
Java面試題彙總與解答
2018最新Java面試題整理(持續完善中…)
宣告:面試題(無參考答案)收集自公眾號服務端思維,本人抱著學習的態度網上找了下參考答案,有不足的地方還請指正,謝謝~
基礎篇
基本功
面向物件特徵
封裝,繼承,多型和抽象
- 封裝
封裝給物件提供了隱藏內部特性和行為的能力。物件提供一些能被其他物件訪問的方法來改
變它內部的資料。在 Java 當中,有 3 種修飾符: public, private 和 protected。每一種修飾符
給其他的位於同一個包或者不同包下面物件賦予了不同的訪問許可權。
下面列出了使用封裝的一些好處:
- 通過隱藏物件的屬性來保護物件內部的狀態。
- 提高了程式碼的可用性和可維護性,因為物件的行為可以被單獨的改變或者是擴充套件。
- 禁止物件之間的不良互動提高模組化
-
繼承
繼承給物件提供了從基類獲取欄位和方法的能力。繼承提供了程式碼的重用行,也可以在不修改類的情況下給現存的類新增新特性。 -
多型
多型是程式語言給不同的底層資料型別做相同的介面展示的一種能力。一個多型型別上的操作可以應用到其他型別的值上面。 -
抽象
抽象是把想法從具體的例項中分離出來的步驟,因此,要根據他們的功能而不是實現細節來建立類。 Java 支援建立只暴漏介面而不包含方法實現的抽象的類。這種抽象技術的主要目的是把類的行為和實現細節分離開。
final, finally, finalize 的區別
-
final
修飾符(關鍵字)如果一個類被宣告為final,意味著它不能再派生出新的子類,不能作為父類被繼承。因此一個類不能既被宣告為 abstract的,又被宣告為final的。將變數或方法宣告為final,可以保證它們在使用中不被改變。被宣告為final的變數必須在宣告時給定初值,而在以後的引用中只能讀取,不可修改。被宣告為final的方法也同樣只能使用,不能過載。 -
finally
在異常處理時提供 finally 塊來執行任何清除操作。如果丟擲一個異常,那麼相匹配的 catch 子句就會執行,然後控制就會進入 finally 塊(如果有的話)。 -
finalize
方法名。Java 技術允許使用 finalize() 方法在垃圾收集器將物件從記憶體中清除出去之前做必要的清理工作。這個方法是由垃圾收集器在確定這個物件沒有被引用時對這個物件呼叫的。它是在 Object 類中定義的,因此所有的類都繼承了它。子類覆蓋 finalize() 方法以整理系統資源或者執行其他清理工作。finalize() 方法是在垃圾收集器刪除物件之前對這個物件呼叫的。
int 和 Integer 有什麼區別
int 是基本資料型別
Integer是其包裝類,注意是一個類。
為什麼要提供包裝類呢???
一是為了在各種型別間轉化,通過各種方法的呼叫。否則 你無法直接通過變數轉化。
比如,現在int要轉為String
int a=0;
String result=Integer.toString(a);
在java中包裝類,比較多的用途是用在於各種資料型別的轉化中。
我寫幾個demo
//通過包裝類來實現轉化的
int num=Integer.valueOf("12");
int num2=Integer.parseInt("12");
double num3=Double.valueOf("12.2");
double num4=Double.parseDouble("12.2");
//其他的類似。通過基本資料型別的包裝來的valueOf和parseXX來實現String轉為XX
String a=String.valueOf("1234");//這裡括號中幾乎可以是任何型別
String b=String.valueOf(true);
String c=new Integer(12).toString();//通過包裝類的toString()也可以
String d=new Double(2.3).toString();
再舉例下。比如我現在要用泛型
List<Integer> nums;
這裡<>需要類。如果你用int。它會報錯的。
過載和重寫的區別
- override(重寫)
1. 方法名、引數、返回值相同。
2. 子類方法不能縮小父類方法的訪問許可權。
3. 子類方法不能丟擲比父類方法更多的異常(但子類方法可以不丟擲異常)。
4. 存在於父類和子類之間。
5. 方法被定義為final不能被重寫。
- overload(過載)
1. 引數型別、個數、順序至少有一個不相同。
2. 不能過載只有返回值不同的方法名。
3. 存在於父類和子類、同類中。
| 區別點 | 過載 | 重寫(覆寫) |
|---|---|---|
| 英文 | Overloading | Overiding |
| 定義 | 方法名稱相同,引數的型別或個數不同 | 方法名稱、引數型別、返回值型別全部相同 |
| 許可權 | 對許可權沒要求 | 被重寫的方法不能擁有更嚴格的許可權 |
| 範圍 | 發生在一個類中 | 發生在繼承類中 |
抽象類和介面有什麼區別
介面是公開的,裡面不能有私有的方法或變數,是用於讓別人使用的,而抽象類是可以有私有方法或私有變數的,
另外,實現介面的一定要實現接口裡定義的所有方法,而實現抽象類可以有選擇地重寫需要用到的方法,一般的應用裡,最頂級的是介面,然後是抽象類實現介面,最後才到具體類實現。
還有,介面可以實現多重繼承,而一個類只能繼承一個超類,但可以通過繼承多個介面實現多重繼承,介面還有標識(裡面沒有任何方法,如Remote介面)和資料共享(裡面的變數全是常量)的作用。
說說反射的用途及實現
Java反射機制主要提供了以下功能:在執行時構造一個類的物件;判斷一個類所具有的成員變數和方法;呼叫一個物件的方法;生成動態代理。反射最大的應用就是框架
Java反射的主要功能:
- 確定一個物件的類
- 取出類的modifiers,資料成員,方法,構造器,和超類.
- 找出某個接口裡定義的常量和方法說明.
- 建立一個類例項,這個例項在執行時刻才有名字(執行時間才生成的物件).
- 取得和設定物件資料成員的值,如果資料成員名是執行時刻確定的也能做到.
- 在執行時刻呼叫動態物件的方法.
- 建立陣列,陣列大小和型別在執行時刻才確定,也能更改陣列成員的值.
反射的應用很多,很多框架都有用到
spring 的 ioc/di 也是反射…
javaBean和jsp之間呼叫也是反射…
struts的 FormBean 和頁面之間…也是通過反射呼叫…
JDBC 的 classForName()也是反射…
hibernate的 find(Class clazz) 也是反射…
反射還有一個不得不說的問題,就是效能問題,大量使用反射系統性能大打折扣。怎麼使用使你的系統達到最優就看你係統架構和綜合使用問題啦,這裡就不多說了。
說說自定義註解的場景及實現
(此題自由發揮,就看你對註解的理解了!==)登陸、許可權攔截、日誌處理,以及各種Java框架,如Spring,Hibernate,JUnit 提到註解就不能不說反射,Java自定義註解是通過執行時靠反射獲取註解。實際開發中,例如我們要獲取某個方法的呼叫日誌,可以通過AOP(動態代理機制)給方法新增切面,通過反射來獲取方法包含的註解,如果包含日誌註解,就進行日誌記錄。
HTTP 請求的 GET 與 POST 方式的區別
GET方法會把名值對追加在請求的URL後面。因為URL對字元數目有限制,進而限制了用在客戶端請求的引數值的數目。並且請求中的引數值是可見的,因此,敏感資訊不能用這種方式傳遞。
POST方法通過把請求引數值放在請求體中來克服GET方法的限制,因此,可以傳送的引數的數目是沒有限制的。最後,通過POST請求傳遞的敏感資訊對外部客戶端是不可見的。
session 與 cookie 區別
cookie 是 Web 伺服器傳送給瀏覽器的一塊資訊。瀏覽器會在本地檔案中給每一個 Web 服務
器儲存 cookie。以後瀏覽器在給特定的 Web 伺服器發請求的時候,同時會發送所有為該服
務器儲存的 cookie。下面列出了 session 和 cookie 的區別:
無論客戶端瀏覽器做怎麼樣的設定,session都應該能正常工作。客戶端可以選擇禁用 cookie,
但是, session 仍然是能夠工作的,因為客戶端無法禁用服務端的 session。
JDBC 流程
1、 載入JDBC驅動程式:
在連線資料庫之前,首先要載入想要連線的資料庫的驅動到JVM(Java虛擬機器),
這通過java.lang.Class類的靜態方法forName(String className)實現。
例如:
try{
//載入MySql的驅動類
Class.forName("com.mysql.jdbc.Driver") ;
}catch(ClassNotFoundException e){
System.out.println("找不到驅動程式類 ,載入驅動失敗!");
e.printStackTrace() ;
}
成功載入後,會將Driver類的例項註冊到DriverManager類中。
2、 提供JDBC連線的URL
- 連線URL定義了連線資料庫時的協議、子協議、資料來源標識。
- 書寫形式:協議:子協議:資料來源標識
協議:在JDBC中總是以jdbc開始 子協議:是橋連線的驅動程式或是資料庫管理系統名稱。
資料來源標識:標記找到資料庫來源的地址與連線埠。
例如:
jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=gbk;useUnicode=true;(MySql的連線URL)
表示使用Unicode字符集。如果characterEncoding設定為 gb2312或GBK,本引數必須設定為true 。characterEncoding=gbk:字元編碼方式。
3、建立資料庫的連線
- 要連線資料庫,需要向java.sql.DriverManager請求並獲得Connection物件, 該物件就代表一個數據庫的連線。
- 使用DriverManager的getConnectin(String url , String username , String password )方法傳入指定的欲連線的資料庫的路徑、資料庫的使用者名稱和 密碼來獲得。
例如: //連線MySql資料庫,使用者名稱和密碼都是root
String url = "jdbc:mysql://localhost:3306/test" ;
String username = "root" ;
String password = "root" ;
try{
Connection con = DriverManager.getConnection(url , username , password ) ;
}catch(SQLException se){
System.out.println("資料庫連線失敗!");
se.printStackTrace() ;
}
4、 建立一個Statement
•要執行SQL語句,必須獲得java.sql.Statement例項,Statement例項分為以下3 種類型:
1、執行靜態SQL語句。通常通過Statement例項實現。
2、執行動態SQL語句。通常通過PreparedStatement例項實現。
3、執行資料庫儲存過程。通常通過CallableStatement例項實現。
具體的實現方式:
Statement stmt = con.createStatement() ; PreparedStatement pstmt = con.prepareStatement(sql) ; CallableStatement cstmt = con.prepareCall("{CALL demoSp(? , ?)}") ;
5、執行SQL語句
Statement介面提供了三種執行SQL語句的方法:executeQuery 、executeUpdate 和execute
1、ResultSet executeQuery(String sqlString):執行查詢資料庫的SQL語句 ,返回一個結果集(ResultSet)物件。
2、int executeUpdate(String sqlString):用於執行INSERT、UPDATE或 DELETE語句以及SQL DDL語句,如:CREATE TABLE和DROP TABLE等
3、execute(sqlString):用於執行返回多個結果集、多個更新計數或二者組合的 語句。 具體實現的程式碼:
ResultSet rs = stmt.executeQuery(“SELECT * FROM …”) ; int rows = stmt.executeUpdate(“INSERT INTO …”) ; boolean flag = stmt.execute(String sql) ;
6、處理結果
兩種情況:
1、執行更新返回的是本次操作影響到的記錄數。
2、執行查詢返回的結果是一個ResultSet物件。
• ResultSet包含符合SQL語句中條件的所有行,並且它通過一套get方法提供了對這些 行中資料的訪問。
• 使用結果集(ResultSet)物件的訪問方法獲取資料:
while(rs.next()){
String name = rs.getString(“name”) ;
String pass = rs.getString(1) ; // 此方法比較高效
}
(列是從左到右編號的,並且從列1開始)
7、關閉JDBC物件
操作完成以後要把所有使用的JDBC物件全都關閉,以釋放JDBC資源,關閉順序和聲 明順序相反:
1、關閉記錄集
2、關閉宣告
3、關閉連線物件
if(rs != null){ // 關閉記錄集
try{
rs.close() ;
}catch(SQLException e){
e.printStackTrace() ;
}
}
if(stmt != null){ // 關閉宣告
try{
stmt.close() ;
}catch(SQLException e){
e.printStackTrace() ;
}
}
if(conn != null){ // 關閉連線物件
try{
conn.close() ;
}catch(SQLException e){
e.printStackTrace() ;
}
}
MVC 設計思想
MVC就是
M:Model 模型
V:View 檢視
C:Controller 控制器
模型就是封裝業務邏輯和資料的一個一個的模組,控制器就是呼叫這些模組的(java中通常是用Servlet來實現,框架的話很多是用Struts2來實現這一層),檢視就主要是你看到的,比如JSP等.
當用戶發出請求的時候,控制器根據請求來選擇要處理的業務邏輯和要選擇的資料,再返回去把結果輸出到檢視層,這裡可能是進行重定向或轉發等.
