Caffe-Windows訓練自己資料 + 遷移學習
一:目的
用配置好的Windows版本Caffe(no GPU),使用caffe自帶的ImageNet網路結構進行訓練和測試。訓練自己的資料;
用caffe團隊採用imagenet圖片進行訓練的引數結果,進行遷移學習;
二:訓練與測試
1. 資料集下載與處理
(1) 下載資料集。這裡找了一份網上的資料集,共有500張圖片,分為大巴車、恐龍、大象、鮮花和馬五個類,每個類100張。編號分別以3,4,5,6,7開頭,各為一類。我從其中每類選出20張作為測試,其餘80張作為訓練。因此最終訓練圖片400張,測試圖片100張,共5類。
其中,訓練和測試的輸入是用train.txt和val.txt描述的,這些文件列出所有檔案和他們的標籤。下載完成後,檔案的組織形式如下。
(2) 在caffe-windows\data資料夾下新建mydata資料夾,在該資料夾分別新建train和test兩個目錄,將下載資料夾中的資料拷貝其中。在這裡,我將3,4,5,6,7資料夾中的資料全部取出放到了train和test資料夾,如圖所示。
(3) 編寫指令碼檔案,在caffe-windows\data\mydata資料夾下分別生成train.txt和test.txt
import os if __name__ == "__main__": data_dir = 'E:/Caffe/using/caffe-windows/data/mydata/train/' fid = open("E:/Caffe/using/caffe-windows/data/mydata/train2.txt","w") files = os.listdir(data_dir) index = 0 for ii, file in enumerate(files,1): fid.write("{0}{1}\t{2}\n".format("train/",file, int(file[0])-3)) index = index + 1 if index%100 == 0: print("{0} images processed!".format(index)) print("All images processed!") fid.close()
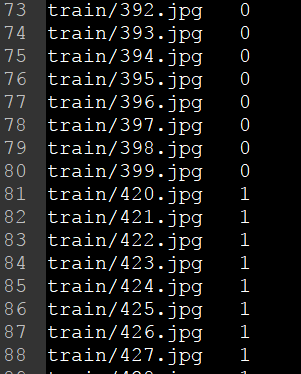
通過上述指令碼可以生成對應的train.txt和test.txt(位於caffe-windows\data\mydata資料夾下),檔案內容如下
值得注意的是,我在這裡將3,4,5,6,7分類轉成了0,1,2,3,4分類,這是為了後續train_val.prototxt的修改,這裡也可以按照3,4,5,6,7進行分類,不過後續的內容需要進行相應的調整。(4) 新建caffe-windows\mybat\mydata資料夾,在該資料夾下新建mydata_convention.bat,對資料進行轉換,內容如下
