
python lxml中etree的簡單應用1
我一般都是通過xpath解析DOM樹的時候會使用lxml的etree,可以很方便的從html原始碼中得到自己想要的內容。
這裡主要介紹一下我常用到的兩個方法,分別是etree.HTML()和etree.tostrint()。
1.etree.HTML()
etree.HTML()可以用來解析字串格式的HTML文件物件,將傳進去的字串轉變成_Element物件。作為_Element物件,可以方便的使用getparent()、remove()、xpath()等方法。
如果想通過xpath獲取html原始碼中的內容,就要先將html原始碼轉換成_Element物件,然後再使用xpath()方法進行解析。例如,這裡有一段最簡單的html原始碼:"<html><body><h1>This is a test</h1></body></html>",現在想要得到h1標籤中的文字,可以這樣實現:
# encoding=utf8
from lxml import etree
html = '<html><body><h1>This is a test</h1></body></html>'
# 將html轉換成_Element物件
_element = etree.HTML(html)
# 通過xpath表示式獲取h1標籤中的文字
text = _element.xpath('//h1/text()')
print 'result is: ', text結果:
result is: ['This is a test']
通過結果可以知道,xpath()方法放回的結果是一個列表,所以通常在取xpath()方法結果的時候,只取列表中的第一個元素。
2.etree.tostring()
etree.tostring()方法用來將_Element物件轉換成字串。一般通過簡單的xpath表示式無法得到想要的內容的時候我就會用該方法。例如,將上面的html小改動一下:"<html><body><h1>This <a>is a </a>test</h1></body></html>",這時候如果想要得到h1中的文字該怎麼辦呢?使用“//h1/text()”試試(將上面的html儲存並用火狐瀏覽器開啟,然後在FirePath中輸入該xpath表示式):

通過截圖左下角的提示可以知道,使用xpath表示式“//h1/text()”只能得到h1標籤中文字的“This”和“test”,用程式碼實現看看:
# encoding=utf8
from lxml import etree
html = '<html><body><h1>This <a>is a </a>test</h1></body></html>'
_element = etree.HTML(html)
text = _element.xpath('//h1/text()')
print 'result is: ', text執行結果:
result is: ['This ', 'test']確實,使用xpath()方法,只能得到h1中部分文字內容,我們再試試使用“//h1//text()”看看:
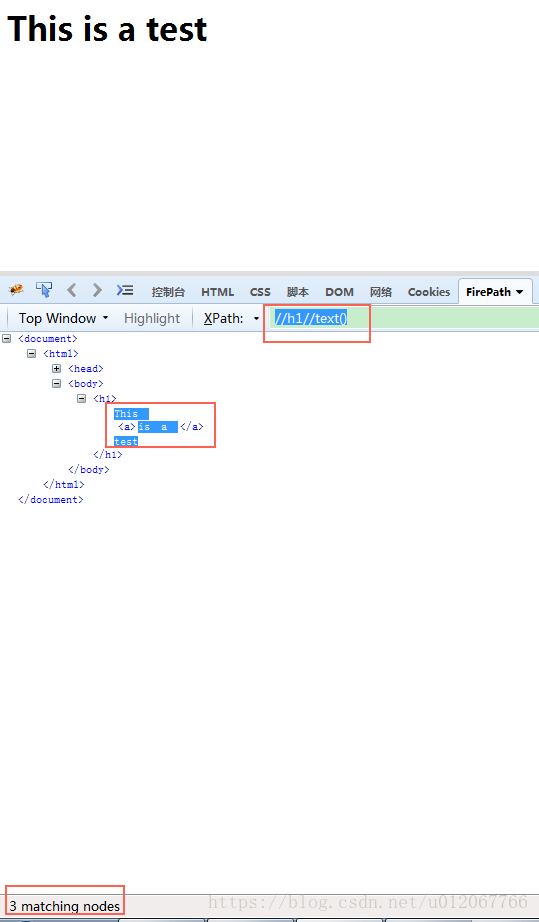
然後通過程式碼實現看看:
# encoding=utf8
from lxml import etree
html = '<html><body><h1>This <a>is a </a>test</h1></body></html>'
_element = etree.HTML(html)
text = _element.xpath('//h1//text()')
print 'result is: ', text執行結果:
result is: ['This ', 'is a ', 'test']通過“//h1//text()”表示式確實可以得到想要的內容,但是得到的是一個列表,還需要將列表中的所有元素“拼”起來才行,是不是有點麻煩。這時候,就可以考慮使用etree.tostring()方法了,etree.tostring()方法可以傳遞多個引數,包括element_or_tree、encoding、method等,其中method引數為text的時候,表示返回_Element物件中的所有文字,所以可以這樣:
# encoding=utf8
from lxml import etree
html = '<html><body><h1>This <a>is a </a>test</h1></body></html>'
_element = etree.HTML(html)
# 先找到h1物件,然後通過etree.tostring方法找到h1物件中的所有文字
_h = _element.xpath('//h1')
# 注意,xpath方法返回的是一個列表,我們需要的是列表中的第一個元素:代表h1標籤的_Element物件
result = etree.tostring(_h[0], method='text')
print 'result is: ', result執行結果:
result is: This is a test這時候使用etree.tostring()方法是不是很容易的就解決問題了。