
從服務端載入分頁資料的策略
阿新 • • 發佈:2019-01-26
我在查閱如何優雅地處理分頁資料的時候偶然看到了這篇文章。說實話,本來只是想查查客戶端在處理分頁載入的資料時候怎麼對請求進行封裝,而不是每次面對分頁資料都要額外寫一大堆程式碼,但是這篇文章提到的問題是我之間沒有考慮到的,覺得不錯,就斗膽翻譯一下。
說明一下,這篇文章到的本意是針對推特的時間軸的,時間軸裡面由很多Tweets組成,我其實不太明白這到底是什麼資料,所以文章後頭就把Tweets都用資料進行替換了,主要學習的是這種避免讀到冗餘資料的策略,當然文末也說了,這種策略只適用於有序的資料集,若是亂序的,可能需要其他的解決方法。
處理時間軸(Working with timeline)
簡介
推特的API有一些方法,如分頁存在的問題
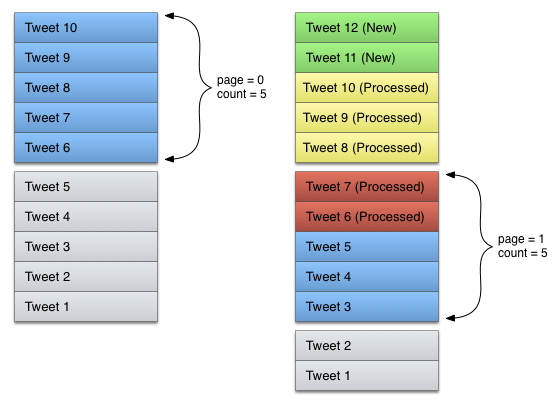
在理想情況下,分頁是一個非常同意實現的問題。假設這條時間軸有10條按時間倒敘排列的Tweets,一個應用可能嘗試通過分兩頁載入,每次載入5條資料的方法去讀取整條時間軸,如圖所示:
那麼問題來了,推特的這條時間軸可能不斷地有新的元素新增進來,在先前那種載入策略下,如果讀取第一次資料和第二次資料之間,時間軸又新增進兩條資料,那麼第二次請求的結果將會包含第一次請求已經得到的兩條資料,如圖所示:
事實上,如果有5條或是更多的資料在兩次請求之間被新增進來,隨後的請求可能最終得到的都是之前請求已經得到的資料,這就會使整個API請求完全冗餘。
新增一個max_id引數
上述問題的解決方法是通過對處理的資料流新增一個標識,而不是一直相對於列表頂部的位置來取資料(列表頂部可能經常會改變),應用應該把處理過的最後一條資料作為參考點,這就需要在請求時新增一條max_id的引數。 為了正確使用max_id,在第一次請求資料時,提交的引數只包含一個count也就是請求資料的數量,在處理這條資料和隨後的響應之後,持續追蹤最後收到這條資料的id,這個id將被作為下一次請求的max_id,使服務端只返回這條資料(包含這條資料)之後的資料,值得一提的是,如果max_id所對應的這條資料被包含了,那麼也會造成資料的冗餘,如下圖所示:
為具有64位的環境優化max_id
雖然僅僅一條冗餘的資料不是非常影響效率,但是如果你處於64位的環境下,依然有可能在處理這個問題時優化max_id的策略,如果一個數據的ID不能被表示為一個具有64位精度(比如JavaScript)的整數,則應該跳過這一步,從上一個請求中的到的最後一條資料的id再減去1作為下一次請求的max_id,即時這條id並非有效也無關緊要,這個值只是決定去過濾哪些資料,如果以這種方式調整,可以避免讀到冗餘的資料:
使用since_id使其成為最有效的解決方法
一個應用處理完時間軸之後過了一段時間,在處理完時間軸之後又有新的資料插入時間軸,這種情況可以通過新增since_id引數對這個問題進行優化。 有這麼一種情況,你已經從服務端拿到了1-10這幾條資料。現在又有八條新的資料11-18插入了時間軸,這時候你必須從頭開始讀取資料,一種比較低效的方式是從列表頭開始讀取,每次讀取五條,直到讀到編號10這條資料,這會導致兩條已經讀過的資料被返回:
通過把之前讀到的最高id的資料設定為since_id可以解決這個問題,與max_id不同,since_id對應的資料是不被包含的,所以不需要再次調整id的值,如下圖所示,服務端只會返回高於since_id的資料:

同時使用max_id和since_id的方式可以讓讀到的冗餘資料達到最小,保證得到的所有資料都是有效的。 當然,如果資料是亂序排列的,這種方法就不適用了。