的組成
在分散式事務中,主要有以下幾個組成部分:
- Client:呼叫其它資料庫資訊的節點
- Database:接受來自其它節點請求的節點
- Global Coordinator (GC):發起分散式事務的節點
- Local Coordinator (LC):處理本地事務,並和其它節點通訊的節點
- Commit Point Site (CPS):被Global Coordinator指定首先提交或回滾事務的節點
 在分散式事務中,Commit Point Site非常重要,它不需要進入2PC的Prepared 狀態,因為它通常操作最關鍵資料,所以它不會出現in-doubt狀態。Commit Point Site總是優先於其它資料庫節點先提交,目的在於保護最關鍵的資料,它決定整個分散式事務是提交還是回滾。分散式事務中其它資料庫節點在GC的指揮下進行後續的提交(或回滾)。
那麼在Oracle中如何選取Commit Point Site呢?它是根據引數commi_ point_strength 最大的資料庫作為Commit Point Site。
在分散式事務中,Commit Point Site非常重要,它不需要進入2PC的Prepared 狀態,因為它通常操作最關鍵資料,所以它不會出現in-doubt狀態。Commit Point Site總是優先於其它資料庫節點先提交,目的在於保護最關鍵的資料,它決定整個分散式事務是提交還是回滾。分散式事務中其它資料庫節點在GC的指揮下進行後續的提交(或回滾)。
那麼在Oracle中如何選取Commit Point Site呢?它是根據引數commi_ point_strength 最大的資料庫作為Commit Point Site。
2、兩階段提交(2PC)
1)Prepare Phase
在請求階段,協調者將通知事務參與者準備提交或取消事務,然後進入表決過程。在表決過程中,參與者將告知協調者自己的決策:同意(事務參與者本地作業執行成功)或取消(本地作業執行故障)。 為了完成準準備階段,除了commit point site外,其它的資料庫節點按照以下步驟執行:- 每個節點檢查自己是否被其它節點所引用,如果有,就通知這些節點準備提交(進入 Prepare階段)。
- 每個節點檢查自己執行的事務,如果發現本地執行的事務沒有修改資料的操作(只讀),則跳過後面的步驟,直接返回一個read only給全域性協調器。
- 如果事務需要修改資料,則為事務分配相應的資源用於保證修改的正常進行。
- 當上面的工作都成功後,給全域性協調器返回準備就緒的資訊,反之,則返回失敗的資訊。
2) Commit Phase
在該階段,協調者將基於第一個階段的投票結果進行決策:提交或取消。當且僅當所有的參與者同意提交事務協調者才通知所有的參與者提交事務,否則協調者將通知所有的參與者取消事務。參與者在接收到協調者發來的訊息後將執行響應的操作。 提交階段按下面的步驟進行:- 全域性協調器通知 commit point site 進行提交。
- commit point site 提交,完成後通知全域性協調器。
- 全域性協調器通知其它節點進行提交。
- 其它節點各自提交本地事務,完成後釋放鎖和資源。
- 其它節點通知全域性協調器提交完成。
3)結束階段
- 全域性協調器通知commit point site說所有節點提交完成。
- commit point site資料庫釋放和事務相關的所有資源,然後通知全域性協調器。
- 全域性協調器釋放自己持有的資源。
- 分散式事務結束
唯一一個兩階段提交不能解決的困境是:當協調者在發出commit 訊息後宕機,而唯一收到這條命令的一個參與者也宕機了,這個時候這個事務就處於一個未知的狀態,沒有人知道這個事務到底是提交了還是未提交,從而需要資料庫管理員的介入,防止資料庫進入一個不一致的狀態。當然,如果有一個前提是:所有節點或者網路的異常最終都會恢復,那麼這個問題就不存在了,協調者和參與者最終會重啟,其他節點也最終會收到commit 的資訊。這也符合CAP理論。
