
Java 8——Stream API
整理自http://www.cnblogs.com/aoeiuv/p/5911692.html
https://www.ibm.com/developerworks/cn/java/j-lo-java8streamapi/index.html
三.Stream API
兩句話理解Stream:
1.Stream是元素的集合,這點讓Stream看起來用些類似Iterator;
2.可以支援順序和並行的對原Stream進行匯聚的操作;
大家可以把Stream當成一個裝飾後的Iterator。原始版本的Iterator,使用者只能逐個遍歷元素並對其執行某些操作;包裝後的Stream,使用者只要給出需要對其包含的元素執行什麼操作,比如“過濾掉長度大於10的字串”、“獲取每個字串的首字母”等,具體這些操作如何應用到每個元素上,就給Stream就好了!原先是人告訴計算機一步一步怎麼做,現在是告訴計算機做什麼,計算機自己決定怎麼做。當然這個“怎麼做”還是比較弱的。
例子:
//Lists是Guava中的一個工具類
List<Integer> nums = Lists.newArrayList(1,null,3,4,null,6);
nums.stream().filter(num -> num != null).count();
上面這段程式碼是獲取一個List中,元素不為null的個數。這段程式碼雖然很簡短,但是卻是一個很好的入門級別的例子來體現如何使用Stream,正所謂“麻雀雖小五臟俱全”。我們現在開始深入解刨這個例子,完成以後你可能可以基本掌握Stream的用法!

圖片就是對於Stream例子的一個解析,可以很清楚的看見:原本一條語句被三種顏色的框分割成了三個部分。紅色框中的語句是一個Stream的生命開始的地方,負責建立一個Stream例項;綠色框中的語句是賦予Stream靈魂的地方,把一個Stream轉換成另外一個Stream,紅框的語句生成的是一個包含所有nums變數的Stream,進過綠框的filter方法以後,重新生成了一個過濾掉原nums列表所有null以後的Stream;藍色框中的語句是豐收的地方,把Stream的裡面包含的內容按照某種演算法來匯聚成一個值,例子中是獲取Stream中包含的元素個數。如果這樣解析以後,還不理解,那就只能動用“核武器”–圖形化,一圖抵千言!

使用Stream的基本步驟:
1.建立Stream;
2.轉換Stream,每次轉換原有Stream物件不改變,返回一個新的Stream物件(**可以有多次轉換**);
3.對Stream進行聚合(Reduce)操作,獲取想要的結果;
3.1怎麼得到Stream
最常用的建立Stream有兩種途徑:
1.通過Stream介面的靜態工廠方法(注意:Java8裡介面可以帶靜態方法);
2.通過Collection介面的預設方法(預設方法:Default method,也是Java8中的一個新特性,就是介面中的一個帶有實現的方法)–stream(),把一個Collection物件轉換成Stream
3.1.1 使用Stream靜態方法來建立Stream
1. of方法:有兩個overload方法,一個接受變長引數,一個介面單一值
Stream<Integer> integerStream = Stream.of(1, 2, 3, 5);
Stream<String> stringStream = Stream.of("taobao");
2. generator方法:生成一個無限長度的Stream,其元素的生成是通過給定的Supplier(這個介面可以看成一個物件的工廠,每次呼叫返回一個給定型別的物件)
Stream.generate(new Supplier<Double>() {
@Override
public Double get() {
return Math.random();
}
});
Stream.generate(() -> Math.random());
Stream.generate(Math::random);
三條語句的作用都是一樣的,只是使用了lambda表示式和方法引用的語法來簡化程式碼。每條語句其實都是生成一個無限長度的Stream,其中值是隨機的。這個無限長度Stream是懶載入,一般這種無限長度的Stream都會配合Stream的limit()方法來用。
3. iterate方法:也是生成無限長度的Stream,和generator不同的是,其元素的生成是重複對給定的種子值(seed)呼叫使用者指定函式來生成的。其中包含的元素可以認為是:seed,f(seed),f(f(seed))無限迴圈
Stream.iterate(1, item -> item + 1).limit(10).forEach(System.out::println);
