
Linux bash總結(二) 高階部分(適合初學者學習和非初學者參考)
| 版本號 | 說明 | 作者 | 日期 |
| 1.0 | 新增awk和sed的說明 | Sky Wang | 2013/05/31 |
| 1.1 | (01) 新增正則表示式(第3部分) (02) 修改awk中錯誤內容 | Sky Wang | 2013/06/05 |
本文主要通過例項對bash中需要用到的一些高階工具(如awk、sed、...)進行說明。學習的時候,請以“應用例項”為中心,以其它內容為參考進行學習。如果遇到文章中未講解的內容,可以通過man去查閱用法。
第一部分 awk工具
本章主要通過awk的一些應用例項,來說明awk的相關語法。這樣,更利於我們進行理解;所以,閱讀本章時,請以“應用例項”為中心進行閱讀,其它部分是參考內容。
1 awk介紹
awk是一種用於處理文字的程式語言工具。awk本身就是linux下的一個工具,既可以單獨使用,也可以嵌入到bash中。
awk語言的最基本功能是在檔案或字串中基於指定規則瀏覽和抽取資訊。 awk抽取資訊後,才能進行其他文字操作。完整的 awk指令碼通常用來格式化文字檔案中的資訊。
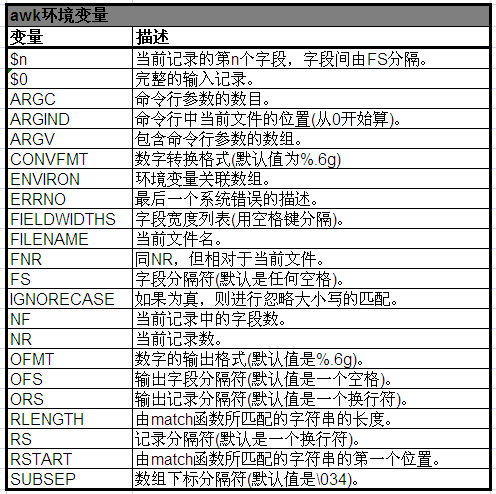
2 awk環境變數
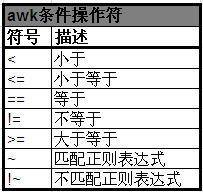
3 awk條件操作符
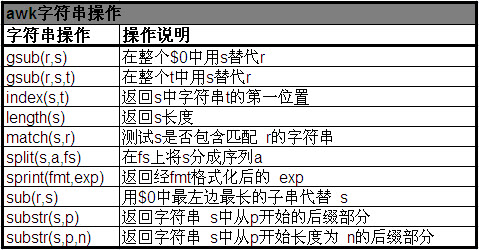
4 awk字串操作
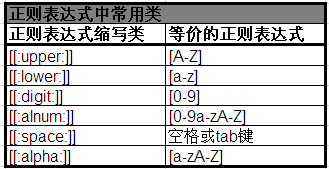
5 正則表示式中常用類
6 awk應用例項
首先建立一個123.txt,新增任意文字,然後進行以下練習。
(01), 輸出檔案全部文字
$ awk '{print $0}' 123.txt
說明:
{}:表示一段awk命令。
print:輸出指令。
$0:當前行的全部文字。
awk工具操作檔案時,是以行為單位,逐步對每行進行操作。拿本例來說{print $0},意味著“對每一行都執行print $0操作,即輸出每一行的全部文字”。
$N:當N>1時,$N表示當前行的第N段;每一行中以FS(預設值是空格)來分段。
(02), 輸出"ls -l"中每行的field1、field9
$ ls -l | awk '{printf("%s %s\n", $1, $9)}'
說明:
|:管道符號。表示將“前面指令的輸出”作為“後面指令的輸入”,即將“ls -l”的輸出作為“awk”的輸入。
printf:輸出指令。它的使用方法和C語言中printf的使用方法一樣。
$1:該行的第1段。
$9:該行的第9端。
(03), 在上一題的基礎上新增功能:第一,輸出每一行的行號和該行所包括的域的總數。第二,第1行和最後一行輸出提示語
$ ls -l | awk 'BEGIN{printf("----begin----\n")} {printf("Line-%3d Field-%d : %s %s\n", NR, NF, $1, $9)} END{printf("----end----\n")}'
說明:
BEGIN:表示在文字進行操作之前進行的工作。
END:表示在對文字的所有行都處理完畢之後前進行的工作。
在awk中,請儘量使用{}來進行區分指令段,{}可以巢狀使用!這樣做的好處寫出的指令碼不容易出錯,而且可讀性更強!