equals 與 == 的區別
值型別(int,char,long,boolean等)都是用==判斷相等性。物件引用的話,判斷引用所指的物件是否是同一個。equals是Object的成員函式,有些類會覆蓋(override)這個方法,用於判斷物件的等價性。例如String類,兩個引用所指向的String都是"abc",但可能出現他們實際對應的物件並不是同一個(和jvm實現方式有關),因此用判斷他們可能不相等,但用equals判斷一定是相等的。
集合
List 和 Set 區別
List,Set都是繼承自Collection介面
List特點:元素有放入順序,元素可重複
Set特點:元素無放入順序,元素不可重複,重複元素會覆蓋掉
(注意:元素雖然無放入順序,但是元素在set中的位置是有該元素的HashCode決定的,其位置其實是固定的,加入Set 的Object必須定義equals()方法 ,另外list支援for迴圈,也就是通過下標來遍歷,也可以用迭代器,但是set只能用迭代,因為他無序,無法用下標來取得想要的值。)
Set和List對比:
Set:檢索元素效率低下,刪除和插入效率高,插入和刪除不會引起元素位置改變。
List:和陣列類似,List可以動態增長,查詢元素效率高,插入刪除元素效率低,因為會引起其他元素位置改變。
List 和 Map 區別
List是物件集合,允許物件重複。
Map是鍵值對的集合,不允許key重複。
Arraylist 與 LinkedList 區別
Arraylist:
優點:ArrayList是實現了基於動態陣列的資料結構,因為地址連續,一旦資料儲存好了,查詢操作效率會比較高(在記憶體裡是連著放的)。
缺點:因為地址連續, ArrayList要移動資料,所以插入和刪除操作效率比較低。
LinkedList:
優點:LinkedList基於連結串列的資料結構,地址是任意的,所以在開闢記憶體空間的時候不需要等一個連續的地址,對於新增和刪除操作add和remove,LinedList比較佔優勢。LinkedList 適用於要頭尾操作或插入指定位置的場景
缺點:因為LinkedList要移動指標,所以查詢操作效能比較低。
適用場景分析:
當需要對資料進行對此訪問的情況下選用ArrayList,當需要對資料進行多次增加刪除修改時採用LinkedList。
ArrayList 與 Vector 區別
public ArrayList(int initialCapacity)//構造一個具有指定初始容量的空列表。
public ArrayList()//構造一個初始容量為10的空列表。
public ArrayList(Collection<? extends E> c)//構造一個包含指定 collection 的元素的列表
Vector有四個構造方法:
public Vector()//使用指定的初始容量和等於零的容量增量構造一個空向量。
public Vector(int initialCapacity)//構造一個空向量,使其內部資料陣列的大小,其標準容量增量為零。
public Vector(Collection<? extends E> c)//構造一個包含指定 collection 中的元素的向量
public Vector(int initialCapacity,int capacityIncrement)//使用指定的初始容量和容量增量構造一個空的向量
ArrayList和Vector都是用陣列實現的,主要有這麼三個區別:
-
Vector是多執行緒安全的,執行緒安全就是說多執行緒訪問同一程式碼,不會產生不確定的結果。而ArrayList不是,這個可以從原始碼中看出,Vector類中的方法很多有synchronized進行修飾,這樣就導致了Vector在效率上無法與ArrayList相比;
-
兩個都是採用的線性連續空間儲存元素,但是當空間不足的時候,兩個類的增加方式是不同。
-
Vector可以設定增長因子,而ArrayList不可以。
-
Vector是一種老的動態陣列,是執行緒同步的,效率很低,一般不贊成使用。
適用場景分析:
-
Vector是執行緒同步的,所以它也是執行緒安全的,而ArrayList是執行緒非同步的,是不安全的。如果不考慮到執行緒的安全因素,一般用ArrayList效率比較高。
-
如果集合中的元素的數目大於目前集合陣列的長度時,在集合中使用資料量比較大的資料,用Vector有一定的優勢。
HashMap 和 Hashtable 的區別
1.hashMap去掉了HashTable 的contains方法,但是加上了containsValue()和containsKey()方法。
2.hashTable同步的,而HashMap是非同步的,效率上逼hashTable要高。
3.hashMap允許空鍵值,而hashTable不允許。
注意:
TreeMap:非執行緒安全基於紅黑樹實現。TreeMap沒有調優選項,因為該樹總處於平衡狀態。
Treemap:適用於按自然順序或自定義順序遍歷鍵(key)。
HashSet 和 HashMap 區別
set是線性結構,set中的值不能重複,hashset是set的hash實現,hashset中值不能重複是用hashmap的key來實現的。
map是鍵值對對映,可以空鍵空值。HashMap是Map介面的hash實現,key的唯一性是通過key值hash值的唯一來確定,value值是則是連結串列結構。
他們的共同點都是hash演算法實現的唯一性,他們都不能持有基本型別,只能持有物件
HashMap 和 ConcurrentHashMap 的區別
ConcurrentHashMap是執行緒安全的HashMap的實現。
(1)ConcurrentHashMap對整個桶陣列進行了分割分段(Segment),然後在每一個分段上都用lock鎖進行保護,相對於HashTable的syn關鍵字鎖的粒度更精細了一些,併發效能更好,而HashMap沒有鎖機制,不是執行緒安全的。
(2)HashMap的鍵值對允許有null,但是ConCurrentHashMap都不允許。
HashMap 的工作原理及程式碼實現
ConcurrentHashMap 的工作原理及程式碼實現
HashTable裡使用的是synchronized關鍵字,這其實是對物件加鎖,鎖住的都是物件整體,當Hashtable的大小增加到一定的時候,效能會急劇下降,因為迭代時需要被鎖定很長的時間。
ConcurrentHashMap算是對上述問題的優化,其建構函式如下,預設傳入的是16,0.75,16。
public ConcurrentHashMap(int paramInt1, float paramFloat, int paramInt2) {
//…
int i = 0;
int j = 1;
while (j < paramInt2) {
++i;
j <<= 1;
}
this.segmentShift = (32 - i);
this.segmentMask = (j - 1);
this.segments = Segment.newArray(j);
//…
int k = paramInt1 / j;
if (k * j < paramInt1)
++k;
int l = 1;
while (l < k)
l <<= 1;
for (int i1 = 0; i1 < this.segments.length; ++i1)
this.segments[i1] = new Segment(l, paramFloat);
}
public V put(K paramK, V paramV) {
if (paramV == null)
throw new NullPointerException();
int i = hash(paramK.hashCode()); //這裡的hash函式和HashMap中的不一樣
return this.segments[(i >>> this.segmentShift & this.segmentMask)].put(paramK, i, paramV, false);
}
ConcurrentHashMap引入了分割(Segment),上面程式碼中的最後一行其實就可以理解為把一個大的Map拆分成N個小的HashTable,在put方法中,會根據hash(paramK.hashCode())來決定具體存放進哪個Segment,如果檢視Segment的put操作,我們會發現內部使用的同步機制是基於lock操作的,這樣就可以對Map的一部分(Segment)進行上鎖,這樣影響的只是將要放入同一個Segment的元素的put操作,保證同步的時候,鎖住的不是整個Map(HashTable就是這麼做的),相對於HashTable提高了多執行緒環境下的效能,因此HashTable已經被淘汰了。
執行緒
建立執行緒的方式及實現
Java中建立執行緒主要有三種方式:
一、繼承Thread類建立執行緒類
(1)定義Thread類的子類,並重寫該類的run方法,該run方法的方法體就代表了執行緒要完成的任務。因此把run()方法稱為執行體。
(2)建立Thread子類的例項,即建立了執行緒物件。
(3)呼叫執行緒物件的start()方法來啟動該執行緒。
package com.thread;
public class FirstThreadTest extends Thread{
int i = 0;
//重寫run方法,run方法的方法體就是現場執行體