這段程式碼就是先獲取一個無限長度的正整數集合的Stream,然後取出前10個列印。千萬記住使用limit方法,不然會無限列印下去。
3.1.2通過Collection子類獲取Stream
Collection介面有一個stream方法,所以其所有子類都都可以獲取對應的Stream物件。
public interface Collection<E> extends Iterable<E> {
//其他方法省略
default Stream<E> stream() {
return StreamSupport.stream(spliterator(), false);
}
}
3.2轉換Stream
轉換Stream其實就是把一個Stream通過某些行為轉換成一個新的Stream。Stream介面中定義了幾個常用的轉換方法,下面我們挑選幾個常用的轉換方法來解釋。
1. distinct: 對於Stream中包含的元素進行去重操作(去重邏輯依賴元素的equals方法),新生成的Stream中沒有重複的元素;

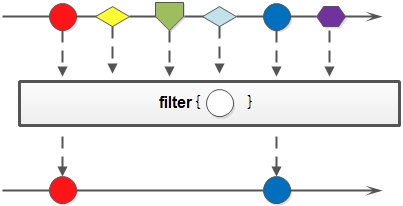
2. filter: 對於Stream中包含的元素使用給定的過濾函式進行過濾操作,新生成的Stream只包含符合條件的元素;
3. map: 對於Stream中包含的元素使用給定的轉換函式進行轉換操作,新生成的Stream只包含轉換生成的元素。這個方法有三個對於原始型別的變種方法,分別是:mapToInt,mapToLong和mapToDouble。這三個方法也比較好理解,比如mapToInt就是把原始Stream轉換成一個新的Stream,這個新生成的Stream中的元素都是int型別。之所以會有這樣三個變種方法,可以免除自動裝箱/拆箱的額外消耗;
4. flatMap:和map類似,不同的是其每個元素轉換得到的是Stream物件,會把子Stream中的元素壓縮到父集合中;
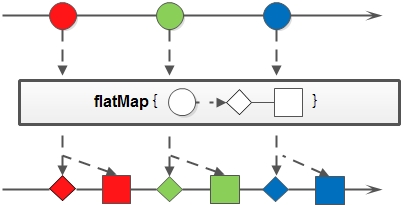
flatMap給一段程式碼理解:
Stream<List<Integer>> inputStream = Stream.of( Arrays.asList(1), Arrays.asList(2, 3), Arrays.asList(4, 5, 6) ); Stream<Integer> outputStream = inputStream. flatMap((childList) -> childList.stream());
flatMap 把 input Stream 中的層級結構扁平化,就是將最底層元素抽出來放到一起,最終 output 的新 Stream 裡面已經沒有 List 了,都是直接的數字。
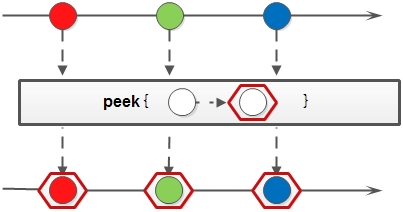
5. peek: 生成一個包含原Stream的所有元素的新Stream,同時會提供一個消費函式(Consumer例項),新Stream每個元素被消費的時候都會執行給定的消費函式;
6. limit: 對一個Stream進行截斷操作,獲取其前N個元素,如果原Stream中包含的元素個數小於N,那就獲取其所有的元素;
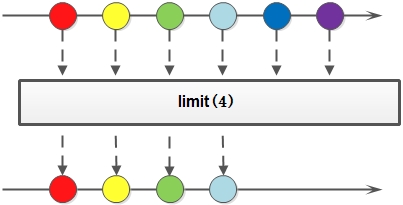
7. skip: 返回一個丟棄原Stream的前N個元素後剩下元素組成的新Stream,如果原Stream中包含的元素個數小於N,那麼返回空Stream;
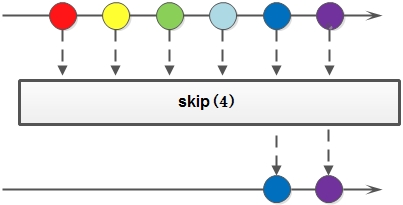
整體呼叫例子:
List<Integer> nums = Lists.newArrayList(1,1,null,2,3,4,null,5,6,7,8,9,10);
System.out.println(“sum is:”+nums.stream().filter(num -> num != null).distinct().mapToInt(num -> num * 2).peek(System.out::println).skip(2).limit(4).sum());
這段程式碼演示了上面介紹的所有轉換方法(除了flatMap),簡單解釋一下這段程式碼的含義:給定一個Integer型別的List,獲取其對應的Stream物件,然後進行過濾掉null,再去重,再每個元素乘以2,再每個元素被消費的時候列印自身,在跳過前兩個元素,最後去前四個元素進行加和運算(解釋一大堆,很像廢話,因為基本看了方法名就知道要做什麼了。這個就是宣告式程式設計的一大好處!)。大家可以參考上面對於每個方法的解釋,看看最終的輸出是什麼。
2
4
6
8
10
12
sum is:36