(04), 輸出"ls -l"中檔案(夾)名字包括數字的完整資訊
$ ls -l | awk '{if($9 ~ /[[:digit:]]/) {print $0}}'
說明:
$9 ~ /[[:digit:]]/ : 表示能夠匹配數字的“第一行的第9段”。
(05), 輸出"ls -l"中非資料夾的完整資訊
$ ls -l | awk '{if($1 !~ /^d/) {print $0}}'
說明:
^d : 以d開頭的。^表示起始位。此外,$表示結束位。如d$,表示以d結尾的。
(06), 找到"ls -l"中檔案(夾)名字的長度大於10的行,然後輸出其完整資訊。
$ ls -l | awk '{if(length($9) > 10) {print $0}}'
(07), 如何給文字的每一行新增行號?
$ awk '{printf("%03d %s\n",NR, $0)}' ori.txt > dst.txt
(08), 列印欄位數大於3的行的總數
$ awk 'BEGIN{COUNT=0}; {if(NF>3) COUNT++}; END{printf("COUNT=%d\n", COUNT)}' ori.txt
(09), 將文字中的各行合併一行,中間用“|”分割
$ awk 'BEGIN{ORS="|"}{print $0 }END{print "\n"}' ori.txt > dst.txt
說明:
ORS:表示記錄分割符,每條記錄表示每行。ORS預設值為換行符。
(10), 將文字中空格換成換行符
$ awk 'BEGIN{FS=" ";OFS="\n"}{print $1 }END{print "\n"}' ori.txt > dst.txt
(11), 將3行合併成一行,並輸入行號
$ awk 'BEGIN{ORS="";i=0}{ j=1; while(j<=NF){ if(i%3==0){printf("%02d ",i/3+1)}; printf("%s ",$j); i++; j++; if(i%3==0){print "\n"} }} END{print "\n"}' ori.txt > dst.txt
第二部分 sed工具
和awk一樣,本章主要通過例項對sed進行介紹。這樣,更利於我們進行理解;所以,閱讀本章時,請以“應用例項”為中心進行閱讀,其它部分是參考內容。
1 sed介紹
sed是一個非互動性文字流編輯器。和awk一樣,它是個獨立的工具,當然也可以和bash聯合使用。
它可以隨意編輯檔案或標準輸入,對它們進行編輯、刪除。它能一次性處理所有改變,對使用者來講,十分高效。sed編輯檔案或標準輸入時,編輯的是它們的拷貝;也就是說,不會改變原始的檔案。若需要儲存修改,可以通過重定向操作符>>、>>>,或者在利用sed的寫入引數。
2 基本格式
sed [選項] 輸入檔案
-n 不列印;sed不寫編輯行到標準輸出,預設為列印所有行(編輯和未編輯)。
-p 命令可以用來列印編輯行。
-c 下一命令是編輯命令。使用多項編輯時加入此選項。如果只用到一條 sed命令,此選項無用,但指定它也沒有關係。
-e 追加執行指令碼
-f 如果正在呼叫 sed指令碼檔案,使用此選項。
3 使用sed在檔案中定位文字的方式
如下表:

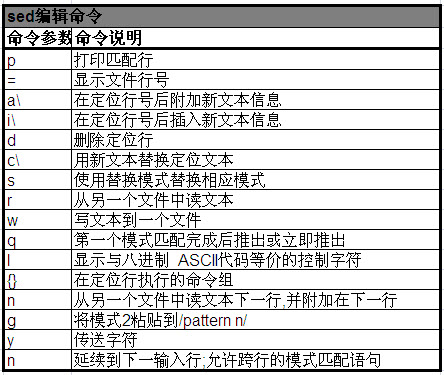
4 sed編輯命令
如下表:
5 應用例項
首先建立一個123.txt,新增任意文字,然後進行以下練習。
(01), 輸出檔案第5行
$ sed -n '5p' 123.txt
說明:
-n表示預設不輸出任何內容。5p表示輸出第5行:5表示第5行,p表示輸出。
(02), 輸出檔案除1-3行之外的行
$ sed -n '1,3!p' 123.txt
說明:
