
資料結構:查詢
PS:都是自己認為目前需要掌握熟悉瞭解的,並不是所有,日後需要的時候再一一補充
查詢表:由同一型別的資料元素(或記錄)構成的集合。
關鍵字:資料元素中某個資料項的值。
若此關鍵字可以唯一標識一個記錄,則稱此關鍵字為主關鍵字。
如果此關鍵字可以識別多個數據元素(或記錄),則稱為次關鍵字。
查詢就是根據給定的某個值,在查詢表中確定一個其關鍵字等於給定值的資料元素(或記錄)。
查詢表分為兩大種:靜態查詢表和動態查詢表。
1. 靜態查詢表:只作查詢操作的查詢表。
(1) 查詢某個“特定的”資料元素是否在查詢表中。
(2)檢索某個“特定的”資料元素的各種屬性。
2. 動態查詢表:在查詢過程中,同時插入不存在的資料元素或者刪除資料元素。
(1) 查詢時插入元素。
(2) 查詢所刪除元素。
順序表的查詢
1 普通演算法
2 優化之後int Ordinary_Find(int ary[], int target) { for (int i = 1; i < =ary.Length; i++) { if (ary[i] == target) { //找到了就返回找到的位置 return i; } } //沒找到就返回-1,表示沒找到 return -1; }
int Find(int ary[] , int target)
{
int i;
a[0]=target;
i=ary.length;
while(a[i]!=target)
{
i--;
}
return i;
}1. 折半查詢
2. 插值查詢int BiSearch(int data[], int key, int n) { int mid,low,high;//中間位置 low=1; high=n; if (low > high) { return -1; } while(low <= high) { mid = (low + high) / 2; if (key == data[mid] ) { return mid; } else if (data[mid] < key) { low = mid + 1; } else if (data[mid] > key) { high = mid - 1; } } return -1; }
我們在一本英漢字典中尋找單詞“worst”,我們決不會仿照對半查詢(或Fibonacci查詢)那樣,先查詢字典中間的元素,然後查詢字典四分之三處的元素等等. 事實上,我們是在所期望的地址(在字典的很靠後的地方)附近開始查詢的,我們稱這樣的查詢為插值查詢。
資料不僅是已被排好序的,而且呈現均勻分佈特徵。
int Insert_search(int *a, int key, int n)
{
int pos, low, high;
low = 0,high = n - 1;
while(low <= high){
pos = ((key - a[low]) * (high - low )) / (a[high] - a[low]) + low;
if(a[pos] < key){
low = pos + 1;
} else if(a[pos] == key){
