
MySQL讀書學習筆記(四)——查詢效能優化
4.1 為什麼慢
瞭解查詢的生命週期,清楚查詢的時間消耗情況對於優化查詢有很大意義。
4.2 慢查詢基礎:優化資料訪問
查詢效能低下最基本的原因是訪問資料太多。某些查詢可能不可避免地需要篩選大量資料,但這並不常見。大部分效能低下的查詢都可以通過減少訪問的資料量的方式進行優化。對於低效的查詢,可以用下面的兩個步驟來分析:
1.確認應用程式是否檢索大量超過需要的資料。
2.確認MySQL伺服器層是否在分析大量超過需要的資料行。
4.2.1 請求了不必要的資料
有些查詢會請求超過實際需要的資料,然後這些多餘的資料會被應用程式丟棄。這會給MySQL伺服器帶來額外的負擔,並增加網路開銷;另外也會消耗應用伺服器的CPU和記憶體資源。如:
查詢不需要的記錄。
多表關聯時返回全部列。
總是取出全部列。
重複查詢相同資料。
4.2.2 掃描額外記錄
在確定只返回需要的資料以後,接下來應該看看查詢的為了返回結果是否掃描了過多的資料。對於MySQL,最簡單地衡量查詢開銷的三個指標如下:響應時間;返回行數;掃描行數。
4.3 重構查詢方式
在優化有問題的查詢時,目標應該是找到一個更優的方法獲得實際需要的結果,而不一定總是需要MySQL獲取一模一樣的結果集。有時候,可以將查詢轉換一種寫法讓其返回一樣的結果,但是效能更好。但也可以通過修改應用程式碼,用另一種方式完成查詢。
4.3.1 一個複雜查詢還是多個簡單查詢
在其他條件都相同的時候,使用盡可能少的查詢,但是有時候分解是很有必要。
4.3.2 切分查詢
有時候對於一個大查詢需要分治,將大查詢切分成小查詢,每個查詢功能完全一樣,只完成一小部分,每次只返回一小部分查詢結果。
4.3.3 分解關聯查詢
很多高效能的應用都會對關聯查詢進行分解。簡單地,可以對每一個表進行一次單表查詢,然後將結果在應用程式中進行關聯。
4.4 查詢執行的基礎
查詢執行的路徑:
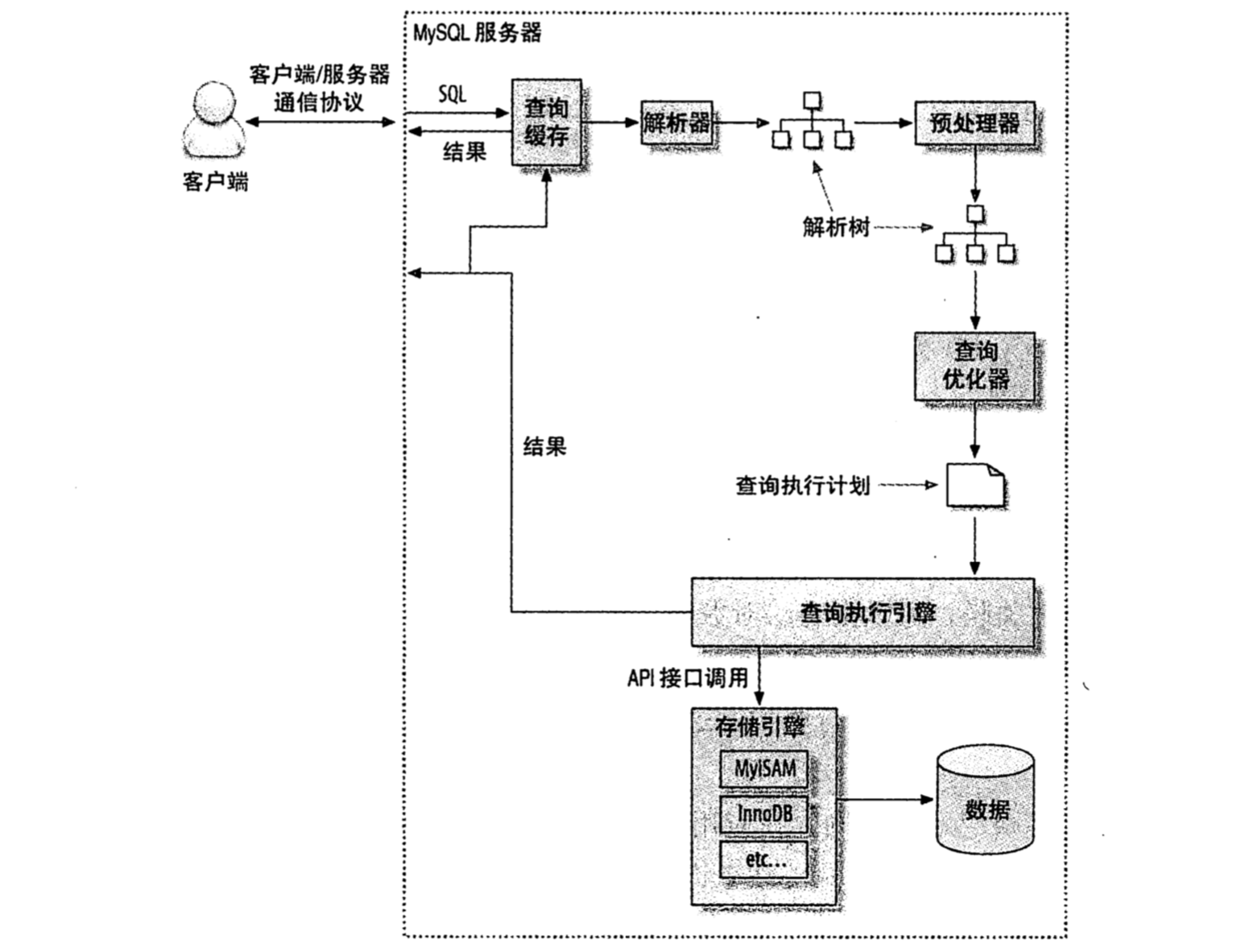
4.4.1 MySQL客戶端/伺服器通訊協議
半雙工,在任意一個時刻,要麼是由伺服器向客戶端傳送資料,要麼是由客戶端像伺服器傳送資料,這兩個動作不能同時發生。所以,我們也不能將一個訊息切成小塊獨立傳送。
4.4.2 查詢快取
在解析一個查詢語句之前,如果查詢快取是開啟的,MySQL會優先檢查是否命中快取中的資料。檢查是通過一個對大小寫敏感的雜湊查詢實現的。查詢與快取中即使有一個位元組不同,也不能匹配。
4.4.3 查詢優化
MySQL優化查詢器是一個非常複雜的部件,他使用了很多優化策略來生成一個最優的執行計劃。可分為兩種,一種是靜態優化,一種是動態優化。靜態優化可以直接對解析樹進行分析,並完成優化。靜態優化不依賴於特別的數值。靜態優化在第一次完成後就一直有效,即使使用不同的引數重新進行查詢也不會發生變化。可以認為是一種“編譯時優化”。相反,,動態優化則與查詢的上下文有關,也可能和其他很多因素有關。這需要在每次查詢的時候都進行評估,可以認為這是“執行時優化”。
