
備戰校招必備的計算機網路知識(一)
這些知識點是我看了不少面經,以及查了不少資料總結的,大概率會考到這些,目前我也正在每天牢記,希望這些能幫助到您,也可以提出寶貴意見!
計算機網路
1. TCP報頭格式
TCP(Transmission Control Protocol)傳輸控制協議是一種面向連線的、可靠的、基於位元組流的傳輸層協議

1、埠號:用來標識同一臺計算機的不同的應用程序。
1)源埠:源埠和IP地址的作用是標識報文的返回地址。
2)目的埠:埠指明接收方計算機上的應用程式介面。
TCP報頭中的源埠號和目的埠號同IP資料報中的源IP與目的IP唯一確定一條TCP連線。
2、序號和確認號:是TCP可靠傳輸的關鍵部分。序號是本報文段傳送的資料組的第一個位元組的序號。在
3.標誌位
ACK 置1時表示確認號(為合法,為0的時候表示資料段不包含確認資訊,確認號被忽略。
RST 置1時重建連線。如果接收到RST位時候,通常發生了某些錯誤。
SYN 置1時用來發起一個連線。
FIN 置1時表示發端完成傳送任務。用來釋放連線,表明傳送方已經沒有資料傳送了。
URG 緊急指標,告訴接收TCP模組緊要指標域指著緊要資料。注:一般不使用。
PSH 置1時請求的資料段在接收方得到後就可直接送到應用程式,而不必等到緩衝區滿時才傳送。注:一般不使用。
4.視窗大小(2位元組):TCP流量控制通過連線的每一端宣告視窗大小進行控制(接收緩衝區大小)
20 00(00100000 00000000)= 8192
由於2位元組能夠表示的最大正整數為65535,故視窗最大值為65535
u16位檢驗和:
檢驗和覆蓋了整個的TCP報文段: TCP首部和TCP資料。這是一個強制性的欄位,一定是由發端計算和儲存,並由收端進行驗證。
u16位緊急指標:
注:一般不使用。
只有當U R G標誌置1時緊急指標才有效。緊急指標是一個正的偏移量,和序號欄位中的值相加表示緊急資料最後一個位元組的序號。
2. UDP報頭格式
UDP有兩個欄位:資料欄位和首部欄位
使用者資料報UDP有兩個欄位:資料欄位和首部欄位。首部欄位很簡單
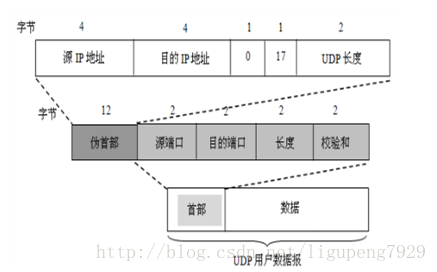
1. 源埠:源埠號。在需要對方回信時選用,不需要時可用全0.