public void run()
{
for(;i<100;i++){
System.out.println(getName()+" "+i);
}
}
public static void main(String[] args)
{
for(int i = 0;i< 100;i++)
{
System.out.println(Thread.currentThread().getName()+" : "+i);
if(i==20)
{
new FirstThreadTest().start();
new FirstThreadTest().start();
}
}
}
}
上述程式碼中Thread.currentThread()方法返回當前正在執行的執行緒物件。getName()方法返回呼叫該方法的執行緒的名字。
二、通過Runnable介面建立執行緒類
(1)定義runnable介面的實現類,並重寫該介面的run()方法,該run()方法的方法體同樣是該執行緒的執行緒執行體。
(2)建立 Runnable實現類的例項,並依此例項作為Thread的target來建立Thread物件,該Thread物件才是真正的執行緒物件。
(3)呼叫執行緒物件的start()方法來啟動該執行緒。
package com.thread;
public class RunnableThreadTest implements Runnable
{
private int i;
public void run()
{
for(i = 0;i <100;i++)
{
System.out.println(Thread.currentThread().getName()+" "+i);
}
}
public static void main(String[] args)
{
for(int i = 0;i < 100;i++)
{
System.out.println(Thread.currentThread().getName()+" "+i);
if(i==20)
{
RunnableThreadTest rtt = new RunnableThreadTest();
new Thread(rtt,"新執行緒1").start();
new Thread(rtt,"新執行緒2").start();
}
}
}
}
三、通過Callable和Future建立執行緒
(1)建立Callable介面的實現類,並實現call()方法,該call()方法將作為執行緒執行體,並且有返回值。
(2)建立Callable實現類的例項,使用FutureTask類來包裝Callable物件,該FutureTask物件封裝了該Callable物件的call()方法的返回值。
(3)使用FutureTask物件作為Thread物件的target建立並啟動新執行緒。
(4)呼叫FutureTask物件的get()方法來獲得子執行緒執行結束後的返回值
package com.thread;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class CallableThreadTest implements Callable<Integer>
{
public static void main(String[] args)
{
CallableThreadTest ctt = new CallableThreadTest();
FutureTask<Integer> ft = new FutureTask<>(ctt);
for(int i = 0;i < 100;i++)
{
System.out.println(Thread.currentThread().getName()+" 的迴圈變數i的值"+i);
if(i==20)
{
new Thread(ft,"有返回值的執行緒").start();
}
}
try
{
System.out.println("子執行緒的返回值:"+ft.get());
} catch (InterruptedException e)
{
e.printStackTrace();
} catch (ExecutionException e)
{
e.printStackTrace();
}
}
@Override
public Integer call() throws Exception
{
int i = 0;
for(;i<100;i++)
{
System.out.println(Thread.currentThread().getName()+" "+i);
}
return i;
}
}
建立執行緒的三種方式的對比
採用實現Runnable、Callable介面的方式創見多執行緒時,優勢是:
執行緒類只是實現了Runnable介面或Callable介面,還可以繼承其他類。
在這種方式下,多個執行緒可以共享同一個target物件,所以非常適合多個相同執行緒來處理同一份資源的情況,從而可以將CPU、程式碼和資料分開,形成清晰的模型,較好地體現了面向物件的思想。
劣勢是:
程式設計稍微複雜,如果要訪問當前執行緒,則必須使用Thread.currentThread()方法。
使用繼承Thread類的方式建立多執行緒時優勢是:
編寫簡單,如果需要訪問當前執行緒,則無需使用Thread.currentThread()方法,直接使用this即可獲得當前執行緒。
劣勢是:
執行緒類已經繼承了Thread類,所以不能再繼承其他父類。
sleep() 、join()、yield()有什麼區別
1、sleep()方法
在指定的毫秒數內讓當前正在執行的執行緒休眠(暫停執行),此操作受到系統計時器和排程程式精度和準確性的影響。 讓其他執行緒有機會繼續執行,但它並不釋放物件鎖。也就是如果有Synchronized同步塊,其他執行緒仍然不能訪問共享資料。注意該方法要捕獲異常
比如有兩個執行緒同時執行(沒有Synchronized),一個執行緒優先順序為MAX_PRIORITY,另一個為MIN_PRIORITY,如果沒有Sleep()方法,只有高優先順序的執行緒執行完成後,低優先順序的執行緒才能執行;但當高優先順序的執行緒sleep(5000)後,低優先順序就有機會執行了。
總之,sleep()可以使低優先順序的執行緒得到執行的機會,當然也可以讓同優先順序、高優先順序的執行緒有執行的機會。
2、yield()方法
yield()方法和sleep()方法類似,也不會釋放“鎖標誌”,區別在於,它沒有引數,即yield()方法只是使當前執行緒重新回到可執行狀態,所以執行yield()的執行緒有可能在進入到可執行狀態後馬上又被執行,另外yield()方法只能使同優先順序或者高優先順序的執行緒得到執行機會,這也和sleep()方法不同。
3、join()方法
Thread的非靜態方法join()讓一個執行緒B“加入”到另外一個執行緒A的尾部。在A執行完畢之前,B不能工作。
Thread t = new MyThread();
t.start();
t.join();
保證當前執行緒停止執行,直到該執行緒所加入的執行緒完成為止。然而,如果它加入的執行緒沒有存活,則當前執行緒不需要停止。
說說 CountDownLatch 原理
參考:
說說 CyclicBarrier 原理
參考:
說說 Semaphore 原理
說說 Exchanger 原理
說說 CountDownLatch 與 CyclicBarrier 區別
| CountDownLatch | CyclicBarrier |
|---|---|
| 減計數方式 | 加計數方式 |
| 計算為0時釋放所有等待的執行緒 | 計數達到指定值時釋放所有等待執行緒 |
| 計數為0時,無法重置 | 計數達到指定值時,計數置為0重新開始 |
| 呼叫countDown()方法計數減一,呼叫await()方法只進行阻塞,對計數沒任何影響 | 呼叫await()方法計數加1,若加1後的值不等於構造方法的值,則執行緒阻塞 |
| 不可重複利用 | 可重複利用 |
ThreadLocal 原理分析
講講執行緒池的實現原理
主要是ThreadPoolExecutor的實現原理
執行緒池的幾種方式
newFixedThreadPool(int nThreads)
建立一個固定長度的執行緒池,每當提交一個任務就建立一個執行緒,直到達到執行緒池的最大數量,這時執行緒規模將不再變化,當執行緒發生未預期的錯誤而結束時,執行緒池會補充一個新的執行緒
newCachedThreadPool()
建立一個可快取的執行緒池,如果執行緒池的規模超過了處理需求,將自動回收空閒執行緒,而當需求增加時,則可以自動新增新執行緒,執行緒池的規模不存在任何限制
newSingleThreadExecutor()
這是一個單執行緒的Executor,它建立單個工作執行緒來執行任務,如果這個執行緒異常結束,會建立一個新的來替代它;它的特點是能確保依照任務在佇列中的順序來序列執行
newScheduledThreadPool(int corePoolSize)
建立了一個固定長度的執行緒池,而且以延遲或定時的方式來執行任務,類似於Timer。
舉個栗子
private static final Executor exec=Executors.newFixedThreadPool(50);
Runnable runnable=new Runnable(){
public void run(){
...