二 Paxos演算法與Zookeeper分析
1 Paxos演算法
1.1 基本定義
演算法中的參與者主要分為三個角色,同時每個參與者又可兼領多個角色:
⑴proposer 提出提案,提案資訊包括提案編號和提議的value;
⑵acceptor 收到提案後可以接受(accept)提案;
⑶learner只能"學習"被批准的提案;
演算法保重一致性的基本語義:
⑴決議(value)只有在被proposers提出後才能被批准(未經批准的決議稱為"提案(proposal)");
⑵在一次Paxos演算法的執行例項中,只批准(chosen)一個value;
⑶learners只能獲得被批准(chosen)的value;
有上面的三個語義可演化為四個約束:
⑴P1:一個acceptor必須接受(accept)第一次收到的提案;
⑵P2a:一旦一個具有value v的提案被批准(chosen),那麼之後任何acceptor 再次接受(accept)的提案必須具有value v;
⑶P2b:一旦一個具有value v的提案被批准(chosen),那麼以後任何 proposer 提出的提案必須具有value v;
⑷P2c:如果一個編號為n的提案具有value v,那麼存在一個多數派,要麼他們中所有人都沒有接受(accept)編號小於n的任何提案,要麼他們已經接受(accpet)的所有編號小於n的提案中編號最大的那個提案具有value v;
1.2 基本演算法(basic paxos)
演算法(決議的提出與批准)主要分為兩個階段:
1. prepare階段:
(1). 當Porposer希望提出方案V1,首先發出prepare請求至大多數Acceptor。Prepare請求內容為序列號<SN1>;
(2). 當Acceptor接收到prepare請求<SN1>時,檢查自身上次回覆過的prepare請求<SN2>
a). 如果SN2>SN1,則忽略此請求,直接結束本次批准過程;
b). 否則檢查上次批准的accept請求<SNx,Vx>,並且回覆<SNx,Vx>;如果之前沒有進行過批准,則簡單回覆<OK>;
2. accept批准階段:
(1a). 經過一段時間,收到一些Acceptor回覆,回覆可分為以下幾種:
a). 回覆數量滿足多數派,並且所有的回覆都是<OK>,則Porposer發出accept請求,請求內容為議案<SN1,V1>;
b). 回覆數量滿足多數派,但有的回覆為:<SN2,V2>,<SN3,V3>……則Porposer找到所有回覆中超過半數的那個,假設為<SNx,Vx>,則發出accept請求,請求內容為議案<SN1,Vx>;
c). 回覆數量不滿足多數派,Proposer嘗試增加序列號為SN1+,轉1繼續執行;
(1b). 經過一段時間,收到一些Acceptor回覆,回覆可分為以下幾種:
a). 回覆數量滿足多數派,則確認V1被接受;
b). 回覆數量不滿足多數派,V1未被接受,Proposer增加序列號為SN1+,轉1繼續執行;
(2). 在不違背自己向其他proposer的承諾的前提下,acceptor收到accept 請求後即接受並回復這個請求。
1.3 演算法優化(fast paxos)
Paxos演算法在出現競爭的情況下,其收斂速度很慢,甚至可能出現活鎖的情況,例如當有三個及三個以上的proposer在傳送prepare請求後,很難有一個proposer收到半數以上的回覆而不斷地執行第一階段的協議。因此,為了避免競爭,加快收斂的速度,在演算法中引入了一個Leader這個角色,在正常情況下同時應該最多隻能有一個參與者扮演Leader角色,而其它的參與者則扮演Acceptor的角色,同時所有的人又都扮演Learner的角色。