2. 目的埠:目的埠號。這在終點交付報文時必須要使用到。
3. 長度: UDP使用者資料報的長度,其最小值是8(僅有首部)。
UDP使用者資料報首部中檢驗和的計算方法有些特殊。在計算檢驗時,要在UDP使用者資料報之前增加12個字的偽首部。
所謂“偽首部”是因為這種偽首部並不是UDP使用者資料報真正的首部。只在計算檢驗和時,臨時新增在UDP使用者資料報前面,得到一個臨時的UDP使用者資料報。
2. http協議的報文格式
HTTP協議的請求報文
http請求由三部分組成,分別是:請求行、訊息報頭、請求正文* 請求方法主要有GET和POST兩種
GET:在瀏覽器的位址列中輸入網址的方式訪問網頁時,瀏覽器採用GET方法向伺服器獲取資源。
POST:要求被請求伺服器接受附在請求後面的資料,常用於提交表單。
當瀏覽器向伺服器傳送一個請求到Web伺服器,它傳送一個數據塊,或請求資訊,
HTTP請求資訊包括3部分:
請求方法URI協議/版本;
請求頭(Request Header);
請求正文;
HTTP協議的響應報文
和請求報文類似,HTTP響應主要也是3個部分構成:
(1)協議狀態版本程式碼描述
(2)響應頭(Response Header)
(3)響應正文
6,http和https區別,https在請求時額外的過程,https是如何保證資料安全的
1>. http和https使用的是完全不同的連線方式,用的埠也不一樣,前者是80,後者是443。
2>. https協議需要到ca申請證書,一般免費證書較少,因而需要一定費用。
3>. 原因是,https要比http更加安全一些,也就是說http協議是由ssl+http協議構建的可進行加密傳輸、身份驗證的網路協議要比http協議安全,現在大多數的網站都逐漸用https://,因為安全問題太重要了,有很多的網站都被攻破了,使用者資料被洩露。
7. SESSION機制、cookie機制* cookie通過客戶端確定記錄資訊確定使用者身份,session通過伺服器端記錄資訊確定使用者身份。 * 雖然Session儲存在伺服器,對客戶端是透明的,它的正常執行仍然需要客戶端瀏覽器的支援。這是因為Session需要使用Cookie作為識別標誌。HTTP協議是無狀態的,Session不能依據HTTP連線來判斷是否為同一客戶,因此伺服器向客戶端瀏覽器傳送一個名為JSESSIONID的Cookie,它的值為該Session的id(也就是HttpSession.getId()的返回值)。Session依據該Cookie來識別是否為同一使用者。
8. 交換機和路由器的區別* 路由器可以給你的區域網自動分配IP,虛擬撥號,就像一個交通警察,指揮著你的電腦該往哪走,你自己不用操心那麼多了。交換機只是用來分配網路資料的。 * 路由器在網路層,路由器根據IP地址定址,路由器可以處理TCP/IP協議,交換機不可以。交換機在中繼層,交換機根據MAC地址定址 * 路由器可以把一個IP分配給很多個主機使用,這些主機對外只表現出一個IP。交換機可以把很多主機連起來,這些主機對外各有各的IP。 * 路由器提供防火牆的服務,交換機不能提供該功能。集線器、交換機都是做埠擴充套件的,就是擴大區域網(通常都是乙太網)的接入點,也就是能讓區域網可以連進來更多的電腦。 路由器是用來做網間連線,也就是用來連線不同的網路
9.以下是TCP提供可靠性的方式:
(1)應用資料被分割成TCP認為的最合適傳送的資料塊;
(2)當TCP發出一個報文段後,就啟動一個定時器,用來等待目的端確認收到這個報文段;若沒能及時收到這個確認,TCP傳送端將重新發送這個報文段(超時重傳);
(3)TCP收到一個發自TCP連線的另一端的資料後就將傳送一個確認,不過這個確認不是立即就傳送,而是要推遲幾分之一秒後才傳送; (對於收到的請求,給出確認響應) (之所以推遲,可能是要對包做完整校驗)