..\..\Build\x64\Release\convert_imageset.exe --resize_height=256 --resize_width=256 --shuffle --backend=leveldb ..\..\data\mydata\ ..\..\data\mydata\train.txt ..\..\data\mydata\trainldb ..\..\Build\x64\Release\convert_imageset.exe --resize_height=256 --resize_width=256 --shuffle --backend=leveldb ..\..\data\mydata\ ..\..\data\mydata\test.txt ..\..\data\mydata\valldb pause
其中,resize_height和resize_width表示將原影象resize為相應的大小,選擇256是因為我們選取的網路(ImageNet)的要求,shuffle是將資料隨機打亂的意思,backend表示將資料轉換的格式,之前文章介紹過,這裡不再介紹了。雙擊執行後,在caffe-windows\data\mydata下生成對應的trainldb和valldb
(5) 在caffe-windows\mybat\mydata資料夾下新建mydata_mean.bat,生成對應的均值檔案。..\..\Build\x64\Release\compute_image_mean ..\..\data\mydata\trainldb --backend=leveldb ..\..\data\mydata\train_mean.binaryproto ..\..\Build\x64\Release\compute_image_mean ..\..\data\mydata\valldb --backend=leveldb ..\..\data\mydata\val_mean.binaryproto pause其中backend要與步驟(4)中保持一致,執行完成後,會在caffe-windows\data\mydata資料夾下生成train_mean.binaryproto和val_mean.binaryproto檔案
2. 訓練資料
首先將caffe-windows\models\bvlc_reference_caffenet資料夾下的deploy.prototxt、solver.prototxt和train_val.prototxt拷貝到caffe-windows\data\mydata下。
(1) 訓練模型檔案(train_val.prototxt)的配置
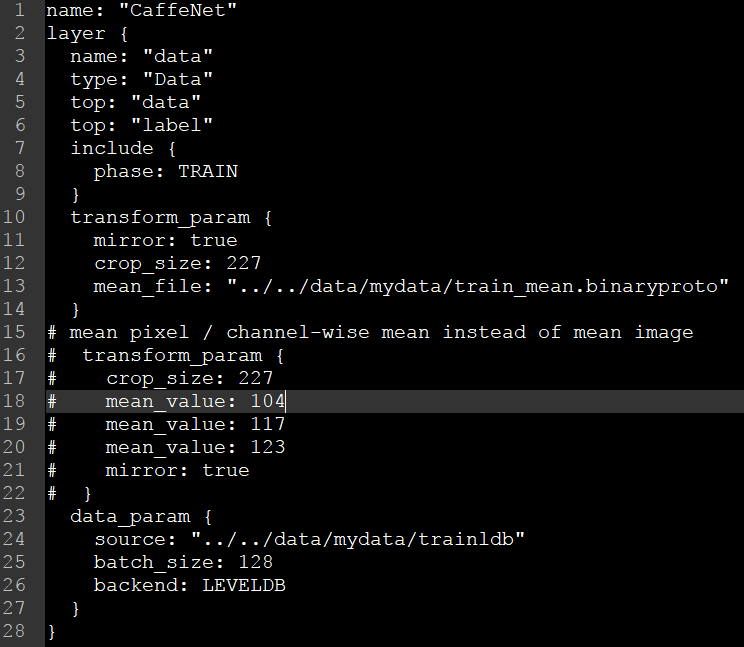
在這裡對trian檔案進行修改,主要有source,batch_size,backend和mean_file,其中batch_size這裡我設定的較小,如果計算機配置較高,可以設大一點,訓練結果會稍微好一些。
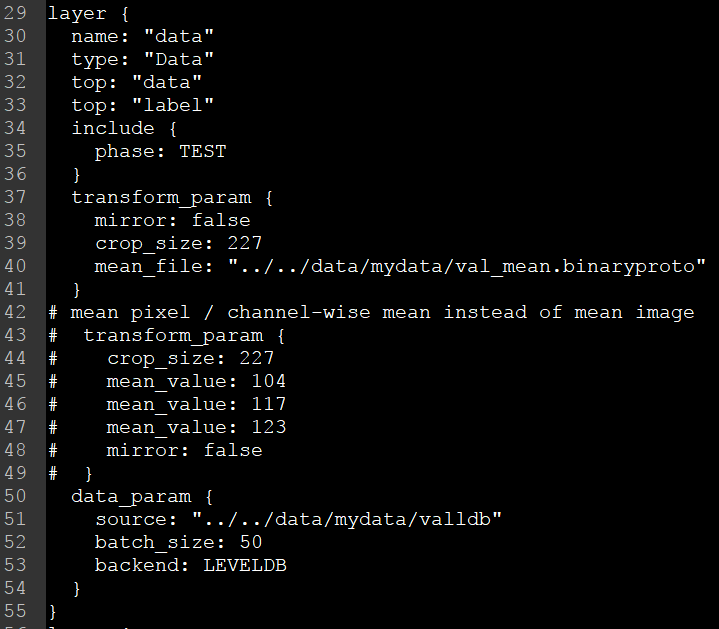
在這裡對test檔案進行修改,主要有source,batch_size,backend和mean_file。
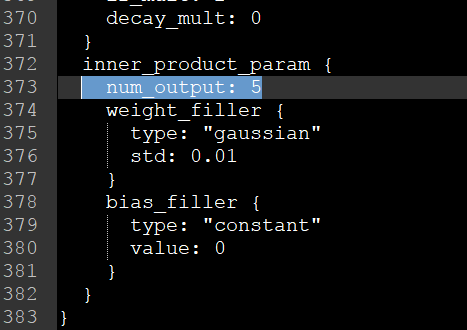
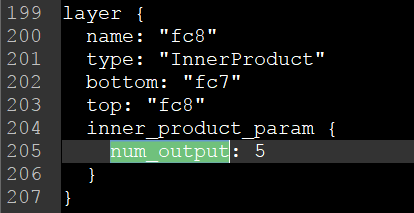