在這種優化演算法中,只有Leader可以提出議案,從而避免了競爭使得演算法能夠快速地收斂而趨於一致,此時的paxos演算法在本質上就退變為兩階段提交協議。但在異常情況下,系統可能會出現多Leader的情況,但這並不會破壞演算法對一致性的保證,此時多個Leader都可以提出自己的提案,優化的演算法就退化成了原始的paxos演算法。
一個Leader的工作流程主要有分為三個階段:
(1).學習階段 向其它的參與者學習自己不知道的資料(決議);
(2).同步階段 讓絕大多數參與者保持資料(決議)的一致性;
(3).服務階段 為客戶端服務,提議案;
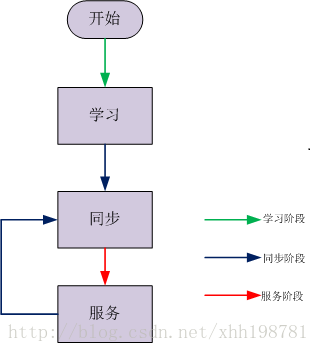
1.3.1 學習階段
當一個參與者成為了Leader之後,它應該需要知道絕大多數的paxos例項,因此就會馬上啟動一個主動學習的過程。假設當前的新Leader早就知道了1-134、138和139的paxos例項,那麼它會執行135-137和大於139的paxos例項的第一階段。如果只檢測到135和140的paxos例項有確定的值,那它最後就會知道1-135以及138-140的paxos例項。
1.3.2 同步階段
此時的Leader已經知道了1-135、138-140的paxos例項,那麼它就會重新執行1-135的paxos例項,以保證絕大多數參與者在1-135的paxos例項上是保持一致的。至於139-140的paxos例項,它並不馬上執行138-140的paxos例項,而是等到在服務階段填充了136、137的paxos例項之後再執行。這裡之所以要填充間隔,是為了避免以後的Leader總是要學習這些間隔中的paxos例項,而這些paxos例項又沒有對應的確定值。
1.3.4 服務階段
Leader將使用者的請求轉化為對應的paxos例項,當然,它可以併發的執行多個paxos例項,當這個Leader出現異常之後,就很有可能造成paxos例項出現間斷。
1.3.5 問題
(1).Leader的選舉原則
(2).Acceptor如何感知當前Leader的失敗,客戶如何知道當前的Leader
(3).當出現多Leader之後,如何kill掉多餘的Leader
(4).如何動態的擴充套件Acceptor
2. Zookeeper
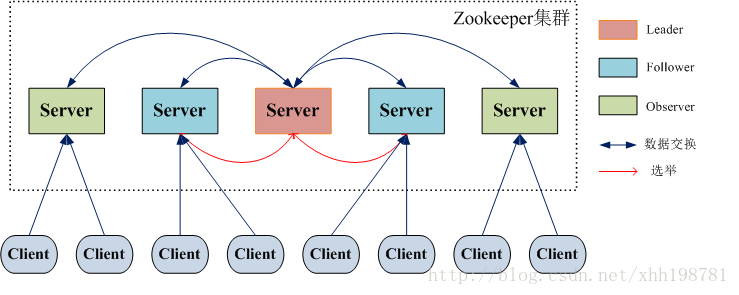
2.1 整體架構
在Zookeeper叢集中,主要分為三者角色,而每一個節點同時只能扮演一種角色,這三種角色分別是:
(1). Leader 接受所有Follower的提案請求並統一協調發起提案的投票,負責與所有的Follower進行內部的資料交換(同步);
(2). Follower 直接為客戶端服務並參與提案的投票,同時與Leader進行資料交換(同步);
(3). Observer 直接為客戶端服務但並不參與提案的投票,同時也與Leader進行資料交換(同步);
2.2 QuorumPeer的基本設計
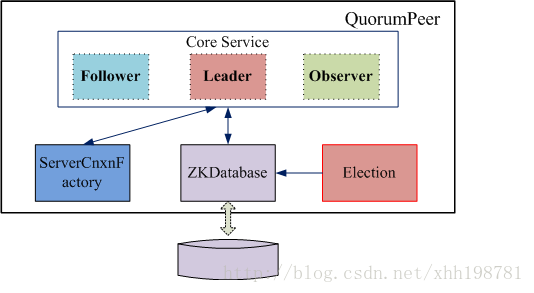
Zookeeper對於每個節點QuorumPeer的設計相當的靈活,QuorumPeer主要包括四個元件:客戶端請求接收器(ServerCnxnFactory)、資料引擎(ZKDatabase)、選舉器(Election)、核心功能元件(Leader/Follower/Observer)。其中:
(1). ServerCnxnFactory負責維護與客戶端的連線(接收客戶端的請求併發送相應的響應);
(2). ZKDatabase負責儲存/載入/查詢資料(基於目錄樹結構的KV+操作日誌+客戶端Session);
(3). Election負責選舉叢集的一個Leader節點;
(4). Leader/Follower/Observer一個QuorumPeer節點應該完成的核心職責;
2.3 QuorumPeer工作流程
