
BCache原始碼淺析之三資料讀寫流程
4. 資料讀寫流程與B+Tree
cached_dev_make_request:
a. 如果device沒有對應的快取裝置,則直接將向主裝置提交bio,並返回.
b.如果有cache device 根據要傳輸的bio, 用search_alloc建立struct search s;
c. 呼叫check_should_bypass check是否應該bypass這個bio,
d.根據讀寫分別呼叫cached_dev_read或cached_dev_write
4.1 bypass檢查check_should_bypass
(1) 若bio為discard 或gc 數量大於CUTOFF_CACHE_ADD,則bypass為true
(2) 主裝置裝置禁用cache, 則bypass為true
(3) 傳輸的sector 為按block對齊,則bypass為true
(4) cache裝置處於擁塞狀態(bch_get_congested),則bypass為true
(5) 根據歷史判斷是否為sequence io, 且sectors >= dc->sequential_cutoff(default為4MB)則bypass為true
4.2資料讀取流程cached_dev_read
staticvoid cached_dev_read(struct cached_dev *dc, struct search *s) {
struct closure *cl = &s->cl;
closure_call(&s->iop.cl,cache_lookup, NULL, cl);
continue_at(cl,cached_dev_read_done_bh, NULL);
}
cache_lookup呼叫
ret = bch_btree_map_keys(&s->op,s->iop.c,
&KEY(s->iop.inode,bio->bi_iter.bi_sector, 0),
cache_lookup_fn, MAP_END_KEY);
來遍歷b+tree葉子節點,來查詢bkey: KEY(s->iop.inode,bio->bi_iter.bi_sector, 0); 當遍歷到頁節點時btree_map_keys_fn 函式會被呼叫, 這裡為cache_lookup_fn.
cache_loopup_fn:
a. 若帶搜尋的key比當前key小,則返回MAP_CONTINUE讓上層搜尋下一個key.
b. 若key不在b+tree或key中的資料只有部分在b+tree則呼叫s->d->cache_miss(b, s, bio, sectors);
c. 如果資料已在快取中(bkey在b+tree中,且key中的資料範圍也完全在快取中)了, 則直接從快取disk讀取, 命中後需將bucket的prio重新設為:PTR_BUCKET(b->c, k, ptr)->prio = INITIAL_PRIO(32768U)
caceh_miss== cached_dev_cache_miss
a. 當miss函式重入(s->cache_miss)或read bypass時, 直接從主裝置讀取
b. 當讀取非元資料且預讀機制未禁止時,計算能預讀的sector數
c. s->iop.replace_key= KEY(s->iop.inode, //計算要向b+tree新增或替換的key
bio->bi_iter.bi_sector + s->insert_bio_sectors,
s->insert_bio_sectors);
bch_btree_insert_check_key(b,&s->op, &s->iop.replace_key)//向b+tree提交key
d.從主裝置讀取資料,並將bio記錄到iop.bio中以便上層cached_dev_read_done_bh 將資料加到快取裝置: s->cache_miss = miss;
s->iop.bio = cache_bio;
cached_dev_read_done_bh:
a.cached_dev_read_done:
當s->iop.bio不為0時, 表明有新的資料要新增到管理快取的b+tree中, 所以首先bio_copy_data(s->cache_miss,s->iop.bio) 將資料拷貝到cache_missbio中,然後呼叫bch_data_insert將資料更新到cache裝置中
b. cached_dev_bio_complete:釋放struct search
bch_data_insert: {
bch_keylist_init(&op->insert_keys);//初始化keylist, keylist是一種雙端佇列結構
bio_get(op->bio);
bch_data_insert_start(cl);
}
bch_data_insert_start:該函式要考慮cache disk儲存區域的overlap,下面是overlap的case:
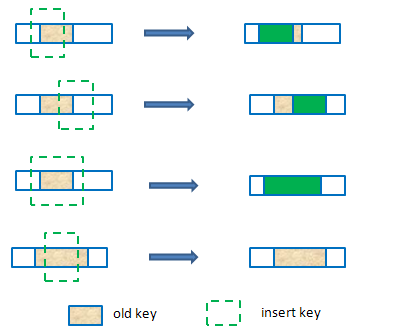
當需要在cache disk中分配新的儲存區域時需要呼叫bch_alloc_sectors, 從bucket中分配空間。 然後向cachedisk發起bio請求bch_submit_bbio(n, op->c, k, 0);。
在新增資料與處理overlap時發現要改變現有b+tree的key結構,那麼呼叫如下程式碼:
k = op->insert_keys.top; bkey_init(k);
SET_KEY_INODE(k,op->inode);
SET_KEY_OFFSET(k,bio->bi_iter.bi_sector);需要重新更新btree
if (op->writeback)
SET_KEY_DIRTY(k,true);
bch_keylist_push(&op->insert_keys);
最後bch_data_insert_start==> bch_data_insert_keys來將op->insert_key更新到b+tree
bch_data_insert_keys首先對插入的case 呼叫bch_journal來增加journal(第8節分析該流程).然後呼叫bch_btree_insert,遍歷要插入了keylist, 對每項做:bch_btree_map_leaf_nodes(&op.op, c, &START_KEY(keys->keys),btree_insert_fn);
btree_insert_fn將呼叫bch_btree_insert_node來操作b+tree.
4.3資料寫入流程cached_dev_write
cached_dev_write:
a. bch_keybuf_check_overlapping檢視是否和已有要writeback的區域有重合,若有,取消當前區域的bypass
b.若bio為REQ_DISCARD,則採用bypass
c. should_writeback做writeback檢測(第7節分析)
d. 下面分三種case處理:
(1) bypass: 則直接s->iop.bio = s->orig_bio(賦值為原disk io)
(2) 開啟writeback, 則需要bch_writeback_add(dc);s->iop.bio = bio; 並不需要將資料立即寫回主裝置,
(3) s->iop.bio = bio_clone_fast(bio,...);closure_bio_submit(bio, cl, s->d); 將資料寫回主裝置
d. closure_call(&s->iop.cl,bch_data_insert, NULL, cl); 向B+tree更新節點
4.4 B+Tree的Insert Node操作
第4.2節中分析到了bch_btree_insert_check_key和bch_btree_insert_node函式,本節通過他們來分析B+Tree的Insert與Replace操作。
bch_btree_insert_check_key 的關鍵程式碼如下:
bch_keylist_add(&insert,check_key);
ret= bch_btree_insert_node(b, op, &insert, NULL, NULL);
由此可見, 最重要的程式碼是bch_btree_insert_node。 下面時該函式的定義:
static intbch_btree_insert_node(struct btree *b, struct btree_op *op,
struct keylist *insert_keys, 要插入的keylist
atomic_t *journal_ref, //journal資訊
struct bkey *replace_key) //要replace的key {
.....
if (bch_keylist_nkeys(insert_keys) >insert_u64s_remaining(b)) {
mutex_unlock(&b->write_lock);
goto split; //如果btree空間不夠,則需要進行拆分操作
}
if(bch_btree_insert_keys(b, op, insert_keys, replace_key)) {
if (!b->level) //對於頁節點不立即更新,僅標記為dirty
bch_btree_leaf_dirty(b, journal_ref);
else
bch_btree_node_write(b, &cl); //對於非頁節點,更新完後直接寫入
}
closure_sync(&cl); //等待btree寫入完成
return 0;
split:
int ret = btree_split(b, op,insert_keys, replace_key);
}
對於頁節點執行:
bch_btree_leaf_dirty:
a.若node未dirty 則延遲呼叫b->work;(INIT_DELAYED_WORK(&b->work, btree_node_write_work);)
b. 已dirty, 如果bset的大小已經很大則bch_btree_node_write(b,null);注意對於多數情況並不會立即更新node以提高效能。 這時就靠前面的bch_journal,來記錄更新的日誌來保證更改不會丟失了。
對於非頁節點執行:
bch_btree_node_write ==> __bch_btree_node_write 清除dirty並呼叫do_btree_node_write,更新node
bch_btree_insert_keys:將分三種情況實際更新b+tree
case 1: 要插入key < btree->key, 則直接呼叫btree_insert_key插入
case 2: 和btree已有key部分重合,計算不重合部分插入
bkey_copy(&temp.key,insert_keys->keys);
bch_cut_back(&b->key,&temp.key);
bch_cut_front(&b->key,insert_keys->keys);
ret |= btree_insert_key(b,&temp.key, replace_key);
case 3: 完全包含與btree->key則不插入
btree_insert_key==》 bch_btree_insert_key 該函式首先遍歷檢察btree中的bset是否已排序;若為排好序排序就呼叫bch_bkey_try_merge。 最後然後呼叫bch_bset_insert(b, m, k)執行b+tree新增或replace操作.
btree_split:
a. 複製一個btree node n1= btree_node_alloc_replacement(b, op);//裡面會從bucket分配
b.計算是否需要分裂split = set_blocks(btree_bset_first(n1),
block_bytes(n1->c)) > (btree_blocks(b)* 4) / 5;
下面時該函式split為true部分的流程及分析:
n2 = bch_btree_node_alloc(b->c, op,b->level);
if (!b->parent) { //如果b已經是根節點,需要分配另一個節點作為新的根節點
n3 =bch_btree_node_alloc(b->c, op, b->level + 1);
}
//將要插入的key先插入到新建立的n1中
bch_btree_insert_keys(n1, op,insert_keys, replace_key);
建立bset的search tree,這裡程式碼未貼出來........
bkey_copy_key(&n2->key,&b->key);
將n2的key 加入到parent_key keylist中以便後面添加里面的key
bch_keylist_add(&parent_keys,&n2->key); bch_btree_node_write(n2,&cl);
接下來:
bch_keylist_add(&parent_keys,&n1->key);
bch_btree_node_write(n1, &cl);
if (n3) { //若r3存在,將他設為新的root
bkey_copy_key(&n3->key,&MAX_KEY);
bch_btree_insert_keys(n3, op,&parent_keys, NULL); //將parent_keys提交的n3中
bch_btree_node_write(n3,&cl);
closure_sync(&cl);
bch_btree_set_root(n3);
} else if (!b->parent) {
closure_sync(&cl);
bch_btree_set_root(n1);//root不需要split的情況,將n1設為root,
} else {
closure_sync(&cl);
make_btree_freeing_key(b,parent_keys.top);
bch_keylist_push(&parent_keys);
//將parent_keys中的key提交到b->parent中
bch_btree_insert_node(b->parent,op, &parent_keys, NULL, NULL);
BUG_ON(!bch_keylist_empty(&parent_keys));
}
btree_node_free(b); //b無論走哪個分支,都不在需要所以釋放, 對於上面的case2,bucket的prio由於重建,所以自動被更新了。