}
}
exec.execute(runnable);
Callable<Object> callable=new Callable<Object>() {
public Object call() throws Exception {
return null;
}
};
Future future=executorService.submit(callable);
future.get(); // 等待計算完成後,獲取結果
future.isDone(); // 如果任務已完成,則返回 true
future.isCancelled(); // 如果在任務正常完成前將其取消,則返回 true
future.cancel(true); // 試圖取消對此任務的執行,true中斷執行的任務,false允許正在執行的任務執行完成
參考:
執行緒的生命週期
新建(New)、就緒(Runnable)、執行(Running)、阻塞(Blocked)和死亡(Dead)5種狀態
(1)生命週期的五種狀態
新建(new Thread)
當建立Thread類的一個例項(物件)時,此執行緒進入新建狀態(未被啟動)。
例如:Thread t1=new Thread();
就緒(runnable)
執行緒已經被啟動,正在等待被分配給CPU時間片,也就是說此時執行緒正在就緒佇列中排隊等候得到CPU資源。例如:t1.start();
執行(running)
執行緒獲得CPU資源正在執行任務(run()方法),此時除非此執行緒自動放棄CPU資源或者有優先順序更高的執行緒進入,執行緒將一直執行到結束。
死亡(dead)
當執行緒執行完畢或被其它執行緒殺死,執行緒就進入死亡狀態,這時執行緒不可能再進入就緒狀態等待執行。
自然終止:正常執行run()方法後終止
異常終止:呼叫**stop()**方法讓一個執行緒終止執行
堵塞(blocked)
由於某種原因導致正在執行的執行緒讓出CPU並暫停自己的執行,即進入堵塞狀態。
正在睡眠:用sleep(long t) 方法可使執行緒進入睡眠方式。一個睡眠著的執行緒在指定的時間過去可進入就緒狀態。
正在等待:呼叫wait()方法。(呼叫motify()方法回到就緒狀態)
被另一個執行緒所阻塞:呼叫suspend()方法。(呼叫resume()方法恢復)
參考:
鎖機制
說說執行緒安全問題
執行緒安全是指要控制多個執行緒對某個資源的有序訪問或修改,而在這些執行緒之間沒有產生衝突。
在Java裡,執行緒安全一般體現在兩個方面:
1、多個thread對同一個java例項的訪問(read和modify)不會相互干擾,它主要體現在關鍵字synchronized。如ArrayList和Vector,HashMap和Hashtable(後者每個方法前都有synchronized關鍵字)。如果你在interator一個List物件時,其它執行緒remove一個element,問題就出現了。
2、每個執行緒都有自己的欄位,而不會在多個執行緒之間共享。它主要體現在java.lang.ThreadLocal類,而沒有Java關鍵字支援,如像static、transient那樣。
volatile 實現原理
悲觀鎖 樂觀鎖
樂觀鎖 悲觀鎖
是一種思想。可以用在很多方面。
比如資料庫方面。
悲觀鎖就是for update(鎖定查詢的行)
樂觀鎖就是 version欄位(比較跟上一次的版本號,如果一樣則更新,如果失敗則要重複讀-比較-寫的操作。)
JDK方面:
悲觀鎖就是sync
樂觀鎖就是原子類(內部使用CAS實現)
本質來說,就是悲觀鎖認為總會有人搶我的。
樂觀鎖就認為,基本沒人搶。
CAS 樂觀鎖
樂觀鎖是一種思想,即認為讀多寫少,遇到併發寫的可能性比較低,所以採取在寫時先讀出當前版本號,然後加鎖操作(比較跟上一次的版本號,如果一樣則更新),如果失敗則要重複讀-比較-寫的操作。
CAS是一種更新的原子操作,比較當前值跟傳入值是否一樣,一樣則更新,否則失敗。
CAS頂多算是樂觀鎖寫那一步操作的一種實現方式罷了,不用CAS自己加鎖也是可以的。
ABA 問題
ABA:如果另一個執行緒修改V值假設原來是A,先修改成B,再修改回成A,當前執行緒的CAS操作無法分辨當前V值是否發生過變化。
參考:
樂觀鎖的業務場景及實現方式
樂觀鎖(Optimistic Lock):
每次獲取資料的時候,都不會擔心資料被修改,所以每次獲取資料的時候都不會進行加鎖,但是在更新資料的時候需要判斷該資料是否被別人修改過。如果資料被其他執行緒修改,則不進行資料更新,如果資料沒有被其他執行緒修改,則進行資料更新。由於資料沒有進行加鎖,期間該資料可以被其他執行緒進行讀寫操作。
樂觀鎖:比較適合讀取操作比較頻繁的場景,如果出現大量的寫入操作,資料發生衝突的可能性就會增大,為了保證資料的一致性,應用層需要不斷的重新獲取資料,這樣會增加大量的查詢操作,降低了系統的吞吐量。
核心篇
資料儲存
MySQL 索引使用的注意事項
參考:
說說反模式設計
參考:
說說分庫與分表設計
分庫與分錶帶來的分散式困境與應對之策
說說 SQL 優化之道
MySQL 遇到的死鎖問題
參考:
儲存引擎的 InnoDB 與 MyISAM
1)InnoDB支援事務,MyISAM不支援,這一點是非常之重要。事務是一種高階的處理方式,如在一些列增刪改中只要哪個出錯還可以回滾還原,而MyISAM就不可以了。
2)MyISAM適合查詢以及插入為主的應用,InnoDB適合頻繁修改以及涉及到安全性較高的應用
3)InnoDB支援外來鍵,MyISAM不支援
4)從MySQL5.5.5以後,InnoDB是預設引擎
5)InnoDB不支援FULLTEXT型別的索引
6)InnoDB中不儲存表的行數,如select count() from table時,InnoDB需要掃描一遍整個表來計算有多少行,但是MyISAM只要簡單的讀出儲存好的行數即可。注意的是,當count()語句包含where條件時MyISAM也需要掃描整個表
7)對於自增長的欄位,InnoDB中必須包含只有該欄位的索引,但是在MyISAM表中可以和其他欄位一起建立聯合索引
8)清空整個表時,InnoDB是一行一行的刪除,效率非常慢。MyISAM則會重建表
9)InnoDB支援行鎖(某些情況下還是鎖整表,如 update table set a=1 where user like ‘%lee%’
參考:
資料庫索引的原理
參考:
為什麼要用 B-tree
鑑於B-tree具有良好的定位特性,其常被用於對檢索時間要求苛刻的場合,例如:
1、B-tree索引是資料庫中存取和查詢檔案(稱為記錄或鍵值)的一種方法。
2、硬碟中的結點也是B-tree結構的。與記憶體相比,硬碟必須花成倍的時間來存取一個數據元素,這是因為硬碟的機械部件讀寫資料的速度遠遠趕不上純電子媒體的記憶體。與一個結點兩個分支的二元樹相比,B-tree利用多個分支(稱為子樹)的結點,減少獲取記錄時所經歷的結點數,從而達到節省存取時間的目的。
聚集索引與非聚集索引的區別
參考:
limit 20000 載入很慢怎麼解決
LIMIT n 等價於 LIMIT 0,n
此題總結一下就是讓limit走索引去查詢,例如:order by 索引欄位,或者limit前面根where條件走索引欄位等等。
參考:
選擇合適的分散式主鍵方案
參考:
選擇合適的資料儲存方案
- 關係型資料庫 MySQL
MySQL 是一個最流行的關係型資料庫,在網際網路產品中應用比較廣泛。一般情況下,MySQL 資料庫是選擇的第一方案,基本上有 80% ~ 90% 的場景都是基於 MySQL 資料庫的。因為,需要關係型資料庫進行管理,此外,業務存在許多事務性的操作,需要保證事務的強一致性。同時,可能還存在一些複雜的 SQL 的查詢。值得注意的是,前期儘量減少表的聯合查詢,便於後期資料量增大的情況下,做資料庫的分庫分表。
- 記憶體資料庫 Redis
隨著資料量的增長,MySQL 已經滿足不了大型網際網路類應用的需求。因此,Redis 基於記憶體儲存資料,可以極大的提高查詢效能,對產品在架構上很好的補充。例如,為了提高服務端介面的訪問速度,儘可能將讀頻率高的熱點資料存放在 Redis 中。這個是非常典型的以空間換時間的策略,使用更多的記憶體換取 CPU 資源,通過增加系統的記憶體消耗,來加快程式的執行速度。
在某些場景下,可以充分的利用 Redis 的特性,大大提高效率。這些場景包括快取,會話快取,時效性,訪問頻率,計數器,社交列表,記錄使用者判定資訊,交集、並集和差集,熱門列表與排行榜,最新動態等。
使用 Redis 做快取的時候,需要考慮資料不一致與髒讀、快取更新機制、快取可用性、快取服務降級、快取穿透、快取預熱等快取使用問題。
- 文件資料庫 MongoDB
MongoDB 是對傳統關係型資料庫的補充,它非常適合高伸縮性的場景,它是可擴充套件性的表結構。基於這點,可以將預期範圍內,表結構可能會不斷擴充套件的 MySQL 表結構,通過 MongoDB 來儲存,這就可以保證表結構的擴充套件性。
此外,日誌系統資料量特別大,如果用 MongoDB 資料庫儲存這些資料,利用分片叢集支援海量資料,同時使用聚集分析和 MapReduce 的能力,是個很好的選擇。
MongoDB 還適合儲存大尺寸的資料,GridFS 儲存方案就是基於 MongoDB 的分散式檔案儲存系統。
- 列族資料庫 HBase
HBase 適合海量資料的儲存與高效能實時查詢,它是運行於 HDFS 檔案系統之上,並且作為 MapReduce 分散式處理的目標資料庫,以支撐離線分析型應用。在資料倉庫、資料集市、商業智慧等領域發揮了越來越多的作用,在數以千計的企業中支撐著大量的大資料分析場景的應用。
- 全文搜尋引擎 ElasticSearch
在一般情況下,關係型資料庫的模糊查詢,都是通過 like 的方式進行查詢。其中,like “value%” 可以使用索引,但是對於 like “%value%” 這樣的方式,執行全表查詢,這在資料量小的表,不存在效能問題,但是對於海量資料,全表掃描是非常可怕的事情。ElasticSearch 作為一個建立在全文搜尋引擎 Apache Lucene 基礎上的實時的分散式搜尋和分析引擎,適用於處理實時搜尋應用場景。此外,使用 ElasticSearch 全文搜尋引擎,還可以支援多詞條查詢、匹配度與權重、自動聯想、拼寫糾錯等高階功能。因此,可以使用 ElasticSearch 作為關係型資料庫全文搜尋的功能補充,將要進行全文搜尋的資料快取一份到 ElasticSearch 上,達到處理複雜的業務與提高查詢速度的目的。
ElasticSearch 不僅僅適用於搜尋場景,還非常適合日誌處理與分析的場景。著名的 ELK 日誌處理方案,由 ElasticSearch、Logstash 和 Kibana 三個元件組成,包括了日誌收集、聚合、多維度查詢、視覺化顯示等。
ObjectId 規則
參考:
聊聊 MongoDB 使用場景
參考:
倒排索引
參考:
聊聊 ElasticSearch 使用場景
在一般情況下,關係型資料庫的模糊查詢,都是通過 like 的方式進行查詢。其中,like “value%” 可以使用索引,但是對於 like “%value%” 這樣的方式,執行全表查詢,這在資料量小的表,不存在效能問題,但是對於海量資料,全表掃描是非常可怕的事情。ElasticSearch 作為一個建立在全文搜尋引擎 Apache Lucene 基礎上的實時的分散式搜尋和分析引擎,適用於處理實時搜尋應用場景。此外,使用 ElasticSearch 全文搜尋引擎,還可以支援多詞條查詢、匹配度與權重、自動聯想、拼寫糾錯等高階功能。因此,可以使用 ElasticSearch 作為關係型資料庫全文搜尋的功能補充,將要進行全文搜尋的資料快取一份到 ElasticSearch 上,達到處理複雜的業務與提高查詢速度的目的。
快取使用
Redis 有哪些型別
Redis支援五種資料型別:string(字串),hash(雜湊),list(列表),set(集合)及zset(sorted set:有序集合)。
Redis 內部結構
參考:
聊聊 Redis 使用場景
隨著資料量的增長,MySQL 已經滿足不了大型網際網路類應用的需求。因此,Redis 基於記憶體儲存資料,可以極大的提高查詢效能,對產品在架構上很好的補充。例如,為了提高服務端介面的訪問速度,儘可能將讀頻率高的熱點資料存放在 Redis 中。這個是非常典型的以空間換時間的策略,使用更多的記憶體換取 CPU 資源,通過增加系統的記憶體消耗,來加快程式的執行速度。
在某些場景下,可以充分的利用 Redis 的特性,大大提高效率。這些場景包括快取,會話快取,時效性,訪問頻率,計數器,社交列表,記錄使用者判定資訊,交集、並集和差集,熱門列表與排行榜,最新動態等。
使用 Redis 做快取的時候,需要考慮資料不一致與髒讀、快取更新機制、快取可用性、快取服務降級、快取穿透、快取預熱等快取使用問題。
Redis 持久化機制
參考:
Redis 如何實現持久化
參考:
Redis 叢集方案與實現
參考:
Redis 為什麼是單執行緒的
單純的網路IO來說,量大到一定程度之後,多執行緒的確有優勢——但並不是單純的多執行緒,而是每個執行緒自己有自己的epoll這樣的模型,也就是多執行緒和multiplexing混合。
一般這個開頭我們都會跟一個“但是”。
但是。
還要考慮Redis操作的物件。它操作的物件是記憶體中的資料結構。如果在多執行緒中操作,那就需要為這些物件加鎖。最終來說,多執行緒效能有提高,但是每個執行緒的效率嚴重下降了。而且程式的邏輯嚴重複雜化。
要知道Redis的資料結構並不全是簡單的Key-Value,還有列表,hash,map等等複雜的結構,這些結構有可能會進行很細粒度的操作,比如在很長的列表後面新增一個元素,在hash當中新增或者刪除一個物件,等等。這些操作還可以合成MULTI/EXEC的組。這樣一個操作中可能就需要加非常多的鎖,導致的結果是同步開銷大大增加。這還帶來一個惡果就是吞吐量雖然增大,但是響應延遲可能會增加。
Redis在權衡之後的選擇是用單執行緒,突出自己功能的靈活性。在單執行緒基礎上任何原子操作都可以幾乎無代價地實現,多麼複雜的資料結構都可以輕鬆運用,甚至可以使用Lua指令碼這樣的功能。對於多執行緒來說這需要高得多的代價。
並不是所有的KV資料庫或者記憶體資料庫都應該用單執行緒,比如ZooKeeper就是多執行緒的,最終還是看作者自己的意願和取捨。單執行緒的威力實際上非常強大,每核心效率也非常高,在今天的虛擬化環境當中可以充分利用雲化環境來提高資源利用率。多執行緒自然是可以比單執行緒有更高的效能上限,但是在今天的計算環境中,即使是單機多執行緒的上限也往往不能滿足需要了,需要進一步摸索的是多伺服器叢集化的方案,這些方案中多執行緒的技術照樣是用不上的,所以單執行緒、多程序的叢集不失為一個時髦的解決方案。
快取奔潰
參考:
快取降級
服務降級的目的,是為了防止Redis服務故障,導致資料庫跟著一起發生雪崩問題。因此,對於不重要的快取資料,可以採取服務降級策略,例如一個比較常見的做法就是,Redis出現問題,不去資料庫查詢,而是直接返回預設值給使用者。
使用快取的合理性問題
參考:
訊息佇列
訊息佇列的使用場景
主要解決應用耦合,非同步訊息,流量削鋒等問題
訊息的重發補償解決思路
參考:
訊息的冪等性解決思路
參考:
訊息的堆積解決思路
參考:
自己如何實現訊息佇列
參考:
如何保證訊息的有序性
參考:
框架篇
Spring
BeanFactory 和 ApplicationContext 有什麼區別
beanfactory顧名思義,它的核心概念就是bean工廠,用作於bean生命週期的管理,而applicationcontext這個概念就比較豐富了,單看名字(應用上下文)就能看出它包含的範圍更廣,它繼承自bean factory但不僅僅是繼承自這一個介面,還有繼承了其他的介面,所以它不僅僅有bean factory相關概念,更是一個應用系統的上下文,其設計初衷應該是一個包羅永珍的對外暴露的一個綜合的API。
Spring Bean 的生命週期
參考:
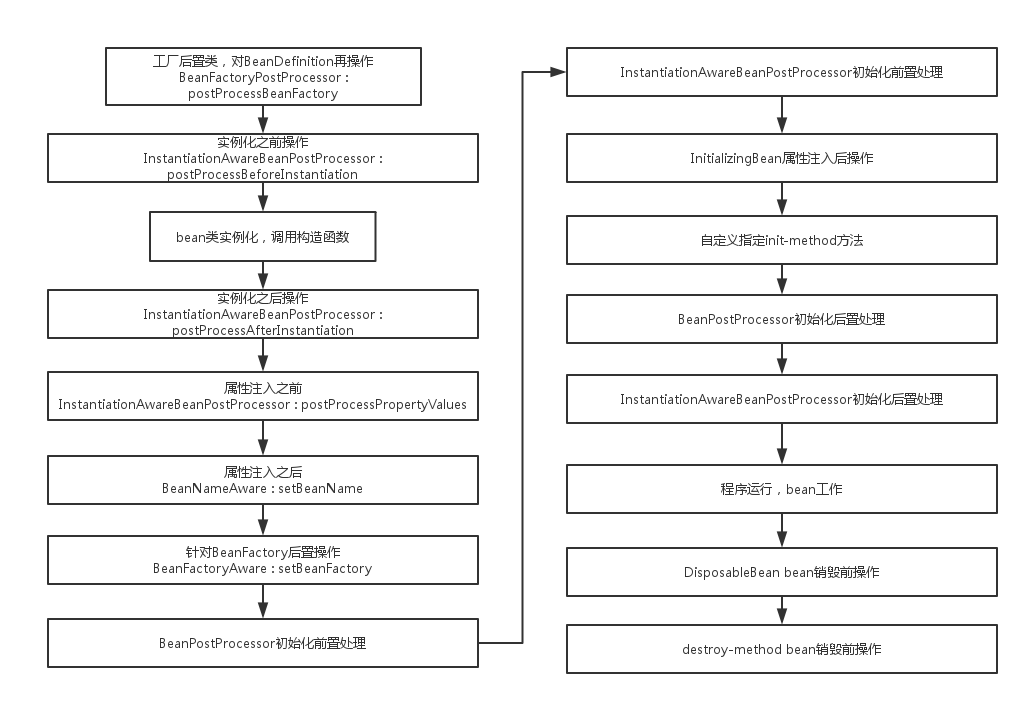
Spring IOC 如何實現
參考:
說說 Spring AOP
參考:
Spring AOP 實現原理
參考:
動態代理(cglib 與 JDK)
java動態代理是利用反射機制生成一個實現代理介面的匿名類,在呼叫具體方法前呼叫InvokeHandler來處理。
而cglib動態代理是利用asm開源包,對代理物件類的class檔案載入進來,通過修改其位元組碼生成子類來處理。
1、如果目標物件實現了介面,預設情況下會採用JDK的動態代理實現AOP
2、如果目標物件實現了介面,可以強制使用CGLIB實現AOP
3、如果目標物件沒有實現了介面,必須採用CGLIB庫,spring會自動在JDK動態代理和CGLIB之間轉換
如何強制使用CGLIB實現AOP?
(1)新增CGLIB庫,SPRING_HOME/cglib/*.jar
(2)在spring配置檔案中加入<aop:aspectj-autoproxy proxy-target-class=“true”/>
JDK動態代理和CGLIB位元組碼生成的區別?
(1)JDK動態代理只能對實現了介面的類生成代理,而不能針對類
(2)CGLIB是針對類實現代理,主要是對指定的類生成一個子類,覆蓋其中的方法
因為是繼承,所以該類或方法最好不要宣告成final
參考:
Spring 事務實現方式
參考:
Spring 事務底層原理
參考:
如何自定義註解實現功能
可以結合spring的AOP,對註解進行攔截,提取註解。
大致流程為:
- 新建一個註解@MyLog,加在需要註解申明的方法上面
- 新建一個類MyLogAspect,通過@Aspect註解使該類成為切面類。
- 通過@Pointcut 指定切入點 ,這裡指定的切入點為MyLog註解型別,也就是被@MyLog註解修飾的方法,進入該切入點。
- MyLogAspect中的方法通過加通知註解(@Before、@Around、@AfterReturning、@AfterThrowing、@After等各種通知)指定要做的業務操作。
Spring MVC 執行流程
一、先用文字描述
1.使用者傳送請求到DispatchServlet
2.DispatchServlet根據請求路徑查詢具體的Handler
3.HandlerMapping返回一個HandlerExcutionChain給DispatchServlet
HandlerExcutionChain:Handler和Interceptor集合
4.DispatchServlet呼叫HandlerAdapter介面卡
5.HandlerAdapter呼叫具體的Handler處理業務
6.Handler處理結束返回一個具體的ModelAndView給介面卡
ModelAndView:model–>資料模型,view–>檢視名稱
7.介面卡將ModelAndView給DispatchServlet
8.DispatchServlet把檢視名稱給ViewResolver檢視解析器
9.ViewResolver返回一個具體的檢視給DispatchServlet
10.渲染檢視
11.展示給使用者
二、畫圖解析
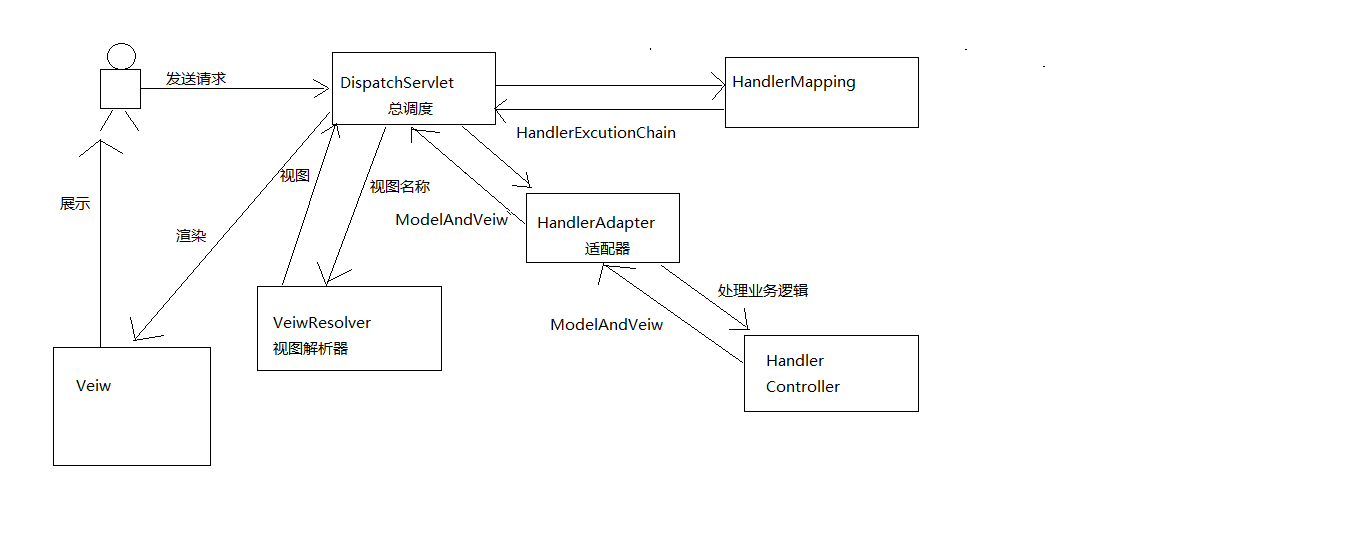
SpringMvc的配置

Spring MVC 啟動流程
參考:
Spring 的單例實現原理
參考:
Spring 框架中用到了哪些設計模式
Spring框架中使用到了大量的設計模式,下面列舉了比較有代表性的:
代理模式—在AOP和remoting中被用的比較多。
單例模式—在spring配置檔案中定義的bean預設為單例模式。
模板方法—用來解決程式碼重複的問題。比如. RestTemplate, JmsTemplate, JpaTemplate。
工廠模式—BeanFactory用來建立物件的例項。
介面卡–spring aop
裝飾器–spring data hashmapper
觀察者-- spring 時間驅動模型
回撥–Spring ResourceLoaderAware回撥介面
前端控制器–spring用前端控制器DispatcherServlet對請求進行分發
Spring 其他產品(Srping Boot、Spring Cloud、Spring Secuirity、Spring Data、Spring AMQP 等)