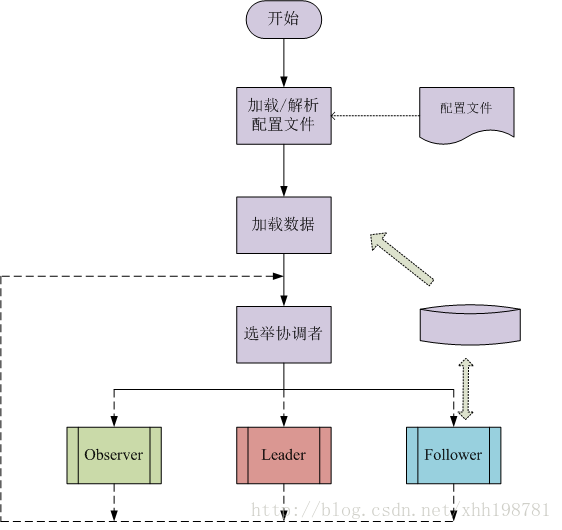
2.3.1 Leader職責
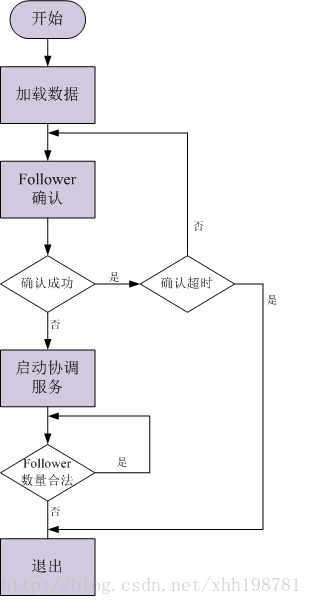
Follower確認: 等待所有的Follower連線註冊,若在規定的時間內收到合法的Follower註冊數量,則確認成功;否則,確認失敗。
2.3.2 Follower職責
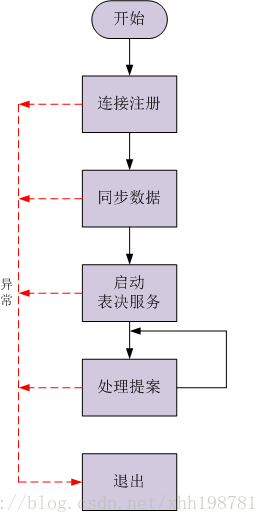
2.4 選舉演算法
2.4.1LeaderElection選舉演算法
選舉執行緒由當前Server發起選舉的執行緒擔任,他主要的功能對投票結果進行統計,並選出推薦的Server。選舉執行緒首先向所有Server發起一次詢問(包括自己),被詢問方,根據自己當前的狀態作相應的回覆,選舉執行緒收到回覆後,驗證是否是自己發起的詢問(驗證xid 是否一致),然後獲取對方的id(myid),並存儲到當前詢問物件列表中,最後獲取對方提議 的
leader 相關資訊(id,zxid),並將這些 資訊儲存到當次選舉的投票記錄表中,當向所有Serve r
都詢問完以後,對統計結果進行篩選並進行統計,計算出當次詢問後獲勝的是哪一個Server,並將當前zxid最大的Server 設定為當前Server要推薦的Server(有可能是自己,也有可以是其它的Server,根據投票結果而定,但是每一個Server在第一次投票時都會投自己),如果此時獲勝的Server獲得n/2 + 1的Server票數,設定當前推薦的leader為獲勝的Server。根據獲勝的Server相關資訊設定自己的狀態。每一個Server都重複以上流程直到選舉出Leader。
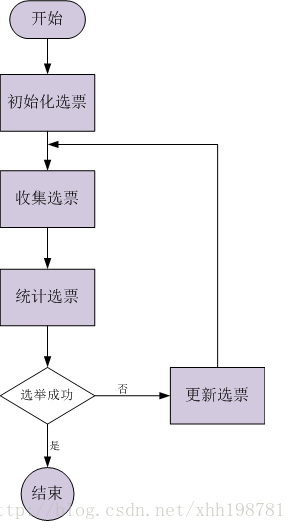
初始化選票(第一張選票): 每個quorum節點一開始都投給自己;
收集選票: 使用UDP協議儘量收集所有quorum節點當前的選票(單執行緒/同步方式),超時設定200ms;
統計選票: 1).每個quorum節點的票數;
2).為自己產生一張新選票(zxid、myid均最大);
選舉成功: 某一個quorum節點的票數超過半數;
更新選票: 在本輪選舉失敗的情況下,當前quorum節點會從收集的選票中選取合適的選票(zxid、myid均最大)作為自己下一輪選舉的投票;
異常問題的處理
1). 選舉過程中,Server的加入
當一個Server啟動時它都會發起一次選舉,此時由選舉執行緒發起相關流程,那麼每個 Serve r都會獲得當前zxi d最大的哪個Serve r是誰,如果當次最大的Serve r沒有獲得n/2+1 個票數,那麼下一次投票時,他將向zxid最大的Server投票,重複以上流程,最後一定能選舉出一個Leader。
2). 選舉過程中,Server的退出
只要保證n/2+1個Server存活就沒有任何問題,如果少於n/2+1個Server 存活就沒辦法選出Leader。
3). 選舉過程中,Leader死亡
當選舉出Leader以後,此時每個Server應該是什麼狀態(FLLOWING)都已經確定,此時由於Leader已經死亡我們就不管它,其它的Fllower按正常的流程繼續下去,當完成這個流程以後,所有的Fllower都會向Leader傳送Ping訊息,如果無法ping通,就改變自己的狀為(FLLOWING ==> LOOKING),發起新的一輪選舉。
4). 選舉完成以後,Leader死亡
處理過程同上。
5). 雙主問題
Leader的選舉是保證只產生一個公認的Leader的,而且Follower重新選舉與舊Leader恢復並退出基本上是同時發生的,當Follower無法ping同Leader是就認為Leader已經出問題開始重新選舉,Leader收到Follower的ping沒有達到半數以上則要退出Leader重新選舉。