可能會有這樣的疑問:在對於一個Stream進行多次轉換操作,每次都對Stream的每個元素進行轉換,而且是執行多次,這樣時間複雜度就是一個for迴圈裡把所有操作都做掉的N(轉換的次數)倍啊。其實不是這樣的,轉換操作都是lazy的,多個轉換操作只會在匯聚操作(見下節)的時候融合起來,一次迴圈完成。我們可以這樣簡單的理解,Stream裡有個操作函式的集合,每次轉換操作就是把轉換函式放入這個集合中,在匯聚操作的時候迴圈Stream對應的集合,然後對每個元素執行所有的函式。
3.3匯聚(Reduce)Stream
匯聚操作(也稱為摺疊)接受一個元素序列為輸入,反覆使用某個合併操作,把序列中的元素合併成一個彙總的結果。比如查詢一個數字列表的總和或者最大值,或者把這些數字累積成一個List物件。Stream介面有一些通用的匯聚操作,比如reduce()和collect();也有一些特定用途的匯聚操作,比如sum(),max()和count()。注意:sum方法不是所有的Stream物件都有的,只有IntStream、LongStream和DoubleStream是例項才有。
下面會分兩部分來介紹匯聚操作:
可變匯聚:把輸入的元素們累積到一個可變的容器中,比如Collection或者StringBuilder;
其他匯聚:除去可變匯聚剩下的,一般都不是通過反覆修改某個可變物件,而是通過把前一次的匯聚結果當成下一次的入參,反覆如此。比如reduce,count,allMatch;
3.3.1可變匯聚
可變匯聚對應的只有一個方法:collect,正如其名字顯示的,它可以把Stream中的要有元素收集到一個結果容器中(比如Collection)。先看一下最通用的collect方法的定義(還有其他override方法):
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
先來看看這三個引數的含義:Supplier supplier是一個工廠函式,用來生成一個新的容器;BiConsumer accumulator也是一個函式,用來把Stream中的元素新增到結果容器中;BiConsumer combiner還是一個函式,用來把中間狀態的多個結果容器合併成為一個(併發的時候會用到)。看暈了?來段程式碼!
List<Integer> nums = Lists.newArrayList(1,1,null,2,3,4,null,5,6,7,8,9,10);
List<Integer> numsWithoutNull = nums.stream().filter(num -> num != null).
collect(() -> new ArrayList<Integer>(),
(list, item) -> list.add(item),
(list1, list2) -> list1.addAll(list2));
上面這段程式碼就是對一個元素是Integer型別的List,先過濾掉全部的null,然後把剩下的元素收集到一個新的List中。進一步看一下collect方法的三個引數,都是lambda形式的函式。
第一個函式生成一個新的ArrayList例項;
第二個函式接受兩個引數,第一個是前面生成的ArrayList物件,二個是stream中包含的元素,函式體就是把stream中的元素加入ArrayList物件中。第二個函式被反覆呼叫直到原stream的元素被消費完畢;
第三個函式也是接受兩個引數,這兩個都是ArrayList型別的,函式體就是把第二個ArrayList全部加入到第一個中;
但是上面的collect方法呼叫也有點太複雜了,沒關係!我們來看一下collect方法另外一個override的版本,其依賴[Collector](http://docs.oracle.com/javase/8/docs/api/java/util/stream/Collector.html)。
<R, A> R collect(Collector<? super T, A, R> collector);
這樣清爽多了!Java8還給我們提供了Collector的工具類–[Collectors](http://docs.oracle.com/javase/8/docs/api/java/util/stream/Collectors.html),其中已經定義了一些靜態工廠方法,比如:Collectors.toCollection()收集到Collection中,
Collectors.toList()收集到List中和Collectors.toSet()收集到Set中。這樣的靜態方法還有很多,這裡就不一一介紹了,大家可以直接去看JavaDoc。下面看看使用Collectors對於程式碼的簡化:
List<Integer> numsWithoutNull = nums.stream().filter(num -> num != null).