在檔案的最後,對num_output進行修改,因為我前面將其改為了0,1,2,3,4分類,所以這裡寫5就可以,因為它是從0開始計算的,所以如果保留3,4,5,6,7分類,這裡至少要為8,否則會出錯。其實這裡的1000分類也可以不進行改動,但對應需要調整的地方就是最後的label.txt。
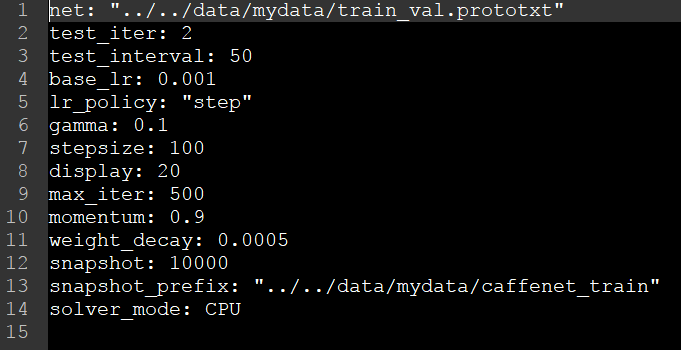
(2) 訓練引數檔案(solver.prototxt)的配置
主要修改net,snapshot_prefix和solver_mode三個引數,其餘引數的修改可以參照之前的部落格。
(3) 在 caffe-windows\mybat\mydata資料夾下新建mydata_train.bat,對資料進行訓練,內容如下
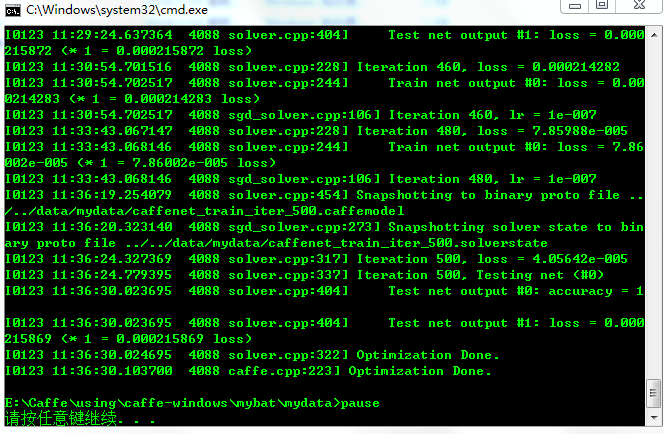
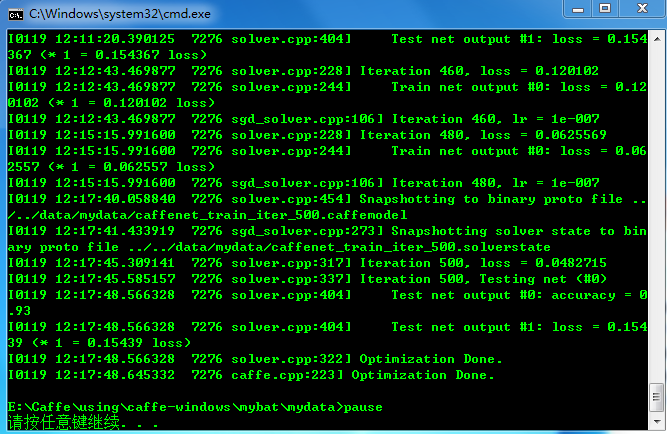
..\..\Build\x64\Release\caffe.exe train --solver=..\..\data\mydata\solver.prototxt pause雙擊執行,執行結束後結果如下
可以看到能達到93%的正確率,其實將train_val.prototxt檔案中train部分的batch_size改為256可以達到95%左右的正確率。執行結束後,在caffe-windows\data\mydata資料夾下會生成caffenet_train_iter_500.solverstate和caffenet_train_iter_500.caffemodel檔案,其中solvestate檔案是狀態恢復檔案,如果因為一些原因我們中斷了訓練,下次想從中斷的地方繼續進行訓練,可以通過--snapshot=xxx.solverstate命令進行繼續訓練。
3. 測試
(1) 修改E:\Caffe\using\caffe-windows\data\mydata\deploy.prototxt檔案,因為我們之前的num_output為5,這裡也將其改為5
(2) 在caffe-windows\data\mydata資料夾下新建labels.txt檔案,內容為以上五類目標的英文名。
(3) 在caffe-windows\mybat\mydata資料夾新建mydata_test.bat,對影象進行測試,內容如下
..\..\Build\x64\Release\classification ..\..\data\mydata\deploy.prototxt ..\..\data\mydata\caffenet_train_iter_500.caffemodel ..\..\data\mydata\val_mean.binaryproto ..\..\data\mydata\labels.txt ..\..\data\mydata\test\500.jpg pause
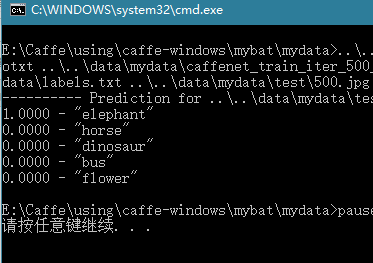
500.jpg如下
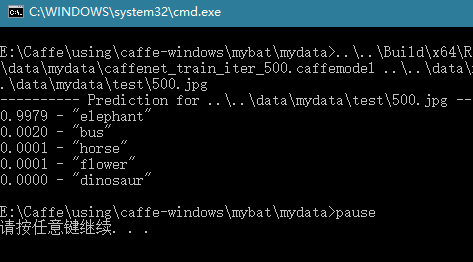
檢測結果如下:
檢測出來的也是大象,finished!


三:遷移學習