2.4.2 FastLeaderElection選舉演算法
FastLeaderElection是標準的fast paxos的實現,它首先向所有Server提議自己要成為leader,當其它Server收到提議以後,解決 epoch 和 zxid 的衝突,並接受對方的提議,然後向對方傳送接受提議完成的訊息。
FastLeaderElection演算法通過非同步的通訊方式來收集其它節點的選票,同時在分析選票時又根據投票者的當前狀態來作不同的處理,以加快Leader的選舉程序。
相關推薦
RDBMS分散式兩階段提交與Zookeeper的Paxos同步演算法
一 Oracle分散式事務和兩階段提交(2PC) 分散式事務是指發生在多臺資料庫之間的事務,Oracle中通過dblink方式進行事務處理,分散式事務比單機事務要複雜的多。大部分的關係型資料庫通過兩階段提交(2 Phase Commit 2PC)演算法來完成分散式事務,
分散式系統原理(7)兩階段提交協議
兩階段提交協議 問題背景 兩階段提交(two phase commit)協議是一種歷史悠久的分散式控制協議。最早用於在分散式資料庫中,實現分散式事務。這裡有必要首先簡單介紹一下兩階段提交的最初問題背景,從而能更好的理解該協議 在經典的分散式資料庫模型中,同一個資料庫的各個副本
關於分散式事務、兩階段提交協議、三階提交協議
分散式一致性回顧 在分散式系統中,為了保證資料的高可用,通常,我們會將資料保留多個副本(replica),這些副本會放置在不同的物理的機器上。為了對使用者提供正確的增\刪\改\差等語義,我們需要保證這些放置在不同物理機器上的副本是一致的。 為了解決這種分散式一致性問題
分散式事務-二階段提交與三階段提交
一、二階段提交演算法描述 在分散式系統中,事務往往包含有多個參與者的活動,單個參與者上的活動是能夠保證原子性的,而多個參與者之間原子性的保證則需要通過兩階段提交來實現,兩階段提交是分散式事務實現的關鍵。 很明顯,兩階段提交保證了分散式事務的原子性,
分散式事務:兩階段提交、一階段提交、事務補償機制
1.XA XA是由X/Open組織提出的分散式事務的規範。XA規範主要定義了(全域性)事務管理器(Transaction Manager)和(區域性)資源管理器(Resource Manager)之間的介面。XA介面是雙向的系統介面,在事務管理器(Transactio
分散式事務-兩階段提交的錯誤恢復
錯誤恢復是應用程式程式設計、系統管理和運維的一個常見任務。對於部署在多個遠端伺服器上的分散式資料庫而言,發生網路和通訊故障的概率更高。為了確保資料完整性,資料庫管理員提供了兩階段提交流程。下面解釋了DBA如何處理兩階段提交過程中發生的錯誤:階段1錯誤如果一個數據庫說它沒有準備好提交工作單元,資料庫客戶端將在
MySQL binlog 組提交與 XA(分布式事務、兩階段提交)【轉】
pre title 解決 不支持 get com 延遲 最大 href Reference: https://www.cnblogs.com/zhoujinyi/p/5257558.html 概念: XA(分布式事務)規範主要定義了(全局)事務管理器(TM:
分散式事務一致性之兩階段提交
1.分散式事務 分散式事務是指會涉及到操作多個數據庫的事務。其實就是將對同一庫事務的概念擴大到了對多個庫的事務。目的是為了保證分散式系統中的資料一致性。分散式事務處理的關鍵是必須有一種方法可以知道事務在任何地方所做的所有動作,提交或回滾事務的決定必須產生統一的
事務與兩階段提交
事務 事務是保證資料庫從一個一致性的狀態永久性地變成另一個一致性狀態的根基ACID ACID是事務基本特性: A是Atomicity,原子性。一個事務往往涉及到許多的子操作,原子性則保證這些子操作要麼都做,要麼都不做,不能出現部分操作成功,而另外一部分操作失敗情形,基於此原
對分布式事務及兩階段提交、三階段提交的理解