(4)TCP將保持它的首部和資料的檢驗和;(這是一個端到端的檢驗和,為了檢驗資料在傳輸過程中發生的錯誤;若檢測到段的檢驗和有差錯,TCP將丟棄和不確認收到此報文段並希望發端可以進行超時重傳)
(5)由於TCP報文段是作為IP資料報來傳輸的,又因為IP資料報的到達可能會失序,所以TCP報文段的到達也可能會失序;因此,有必要的話TCP會對收到的資料進行重新排序後交給應用層;
(6)因為TCP報文段是作為IP資料報來傳輸的,並且IP資料報可能會發生重複,所以TCP的接收端必須丟棄掉重複的資料;
(7)TCP提供流量控制;
10TCP和UDP區別(從機制上來說)
1、TCP面向連線(如打電話要先撥號建立連線);UDP是無連線的,即傳送資料之前不需要建立連線
2、TCP提供可靠的服務。也就是說,通過TCP連線傳送的資料,無差錯,不丟失,不重複,且按序到達;UDP盡最大努力交付,即不保 證可靠交付
3、TCP面向位元組流,實際上是TCP把資料看成一連串無結構的位元組流;UDP是面向報文的
UDP沒有擁塞控制,因此網路出現擁塞不會使源主機的傳送速率降低(對實時應用很有用,如IP電話,實時視訊會議等)
4、每一條TCP連線只能是點到點的;UDP支援一對一,一對多,多對一和多對多的互動通訊
5、TCP首部開銷20位元組;UDP的首部開銷小,只有8個位元組
6、TCP的邏輯通訊通道是全雙工的可靠通道,UDP則是不可靠通道
11.淺談一個網頁開啟的全過程(涉及DNS、CDN、Nginx負載均衡等)
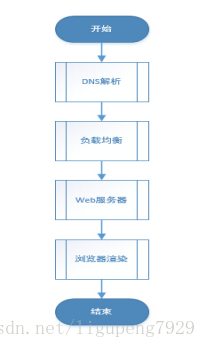
2.1.1 DNS解析
什麼是DNS解析?當用戶輸入一個網址並按下回車鍵的時候,瀏覽器得到了一個域名。而在實際通訊過程中,我們需要的是一個IP地址。因此我們需要先把域名轉換成相應的IP地址,這個過程稱作DNS解析。
1) 瀏覽器首先搜尋瀏覽器自身快取的DNS記錄。
或許很多人不知道,瀏覽器自身也帶有一層DNS快取。Chrome 快取1000條DNS解析結果,快取時間大概在一分鐘左右。
2) 如果瀏覽器快取中沒有找到需要的記錄或記錄已經過期,則搜尋hosts檔案和作業系統快取。
在Windows作業系統中,可以通過 ipconfig /displaydns 命令檢視本機當前的快取。
通過hosts檔案,你可以手動指定一個域名和其對應的IP解析結果,並且該結果一旦被使用,同樣會被快取到作業系統快取中。
Windows系統的hosts檔案在%systemroot%\system32\drivers\etc下,linux系統的hosts檔案在/etc/hosts下。
3) 如果在hosts檔案和作業系統快取中沒有找到需要的記錄或記錄已經過期,則向域名解析伺服器傳送解析請求。
其實第一臺被訪問的域名解析伺服器就是我們平時在設定中填寫的DNS伺服器一項,當作業系統快取中也沒有命中的時候,系統會向DNS伺服器正式發出解析請求。這裡是真正意義上開始解析一個未知的域名。
一般一臺域名解析伺服器會被地理位置臨近的大量使用者使用(特別是ISP的DNS),一般常見的網站域名解析都能在這裡命中。
4) 如果域名解析伺服器也沒有該域名的記錄,則開始遞迴+迭代解析。
這裡我們舉個例子,如果我們要解析的是mail.google.com。
首先我們的域名解析伺服器會向根域伺服器(全球只有13臺)發出請求。顯然,僅憑13臺伺服器不可能把全球所有IP都記錄下來。所以根域伺服器記錄的是com域伺服器的IP、cn域伺服器的IP、org域伺服器的IP……。如果我們要查詢.com結尾的域名,那麼我們可以到com域伺服器去進一步解析。所以其實這部分的域名解析過程是一個樹形的搜尋過程。
根域伺服器告訴我們com域伺服器的IP。
接著我們的域名解析伺服器會向com域伺服器發出請求。根域伺服器並沒有mail.google.com的IP,但是卻有google.com域伺服器的IP。
接著我們的域名解析伺服器會向google.com域伺服器發出請求。...