有時候我們進行訓練的影象較少,收斂速度較慢,並且有時候還難以收斂,達不到我們想要的效果。此時,可以利用別的使用者之前訓練好的資料進行fine-tuning,借用訓練好的引數,往往可以更快的收斂,達到較好的訓練效果。在這裡,我們對第二章節的訓練進行遷移學習。
(1) 下載model引數
在這裡,我們選用了一組caffe團隊用imagenet圖片進行訓練,迭代30多萬次,訓練出來的一個model。這個model將圖片分為1000類,應該是目前為止最好的圖片分類model了。
檔名稱為:bvlc_reference_caffenet.caffemodel,檔案大小為230M左右,將這個caffemodel檔案下載到caffe-windows\data\mydata資料夾下。
(2) 在caffe-windows\data\mydata資料夾下,將第二章節中用到的train_val.prototxt和solver.prototxt備份一下,分別重新命名為train_val_transform.prototxt和solver_transform.prototxt。
在train_val_transform.prototxt中,修改其fc8層為fc8_re,在solver_transform.prototxt,修改對應的train_val_transform.prototxt路徑
(3) 在caffe-windows\mybat\mydata資料夾下新建mydata_train_with_weights.bat,內容如下
..\..\Build\x64\Release\caffe.exe train --solver=..\..\data\mydata\solver_transform.prototxt --weights=..\..\data\mydata\bvlc_reference_caffenet.caffemodel pause
雙擊執行即可,可以看出來,收斂速度較快
執行結束後同樣在caffe-windows\data\mydata資料夾下生成caffenet_train_iter_500.solverstate和caffenet_train_iter_500.caffemodel檔案
準確率達到了1,也可能跟我們的測試資料不多有關係,不過準確率的確提高了不少。
(4) 測試
備份caffe-windows\data\mydata\deploy.prototxt,將備份檔案重新命名為caffe-windows\data\mydata\deploy_transform.prototxt,修改其對應的name為fc8_re
在caffe-windows\mybat\mydata資料夾下新建mydata_test_transform.bat,內容如下
..\..\Build\x64\Release\classification ..\..\data\mydata\deploy_transform.prototxt ..\..\data\mydata\caffenet_train_iter_500.caffemodel ..\..\data\mydata\val_mean.binaryproto ..\..\data\mydata\labels.txt ..\..\data\mydata\test\500.jpg pause
測試準確率更高!finished! enjoy!
參考: