
MapReduce1和YARN(MapReduce2)執行機制
在hadoop1.x中,通過設定mapred.job.tracker來決定執行mapreduce機制,如果設定為local,則使用本地的作業執行器,如果設定為主機和埠號,則這個地址被解析為一個jobtracker地址,執行器則將作業提交給jobtracker。
在hadoop2.x中,mapreduce執行在YARN上,通過mapreduce.framework.name屬性設定,local表示本地執行,classic表示經典mapreduce框架,yarn表示新的框架。
針對MapReduceAPI,由於API是面向使用者客戶端的,他決定著使用者怎麼樣寫MapReduce,和執行機制沒有關係,不同執行機制只是表示執行MapReduce
MapReduce1中執行機制
在MapReduce1中包括的實體元件有四部分:
客戶端:負責提交MapReduce作業
JobTracker:協調作業執行
TaskTracker:執行作業劃分後的任務
分散式檔案系統:用來在實體間共享作業檔案。
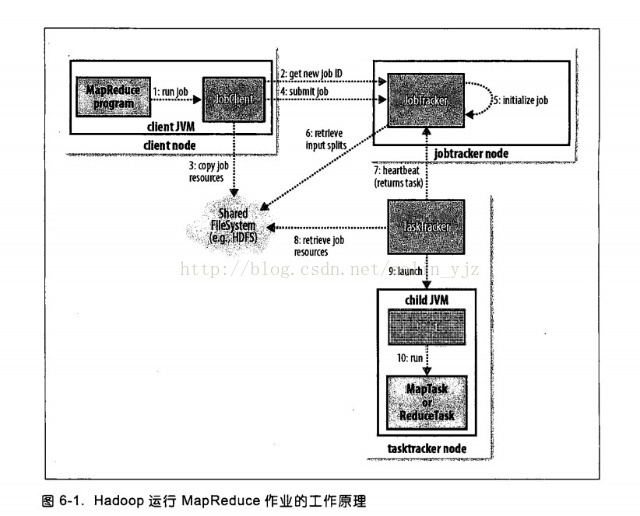
1、通過submit或者waitForCompletion提交作業,waitForCompletion()方法通過每秒迴圈輪轉作業進度,如果發現與上次報告有改變,則將進度報告發送到控制檯。其實waitForComplection()方法中還是呼叫submit()方法。
2、submit()方法中或建立一個JobSubmitter
3、將執行作業所需要的資源如JAR檔案、配置檔案、計算所得的輸入分片等複製到一個以作業ID命名的目錄下jobtracker的檔案系統(在這之前會檢查輸出說明、計算作業的輸入分片)。
4、開始告知JobTracker準備執行作業。
5、作業初始化:當jobtracker接收到JobTracker提交的submitJob()方法之後,會將這個呼叫放到一個內部序列中,交由作業排程器進行排程,並對其初始化,初始化包括一個表示正在執行的作業的物件,用來封裝任務和記錄資訊,以便跟蹤任務的轉檯和程序。
6、為了建立任務列表,jobtracker
7、tasktracker通過執行一個簡單的迴圈的來定期向jobtracker傳送“心跳”(heartbeat),以此來說明tasktracker還存活,並且通過心跳機制,來充當二者之間的資訊通道。
8、任務執行:tasktracker已經被分配一個任務,下一步開始執行這個任務,首先第一步他會從共享檔案將jar包複製到本地檔案系統,從而達到本地化。同事tasktracker會從分散式檔案系統將所需的全部檔案複製到本地磁碟。第二部是在本地為這個任務建立一個工作目錄,並把jar解壓在此處。第三部是為這個任務建立一個TaskRunner來執行該任務。
9、TaskRunner啟動一個JVM來執行每個任務(這個在圖中10)。以便map任務和reduce任務出現任何問題,都不會影響到tasktracker,但是可以重用JVM。
YARN(MapReduce2)執行機制
當叢集節點超過4000,MapReduce1面臨著瓶頸,這樣下一個MapReduce應運而生,由此,YARN(YetAnother Resource Nefotiator)也營運而生。
在MapReduce1中JobTracker負責作業排程和任務監視,追蹤任務、重啟失敗或過慢的任務和進行任務等級這麼多工作。YARN將其分為兩個獨立的守護程序:管理叢集上的資源使用的資源管理器ResourceManager(RM)和管理叢集上執行任務的生命週期的應用管理器ApplicationMaster(AM)
容器(對應MapReduce1中的任務槽)containers是將資源隔離出來的一種框架,每一個任務對應著一個container,且只能在該Container上執行。應用管理器(AM)和資源管理器(RM)協調這個計算資源containers。
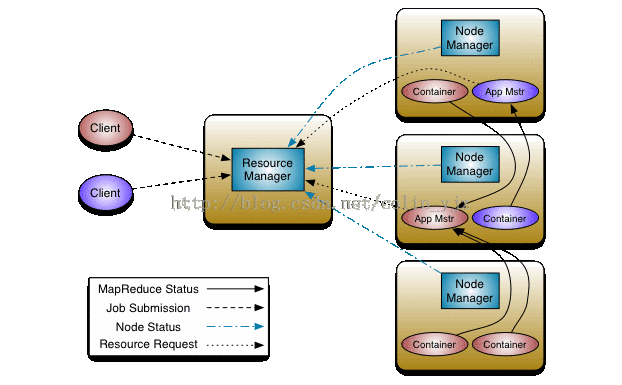
YARN提高了叢集的管理和叢集的利用率,通過YARN系統,可以執行不同的計算框架。
YARN上的實體:
Client:用來提交作業
ResourceManager:協調叢集上的計算資源的分配
NodeManager:負責啟動和監控叢集上的計算容器(container)
ApplicationMaster:協調執行MapReduce任務,他和應用程式任務執行在container中,這些congtainer有RM分配並且由NM進行管理
DFS:共享實體間的作業檔案
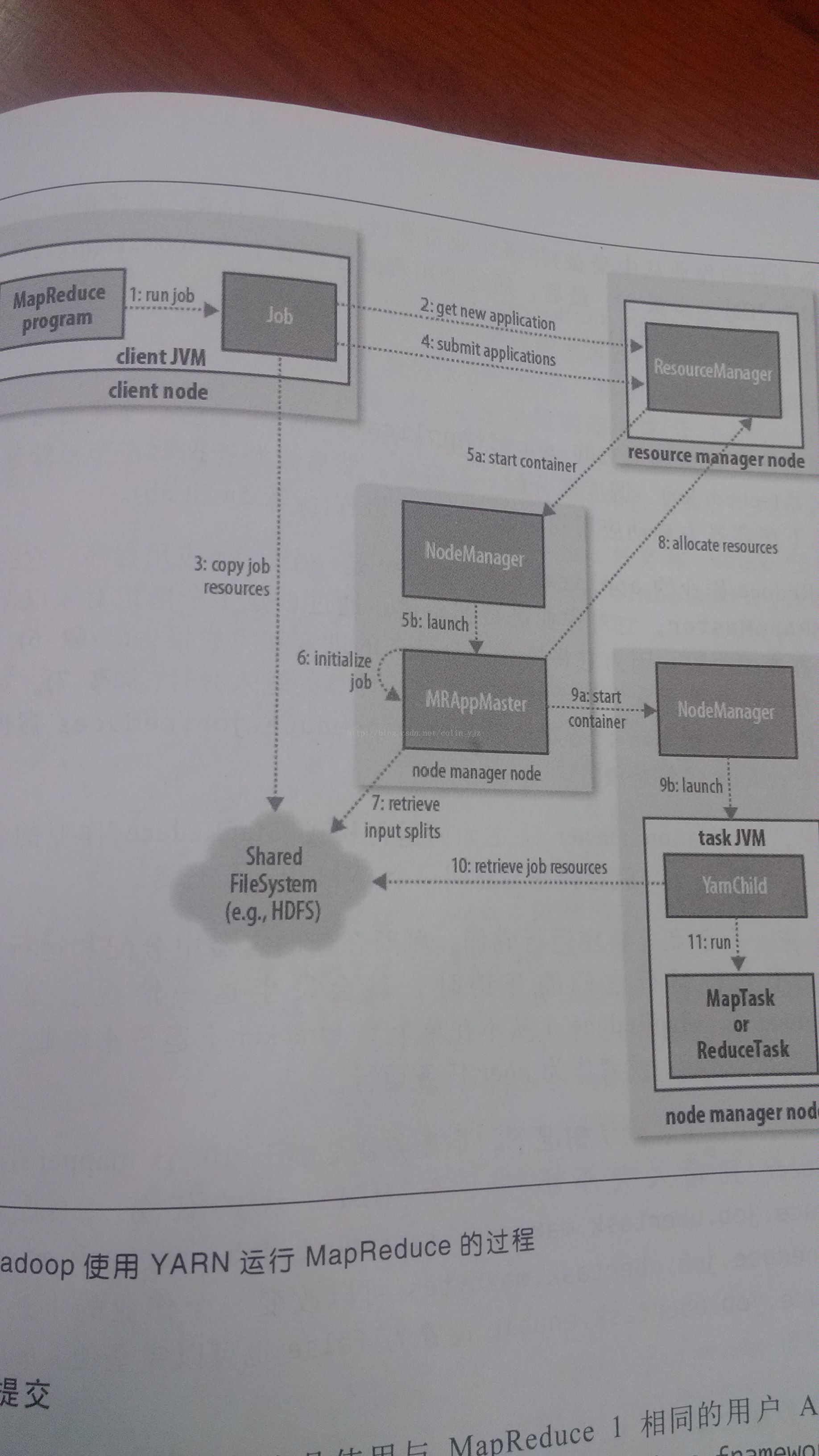
1、作業提交
通過submit或者waitForCompletion提交作業,waitForCompletion()方法通過每秒迴圈輪轉作業進度,如果發現與上次報告有改變,則將進度報告發送到控制檯。其實waitForComplection()方法中還是呼叫submit()方法。
2、從資源管理器ResourceManager獲取作業ID,在YARN中叫做應用程式ID。
3、這時候作業客戶端檢查輸出說明、計算輸入分片(可以通過yarn.app.mapreduce.am.computer-splits-in-cluster在叢集上產生分片),並將作業資訊(jar、配置檔案、分片資訊)複製到HDFS
4、通過submitApplication()方法提交作業。
5a-5b、資源管理器在收到submitApplication()訊息後,將請求傳遞給排程器(Scheduler),排程器為其分配一個容器Container,然後RM在NM的管理下在container中啟動程式的ApplicationMaster程序。
6、applicationmaster是一個java應用程式,他的主類是MRAppmaster。applicationmaster對作業進行初始化,建立過個薄記物件以跟蹤作業進度。
7、applicationmaster接受來自HDFS在客戶端計算的輸入分片,對每一個分片建立一個map任務,任務物件,由mapreduce.job.reduces屬性設定reduce個數。
uber模式
當任務小的時候就會啟動一個JVM執行MapReduce作業,這在MapReduce1中是不允許的,這樣的作業在YARN中成為uber作業,通過設定mapreduce.job.ubertask.enable設定為false使用。
那什麼是小任務呢?當小於10個mapper且只有1個reducer且輸入大小小於一個HDFS塊的任務。
但是這三個值可以重新設定:mapreduce.job.ubertask.maxmaps
8、如果作業不適合uber任務執行,applicationmaster就會為所有的map任務和reduce任務向資源管理器申請容器。請求業為任務指定記憶體需求,map任務和reduce任務的預設都會申請1024MB的記憶體,這個值可以通過mapreduce.map.memory.mb和mapreduce.reduce.memory.mb來設定。這裡的記憶體分配策略和mapreduce1中不同,在MR1中tasktracker中有固定數量的槽,每個任務執行在一個槽中,槽有最大記憶體分配限制,這樣叢集是固定的,當任務使用較少記憶體時,無法充分是喲歐諾個記憶體,造成其他任務不能夠獲取足夠記憶體因而導致作業失敗。在YARN中,資源分為更細的粒度,所以避免了以上的問題。應用程式可以申請最小到最大記憶體限制的任意最小值的倍數的記憶體容量。預設值是1024~10240,可以通過yarn.scheduler.capacity.minimum-allocation-mb和yarn.scheduler.capacity.maximum-allocation.mb設定。任務可以通過設定mapreduce.map.memory.mb和mapreduce.reduce.memory.mb來請求1GB到10GB的任意1GB的整數倍的記憶體容量。
9a~9b、資源管理器為任務分配了容器,applicationmaster就通過節點管理器啟動容器。該任務由主類YarnChild的java應用程式執行。
10、執行任務之前,首先將資源本地化,包括作業配置、jar檔案和所有來自分散式快取的檔案
11、最後執行map任務和reduce任務