似的 zookeeper ole 持久性 完全 rep 反饋 對數 服務器 轉載至:http://www.cnblogs.com/binyue/p/3678390.html,最近學習需要,先轉載方便用用來強化加深印象 一、分布式數據一致性 在分布式系統中,為了保證數據的
關於分布式事務、兩階段提交協議、三階提交協議
可用 正式 一句話 應用程序 回滾 版本 article none 大型 http://blog.jobbole.com/95632/ 隨著大型網站的各種高並發訪問、海量數據處理等場景越來越多,如何實現網站的高可用、易伸縮、可擴展、安全等目標就顯得越來越重要。 為了解決
淺談mysql的兩階段提交協議
前兩天和百度的一個同學聊MySQL兩階段提交,當時自信滿滿的說了一堆,後來發現還是有些問題的理解還是比較模糊,可能是因為時間太久了,忘記了吧。這裡再補一下:) 5.3.1事務提交流程 MySQL的事務提交邏輯主要在函式ha_commit_trans中完成。事務的提交涉及到binlog及具體的儲存的引擎
二階段提交與三階段提交
前面幾篇部落格中提到了CAP原理,以及CAP的幾種組合,比如符合AP的有Gossip協議;符合CP的有Paxos協議;符合CA的有二階段提交(2PC). 這篇文章就來介紹下二階段提交和有所改進的三階段提交。 二階段提交(2PC) 為了使分散式系統架構下所有節點在進行事務提交時保持
MySQL兩階段提交
一般分為協調器C和若干事務執行者Si兩種角色: 當執行某一事務T的所有站點Si都通知C事務執行完成,C即啟動二階段提交協議。 1.首先C向所有Si發<prepare>訊息(C先將<prepare>訊息寫到本機日誌),Si收到
兩階段提交協議和三階段提交協議
JEE的XA協議就是根據兩階段提交來保證事務的完整性,並實現分散式服務化的強一致性。 兩階段協議提交的流程 ①準備階段:協調者向參與者發起指令,參與者評估自己的狀態。如果參與者評估指令可以完成,則會寫redo或者undo的日誌,然後鎖定資源,執行操作,但不提交 ②提交階段:如果
Atitit ACID解決方案2PC(兩階段提交) 跨越多個數據庫例項的ACID保證
個人說明 提供相關技術諮詢,以及解決方案編制,編制相關標準化規範草案,軟體培訓與技術點體系建設,知識圖譜體系化,提供軟體行業顧問佈道,12年的軟體行業背景,歡迎有志於軟體行業的同仁們互相交流,群名稱:標準化規範工作組草案,群 號:518818717, 聯絡方式: [
XA,兩階段提交和X/Open協議
XA和兩階段提交 分散式事務處理是指一個事務可能涉及多個數據庫操作,分散式事務處理的關鍵是必須有一種方法可以知道事務在任何地方所做的所有動作,提交或回滾事務的決定必須產生統一的結果(全部提交或全部回滾)。 X/Open組織(即現在的Ope
PostgreSQL學習(七)—— Transaction兩階段提交(中)
Transaction事務** 兩階段提交 **在PostgreSQL中是可以支援兩階段提交協議的;在分散式系統當中,事務往往包含了多臺資料庫上的操作,單臺數據庫可以很好的保證原子性,而多臺資料庫之間的
深入理解兩階段提交協議
ESS 未收到 ces href ati sof https 記錄 src 兩階段提交協議(two phase commit protocol,以下簡稱2PC協議)作為最簡單原子提交協議,在很多需要使用分布式事務的場景中會經常用到。下面將嘗試深入而簡單的闡釋2PC協議,並給
聊一聊 MySQL 中的資料編輯過程中涉及的兩階段提交
MySQL 資料庫中的兩階段提交,不知道您知道不?這篇文章就簡單的聊一聊 MySQL 資料庫中的兩階段提交,兩階段提交發生在資料變更期間(更新、刪除、新增等),兩階段提交過程中涉及到了 MySQL 資料庫中的兩個日誌系統:redo 日誌和 binlog 檔案。 redo 日誌前面已經介紹過了,就不再介紹了,簡