
ppython3 關於agg函式的用法(一般與groupby函式連用)
阿新 • • 發佈:2019-01-26
為了瞭解agg這個函式 我們先以下資料集作為研究物件 (截圖的一部分)
agg:這裡一般都與groupby函式作為比較
pandas引入了agg函式,它提供基於列的聚合操作。而groupby可以看做是基於行,或者說index的聚合操作
通過這裡介紹我們可以交接 groupby函式是基於行操作的 而agg是基於列操作的
這個說可能太抽象,什麼是行操作 什麼是列操作呢
最簡單的理解就是 基於行操作 我可以進行分類(比如一個班名單 所有180以上的是一組 160-180是一組 低於160是一組)如果實現這個過程 我們是每一行每一行就行查詢,檢視符合什麼條件 然後分組。這就是groupby函式最簡單的理解 而我們分好組以後 想得到每一組的平均值咋辦 一般我們是著用操作的 選擇一個組之後 把他們所有身高都加起來 然後除以該組人數。那麼問題來了 不管是身高和還是平均值 我們都是進行列操作的 即我們是從上至下加起來的 而不是從左到右。為了計算簡便 我們引入了agg函式。

import pandas as pd import numpy as np path_df_part_1 = r'C:\Users\yang\Desktop\ceshi.csv' #時間11.22-11.27的資料 path_df = open(path_df_part_1, 'r') try: df_part_1 = pd.read_csv(path_df, index_col = False, parse_dates = [0]) df_part_1.columns = ['user_id','item_id','behavior_type','item_category'] finally: path_df.close() df_part_1['cumcount'] = df_part_1.groupby(['user_id', 'behavior_type']).cumcount()# df_part_1_u_b_count_in_6 = df_part_1.drop_duplicates(['user_id','behavior_type'], 'last') #相當於儲存的最大的那個計數的 因為 0 1 2 3 4 5 6 這些計數前面都是重複的 保留最後一個即可。drop_duplicate函式括號裡面的完全重複才算重複項 #完全重複就代表 user_id 與 behavior_type 完全相同 然後保留last最後u一個項 df_part_1_u_b_count_in_6 = pd.get_dummies(df_part_1_u_b_count_in_6['behavior_type']).join(df_part_1_u_b_count_in_6[['user_id','cumcount']]) #把1 2 3 4型別的進行熱編碼 變成0001 0010 0100 1000型別 df_part_1_u_b_count_in_6.rename(columns = {1:'behavior_type_1', 2:'behavior_type_2', 3:'behavior_type_3', 4:'behavior_type_4'}, inplace=True) #只是對熱編碼的columns重新命名 便於以後取值 因為分成了單獨的列了print(df_part_1) df_part_1_u_b_count_in_6['u_b1_count_in_6'] = df_part_1_u_b_count_in_6['behavior_type_1'] * (df_part_1_u_b_count_in_6['cumcount']+1)#統計使用者點選操作總數 df_part_1_u_b_count_in_6['u_b2_count_in_6'] = df_part_1_u_b_count_in_6['behavior_type_2'] * (df_part_1_u_b_count_in_6['cumcount']+1)#統計使用者收藏操作總數 df_part_1_u_b_count_in_6['u_b3_count_in_6'] = df_part_1_u_b_count_in_6['behavior_type_3'] * (df_part_1_u_b_count_in_6['cumcount']+1)#統計使用者購物車操作總數 df_part_1_u_b_count_in_6['u_b4_count_in_6'] = df_part_1_u_b_count_in_6['behavior_type_4'] * (df_part_1_u_b_count_in_6['cumcount']+1)#統計使用者購買操作總數 ★print(df_part_1_u_b_count_in_6) df_part_1_u_b_count_in_6 = df_part_1_u_b_count_in_6.groupby('user_id').agg({'u_b1_count_in_6': np.sum, 'u_b2_count_in_6': np.sum, 'u_b3_count_in_6': np.sum, 'u_b4_count_in_6': np.sum}) ★ print(df_part_1_u_b_count_in_6)
為了更容易看懂程式 我們做了標記 第一個五角星輸出的是剛開始我們給的資料圖
第二個五角星輸出如下
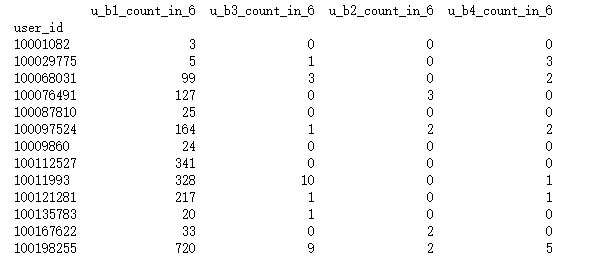
通過對比可以發現 以前 0 1 2 3資料的值 都統計在一個數據裡面了