如此重複,直到獲得mail.google.com的IP地址。
為什麼是遞迴:問題由一開始的本機要解析mail.google.com變成域名解析伺服器要解析mail.google.com,這是遞迴。
為什麼是迭代:問題由向根域伺服器發出請求變成向com域伺服器發出請求再變成向google.com域發出請求,這是迭代。
5) 獲取域名對應的IP後,一步步向上返回,直到返回給瀏覽器。
2.1.2 發起TCP請求
瀏覽器會選擇一個大於1024的本機埠向目標IP地址的80埠發起TCP連線請求。經過標準的TCP握手流程,建立TCP連線。
2.1.3 發起HTTP請求
其本質是在建立起的TCP連線中,按照HTTP協議標準傳送一個索要網頁的請求。
2.1.4 負載均衡
什麼是負載均衡?當一臺伺服器無法支援大量的使用者訪問時,將使用者分攤到兩個或多個伺服器上的方法叫負載均衡。
什麼是Nginx?Nginx是一款面向效能設計的HTTP伺服器,相較於Apache、lighttpd具有佔有記憶體少,穩定性高等優勢。
負載均衡的方法很多,Nginx負載均衡、LVS-NAT、LVS-DR等。這裡,我們以簡單的Nginx負載均衡為例。關於負載均衡的多種方法詳情大家可以Google一下。
Nginx有4種類型的模組:core、handlers、filters、load-balancers。
我們這裡討論其中的2種,分別是負責負載均衡的模組load-balancers和負責執行一系列過濾操作的filters模組。
1) 一般,如果我們的平臺配備了負載均衡的話,前一步DNS解析獲得的IP地址應該是我們Nginx負載均衡伺服器的IP地址。所以,我們的瀏覽器將我們的網頁請求傳送到了Nginx負載均衡伺服器上。
2) Nginx根據我們設定的分配演算法和規則,選擇一臺後端的真實Web伺服器,與之建立TCP連線、並轉發我們瀏覽器發出去的網頁請求。
Nginx預設支援 RR輪轉法 和 ip_hash法 這2種分配演算法。
前者會從頭到尾一個個輪詢所有Web伺服器,而後者則對源IP使用hash函式確定應該轉發到哪個Web伺服器上,也能保證同一個IP的請求能傳送到同一個Web伺服器上實現會話粘連。
也有其他擴充套件分配演算法,如:
fair:這種演算法會選擇相應時間最短的Web伺服器
url_hash:這種演算法會使得相同的url傳送到同一個Web伺服器
3) Web伺服器收到請求,產生響應,並將網頁傳送給Nginx負載均衡伺服器。
4) Nginx負載均衡伺服器將網頁傳遞給filters鏈處理,之後發回給我們的瀏覽器。
而Filter的功能可以理解成先把前一步生成的結果處理一遍,再返回給瀏覽器。比如可以將前面沒有壓縮的網頁用gzip壓縮後再返回給瀏覽器。
2.1.5 瀏覽器渲染
1) 瀏覽器根據頁面內容,生成DOM Tree。根據CSS內容,生成CSS Rule Tree(規則樹)。呼叫JS執行引擎執行JS程式碼。
2) 根據DOM Tree和CSS Rule Tree生成Render Tree(呈現樹)
3) 根據Render Tree渲染網頁
但是在瀏覽器解析頁面內容的時候,會發現頁面引用了其他未載入的image、css檔案、js檔案等靜態內容,因此開始了第二部分。
2.2 網頁靜態資源載入
以阿里巴巴的淘寶網首頁的logo為例,其url地址為 img.alicdn.com/tps/i2/TB1bNE7LFXXXXaOXFXXwFSA1XXX-292-116.png_145x145.jpg
我們清楚地看到了url中有cdn字樣。
什麼是CDN?如果我在廣州訪問杭州的淘寶網,跨省的通訊必然造成延遲。如果淘寶網能在廣東建立一個伺服器,靜態資源我可以直接從就近的廣東伺服器獲取,必然能提高整個網站的開啟速度,這就是CDN。CDN叫內容分發網路,是依靠部署在各地的邊緣伺服器,使使用者就近獲取所需內容,降低網路擁塞,提高使用者訪問響應速度。
接下來的流程就是瀏覽器根據url載入該url下的圖片內容。本質上是瀏覽器重新開始第一部分的流程,所以這裡不再重複闡述。區別只是負責均衡伺服器後端的伺服器不再是應用伺服器,而是提供靜態資源的伺服器。