參考:
Netty
為什麼選擇 Netty
Netty 是業界最流行的 NIO 框架之一,它的健壯性、功能、效能、可定製性和可擴充套件性在同類框架中都是首屈一指的,它已經得到成百上千的商用專案驗證,例如 Hadoop 的 RPC 框架 Avro 使用 Netty 作為通訊框架。很多其它業界主流的 RPC 和分散式服務框架,也使用 Netty 來構建高效能的非同步通訊能力。
Netty 的優點總結如下:
- API 使用簡單,開發門檻低;
- 功能強大,預置了多種編解碼功能,支援多種主流協議;
- 定製能力強,可以通過 ChannelHandler 對通訊框架進行靈活的擴充套件;
- 效能高,通過與其它業界主流的 NIO 框架對比,Netty 的綜合性能最優;
- 社群活躍,版本迭代週期短,發現的 BUG 可以被及時修復,同時,更多的新功能會被加入;
- 經歷了大規模的商業應用考驗,質量得到驗證。在網際網路、大資料、網路遊戲、企業應用、電信軟體等眾多行業得到成功商用,證明了它完全滿足不同行業的商用標準。
正是因為這些優點,Netty 逐漸成為 Java NIO 程式設計的首選框架。
說說業務中,Netty 的使用場景
原生的 NIO 在 JDK 1.7 版本存在 epoll bug
它會導致Selector空輪詢,最終導致CPU 100%。官方聲稱在JDK1.6版本的update18修復了該問題,但是直到JDK1.7版本該問題仍舊存在,只不過該BUG發生概率降低了一些而已,它並沒有被根本解決。該BUG以及與該BUG相關的問題單可以參見以下連結內容。
異常堆疊如下:
java.lang.Thread.State: RUNNABLE
at sun.nio.ch.EPollArrayWrapper.epollWait(Native Method)
at sun.nio.ch.EPollArrayWrapper.poll(EPollArrayWrapper.java:210)
at sun.nio.ch.EPollSelectorImpl.doSelect(EPollSelectorImpl.java:65)
at sun.nio.ch.SelectorImpl.lockAndDoSelect(SelectorImpl.java:69)
- locked <0x0000000750928190> (a sun.nio.ch.Util$2)
- locked <0x00000007509281a8> (a java.util.Collections$ UnmodifiableSet)
- locked <0x0000000750946098> (a sun.nio.ch.EPollSelectorImpl)
at sun.nio.ch.SelectorImpl.select(SelectorImpl.java:80)
at net.spy.memcached.MemcachedConnection.handleIO(Memcached Connection.java:217)
at net.spy.memcached.MemcachedConnection.run(MemcachedConnection. java:836)
什麼是TCP 粘包/拆包
參考:
TCP粘包/拆包的解決辦法
參考:
Netty 執行緒模型
參考:
說說 Netty 的零拷貝
參考:
Netty 內部執行流程
參考:
Netty 重連實現
參考:
微服務篇
微服務
前後端分離是如何做的
參考:
微服務哪些框架
Spring Cloud、Dubbo、Hsf等
你怎麼理解 RPC 框架
RPC的目的是讓你在本地呼叫遠端的方法,而對你來說這個呼叫是透明的,你並不知道這個呼叫的方法是部署哪裡。通過RPC能解耦服務,這才是使用RPC的真正目的。
說說 RPC 的實現原理
參考:
說說 Dubbo 的實現原理
dubbo提供功能來講, 提供基礎功能-RPC呼叫 提供增值功能SOA服務治理
dubbo啟動時查詢可用的遠端服務提供者,呼叫介面時不是最終呼叫本地實現,而是通過攔截呼叫(又用上JDK動態代理功能)過程經過一系列的的序列化、遠端通訊、協議解析最終呼叫到遠端服務提供者
參考:
你怎麼理解 RESTful
REST是 一種軟體架構風格、設計風格,它是一種面向資源的網路化超媒體應用的架構風格。它主要是用於構建輕量級的、可維護的、可伸縮的 Web 服務。基於 REST 的服務被稱為 RESTful 服務。REST 不依賴於任何協議,但是幾乎每個 RESTful 服務使用 HTTP 作為底層協議,RESTful使用http method標識操作,例如:
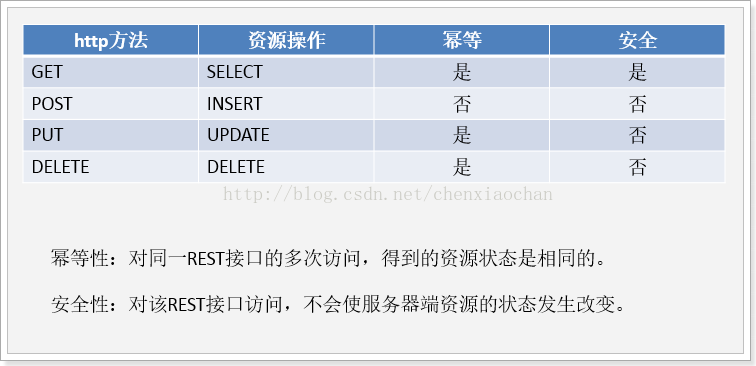
說說如何設計一個良好的 API
參考:
如何理解 RESTful API 的冪等性
參考:
如何保證介面的冪等性
參考:
說說 CAP 定理、 BASE 理論
參考:
怎麼考慮資料一致性問題
參考:
說說最終一致性的實現方案
可以結合MQ實現最終一致性,例如電商系統,把生成訂單資料的寫操作邏輯通過事務控制,一些無關緊要的業務例如日誌處理,通知,通過非同步訊息處理,最終到請求落地。
參考:
你怎麼看待微服務
- 小:微服務體積小
- 獨:能夠獨立的部署和執行。
- 輕:使用輕量級的通訊機制和架構。
- 鬆:為服務之間是鬆耦合的。
微服務與 SOA 的區別
可以把微服務當做去除了ESB的SOA。ESB是SOA架構中的中心匯流排,設計圖形應該是星形的,而微服務是去中心化的分散式軟體架構。
參考:
如何拆分服務
參考:
微服務如何進行資料庫管理
參考:
如何應對微服務的鏈式呼叫異常
參考:
對於快速追蹤與定位問題
參考:
微服務的安全
參考:
分散式
談談業務中使用分散式的場景
一、解決java叢集的session共享的解決方案:
1.客戶端cookie加密。(一般用於內網中企業級的系統中,要求使用者瀏覽器端的cookie不能禁用,禁用的話,該方案會失效)。
2.叢集中,各個應用伺服器提供了session複製的功能,tomcat和jboss都實現了這樣的功能。特點:效能隨著伺服器增加急劇下降,容易引起廣播風暴;session資料需要序列化,影響效能。
3.session的持久化,使用資料庫來儲存session。就算伺服器宕機也沒事兒,資料庫中的session照樣存在。特點:每次請求session都要讀寫資料庫,會帶來效能開銷。使用記憶體資料庫,會提高效能,但是宕機會丟失資料(像支付寶的宕機,有同城災備、異地災備)。
4.使用共享儲存來儲存session。和資料庫類似,就算宕機了也沒有事兒。其實就是專門搞一臺伺服器,全部對session落地。特點:頻繁的進行序列化和反序列化會影響效能。
5.使用memcached來儲存session。本質上是記憶體資料庫的解決方案。特點