4.4.4 查詢執行引擎
在解析和優化階段,MySQL將生成查詢對應的執行計劃,MySQL的查詢執行引擎將根據這個計劃來完成整個查詢。這裡的執行計劃是一個數據結構,而不是和很多其他的關係型資料庫那樣會生成對應的位元組碼。
4.4.5 返回結果給客戶端
查詢執行的最後一個階段是將查詢結果返回給客戶端。 即使查詢不需要返回結果集給客戶端,MySQL仍會返回這個查詢的一些資訊。
4.5 查詢優化器的侷限性
MySQL的萬能“巢狀迴圈”並不是對每種查詢都是最優的。不過MySQL的查詢優化器只對少部分查詢不適用,而往往可以通過改寫查詢讓MySQL高效地完成工作。
4.5.1 關聯子查詢
兩點:一是不需要聽取那些關於子查詢的“絕對真理”,二是應該用測試來驗證對子查詢的執行計劃和響應時間的假設。
4.5.2 UNION的限制
如果希望UNION的各個子句能夠根據limit只取部分結果集,或者希望能夠先排好序再合併結果集的話,就需要在UNION的各個子句中分別使用這些子句。
4.5.3 索引合併優化
當where子句中包含多個複雜條件的時候,MySQL能夠訪問單個表的多個索引以合併交叉過濾的方式來定位需要查詢的行。
4.5.4 等值傳遞
某些時候,等值傳遞會帶來意想不到的額外消耗。
4.5.5 並行執行
MySQL無法利用多核特性執行並行查詢。
4.5.6 雜湊關聯
MySQL並不支援雜湊關係,所有關聯都是巢狀迴圈關聯。不過,可以通過建立一個雜湊索引來間接實現雜湊關聯。如果使用的是Memory引擎,索引都是雜湊索引,關聯也類似雜湊關聯。另外,MariaDB已經實現了真正的雜湊關聯。
4.5.7 鬆散索引掃描
MySQL並不支援,也就無法按照不連續的方式掃描一個索引。通常,MySQL索引掃描需要先定義一個起點和終點,即使需要的資料只是這段索引中很少的幾個,MySQL仍需掃描這段索引中的每一個條目。
4.6 查詢優化器的提示(hint)
如果對優化器的執行計劃不滿意,可以用優化器提供的幾個提示來控制最終的執行計劃。
4.7 優化特定型別的查詢
4.7.1 優化count
使用count(*),使用近似值。
4.7.2 優化關聯查詢
確保on和using子句的列上有索引。
確保任何group by和order by的表示式只涉及到表中的一個列。
當升級MySQL時要注意,關聯語法、運算子優先順序等其他可能發生變化的地方。
4.7.3 優化子查詢
儘可能使用關聯查詢代替。
4.7.4 優化group by和distinct
使用索引。
4.7.5 優化limit分頁
儘可能使用索引覆蓋掃描,而不是查詢所有的列。
4.7.6 優化SQL_CALC_FOUND_ROWS
將具體的頁數換成下一頁按鈕;先獲取並快取較多的資料。
4.7.7 優化UNION
經常需要手工地將where,limit,order by等子句下推到UNION的各個子查詢中,以便優化器可以利用這些條件進行優化。