collect(Collectors.toList());
3.3.2其他匯聚
– reduce方法:reduce方法非常的通用,後面介紹的count,sum等都可以使用其實現。reduce方法有三個override的方法,本文介紹兩個最常用的。先來看reduce方法的第一種形式,其方法定義如下:
Optional<T> reduce(BinaryOperator<T> accumulator);
接受一個BinaryOperator型別的引數,在使用的時候我們可以用lambda表示式來。
List<Integer> ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println("ints sum is:" + ints.stream().reduce((sum, item) -> sum + item).get());
可以看到reduce方法接受一個函式,這個函式有兩個引數,第一個引數是上次函式執行的返回值(也稱為中間結果),第二個引數是stream中的元素,這個函式把這兩個值相加,得到的和會被賦值給下次執行這個函式的第一個引數。要注意的是:**第一次執行的時候第一個引數的值是Stream的第一個元素,第二個引數是Stream的第二個元素**。這個方法返回值型別是Optional,這是Java8防止出現NPE的一種可行方法,後面的文章會詳細介紹,這裡就簡單的認為是一個容器,其中可能會包含0個或者1個物件。
這個過程視覺化的結果如圖:
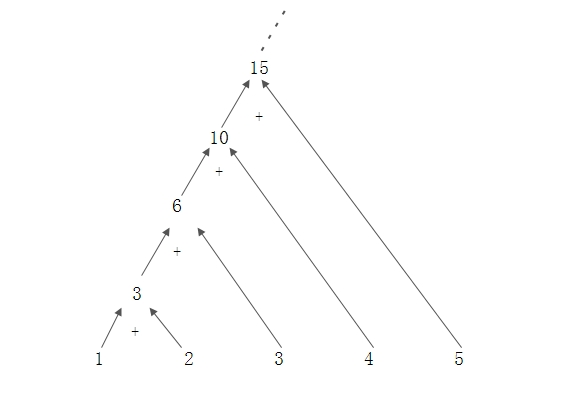
reduce方法還有一個很常用的變種:
T reduce(T identity, BinaryOperator<T> accumulator);
這個定義上上面已經介紹過的基本一致,不同的是:它允許使用者提供一個迴圈計算的初始值,如果Stream為空,就直接返回該值。而且這個方法不會返回Optional,因為其不會出現null值。下面直接給出例子,就不再做說明了。
List<Integer> ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println("ints sum is:" + ints.stream().reduce(0, (sum, item) -> sum + item));
– count方法:獲取Stream中元素的個數。比較簡單,這裡就直接給出例子,不做解釋了。
List<Integer> ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println("ints sum is:" + ints.stream().count());
– 搜尋相關
– allMatch:是不是Stream中的所有元素都滿足給定的匹配條件
– anyMatch:Stream中是否存在任何一個元素滿足匹配條件
– findFirst: 返回Stream中的第一個元素,如果Stream為空,返回空Optional
– noneMatch:是不是Stream中的所有元素都不滿足給定的匹配條件
– max和min:使用給定的比較器(Operator),返回Stream中的最大|最小值
下面給出allMatch和max的例子,剩下的方法讀者當成練習。
檢視原始碼列印幫助
List<Integer> ints = Lists.newArrayList(1,2,3,4,5,6,7,8,9,10);
System.out.println(ints.stream().allMatch(item -> item < 100));
ints.stream().max((o1, o2) -> o1.compareTo(o2)).ifPresent(System.out::println);
補充
為什麼需要 Stream
Stream 作為 Java 8 的一大亮點,它與 java.io 包裡的 InputStream 和 OutputStream 是完全不同的概念。它也不同於 StAX 對 XML 解析的 Stream,也不是 Amazon Kinesis 對大資料實時處理的 Stream。Java 8 中的 Stream 是對集合(Collection)物件功能的增強,它專注於對集合物件進行各種非常便利、高效的聚合操作(aggregate operation),或者大批量資料操作 (bulk data operation)。Stream API 藉助於同樣新出現的 Lambda 表示式,極大的提高程式設計效率和程式可讀性。同時它提供序列和並行兩種模式進行匯聚操作,併發模式能夠充分利用多核處理器的優勢,使用 fork/join 並行方式來拆分任務和加速處理過程。通常編寫並行程式碼很難而且容易出錯, 但使用 Stream API 無需編寫一行多執行緒的程式碼,就可以很方便地寫出高效能的併發程式。所以說,Java 8 中首次出現的 java.util.stream 是一個函式式語言+多核時代綜合影響的產物。
什麼是聚合操作
在傳統的 J2EE 應用中,Java 程式碼經常不得不依賴於關係型資料庫的聚合操作來完成諸如:
- 客戶每月平均消費金額
- 最昂貴的在售商品
- 本週完成的有效訂單(排除了無效的)
- 取十個資料樣本作為首頁推薦
這類的操作。
但在當今這個資料大爆炸的時代,在資料來源多樣化、資料海量化的今天,很多時候不得不脫離 RDBMS,或者以底層返回的資料為基礎進行更上層的資料統計。而 Java 的集合 API 中,僅僅有極少量的輔助型方法,更多的時候是程式設計師需要用 Iterator 來遍歷集合,完成相關的聚合應用邏輯。這是一種遠不夠高效、笨拙的方法。在 Java 7 中,如果要發現 type 為 grocery 的所有交易,然後返回以交易值降序排序好的交易 ID 集合,我們需要這樣寫:
清單 1. Java 7 的排序、取值實現
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
List<Transaction>
groceryTransactions = new Arraylist<>();
for(Transaction
t: transactions){
if(t.getType()
== Transaction.GROCERY){
groceryTransactions.add(t);
}
}
Collections.sort(groceryTransactions,
new Comparator(){
public
int compare(Transaction t1, Transaction t2){
return
t2.getValue().compareTo(t1.getValue());
}
|