return pos;
} else{
high = pos - 1;
}
}
return -1;
}3. 斐波那契查詢
ps 不會,沒深入瞭解
線性索引查詢
有時候資料集可能增長非常快,例如,某些微博網站或大型論壇的帖子和回覆總數每天都是成百萬上千萬條,或者一些伺服器的日誌資訊記錄也可能是海量資料,要保證記錄全部是按照當中的某個關鍵字有序,其時間代價是非常高昂的,所以這種資料都是按先後順序儲存的。
對於這樣的查詢表,我們如何能夠快速 查詢到需要的資料呢?辦法就是----索引
索引是 了加快查詢速度而設計的一種資料結構。
索引就是把一個關鍵字與它對應的記錄相關聯的過程,一個索引由若干個索引項構成,每個索引項至少應包含關鍵字和其對應的記錄在儲存器中的位置等資訊。
索引按照結構可以分為線性索引、樹形索引和多級索引。我們這裡就只介紹線性索引技術。所謂線性索引就是將索引項集合組織為線性結構,也稱為索引表。我們重點介紹三個線性索引:稠密索引、分塊索引、和倒排索引。
稠密索引
它是指線性索引中,將資料集中的每個記錄對應一個索引項。
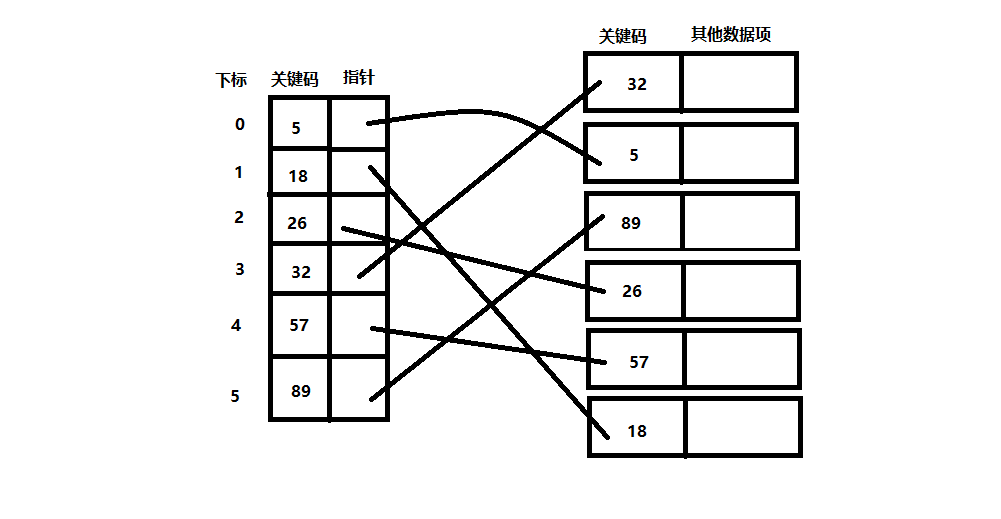
對於稠密索引這個索引表來說,索引一定是按照關鍵碼有序排列的。
索引項有序也就意味著,我們要查詢關鍵字時,可以用到折半、插值、斐波那契等有序查詢演算法,大大提高效率。
比如查詢上表中的18。如果不用索引表,需要6次。而用左側的索引表,折半兩次就可以找到18對應的指標。
這顯然是稠密索引優點,但是如果資料集非常大,比如上億,那也就意味著索引也得同樣的資料集長度規模,對於記憶體有限的計算機來說,可能就需要反覆去訪問磁碟,查詢效能反而大大下降了。
分塊索引
稠密索引因為索引項與資料集的記錄個數相同,所以空間代價很大。為了減少索引的個數,我們可以對資料集進行分塊,使其分塊有序,然後再對每一塊建立一個索引項,從而減少索引項的個數。
分塊有序,是把資料集的記錄分成若干塊,並且這些塊需要滿足兩個條件:
l 塊內無序,即每一塊內的記錄不要求有序。當然,你如果能夠讓塊內有序對查詢來說更理想,不過這就要付出大量時間和空間代價,因此通常我們不要求塊內有序
l 塊間有序,例如要求第二塊所有記錄的關鍵字均要大於第一塊中所有記錄的關鍵字,第三塊的所有記錄的關鍵字均要大於第二塊的所有記錄關鍵字….因為只有塊間有序,才有可能在查詢時帶來效率。
對於分塊有序的資料集,將每塊對應一個索引項,這種索引方法叫做分快索引。
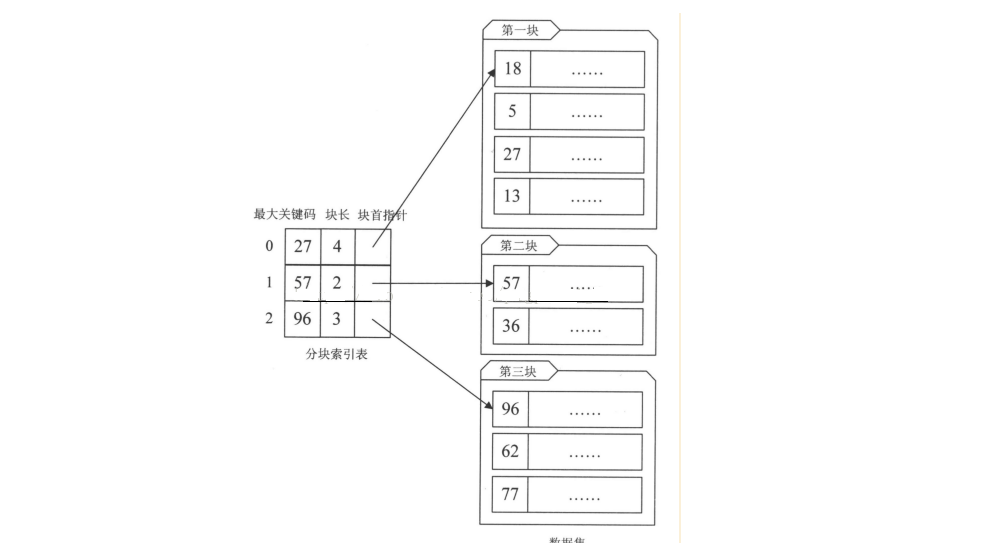
n 最大關鍵碼:它儲存每一塊中的最大關鍵字,這樣的好處就是可以使得在它之後的下一塊中最小關鍵字也能比這一塊最大的關鍵字要大
n 儲存了塊中的記錄個數,以便於迴圈時使用
n 用於指向塊首資料元素的指標,便於開始對這一塊中的記錄進行遍歷。
分塊索引是分兩步進行:
1. 在分塊索引表中查詢要查關鍵字所在的塊。由於分塊索引表是塊間有序的,因此很容易利用折半、插值等演算法得到結果。
2. 根據塊首指標找到相應的塊,並在塊中順序查詢關鍵碼。因為塊中可以是無序的,因此只能順序查獲。