"1,3"表示輸出範圍是第1-3行; "1,3!"表示輸出範圍是除第1-3行之外。
'1,$p'表示輸出全部行,因為$表示最後一行。
(03), 輸出"ls -l"結果中的第1-3行
$ ls -l |sed -n '1,3p'
說明:
|是管道符號,表示將ls -l的輸出作為sed的輸入。
(04), 輸出匹配“the”的行
$ sed -n '/the/p' 123.txt
說明:
/the/表示匹配the的行
(05), 輸出匹配“the”的行,並且輸出每行行號
$ sed -n -e '/the/p' -e '/the/=' 123.txt
說明:
-e表示對每行進行多重編輯,多重編輯的每一個命令前都需要新增-e。
本例中,-e '/the/p'列印匹配the的行;-e '/the/='表示輸出匹配the的行的行號。
(06), 刪除匹配“the”的行
$ sed '/the/d' 123.txt
說明:
d表示刪除。
(07), 刪除匹配“the”的行;然後輸出刪除操作之後的所有行,並輸出每行行號
$ sed '/the/d' 123.txt | sed -n -e '1,$p' -e '1,$='
說明:
sed '/the/d' 123.txt :得到了刪除“the”之後的行
| :管道符號。意味著前面的輸出作為後面的輸入
sed -n -e '1,$p' -e '1,$=' :表示輸出全部行之後,在輸出每行行號
(08), 在每一行前面插入2行文字,第一行是line1,第2行是line2
$ sed '1,$iline1\nline2' 123.txt
說明:
1,$i表示第一行到最後一行的每一行都執行插入操作。
line1\nline2表示插入的文字,其中\n轉義之後表示“換行”符號。
(09), 在最後一行後面插入1行文字,內容是end
$ sed '$aend' 123.txt
說明:
$表示最後一行,a表示在文字後插入,end是插入的內容
(10), 將“this”全部替換成“that”
$ sed 's/this/that/g' 123.txt
說明:
[ address[,address ] ] s / pattern-to-find / replacement-pattern/[gpwn]
s 表示替換操作。查詢pattern-to-find,成功後用replacement-pattern替換它。
替換選項如下:
g 預設情況下只替換每行的第一次匹配,g表示替換每行的所有匹配。
p 預設sed將所有被替換行寫入標準輸出,加p選項將使-n選項無效。-n選項不列印輸出結果。
w 後接“檔名”,表示將輸出定向到一個檔案。
(11), 將“this”全部替換成“this boy”
$ sed 's/this/this boy/g' 123.txt 或 $ sed 's/this/boy &/g' 123.txt
說明:
sed 's/this/boy &/pg' 123.txt中&表示附加修改(即在原始內容的基礎上新增內容)。
&表示匹配的內容。即,boy &等價於boy this
(12), 去掉空白行後另存檔案
$ sed '/^$/d' 123.txt > 456.txt 或 $ sed '/^$/c\' 123.txt > 456.txt
說明:
/^$/表示空白行:^表示開啟,$表示結尾,開始和結尾之間沒有任何內容,即是空白行。
c\表示修改。
(13), 去掉副檔名
$ echo "hello.txt"| sed 's/.txt//g'
(14), 新增副檔名
$ echo "hello"| sed 's/$/.txt/g'
(15), 刪除文字中每一行的第2個字元
$ sed 's/.//2' ori.txt > dst.txt
(16), 刪除文字中每一行的倒數第2個字元
$ sed 's/\(.\)\(.\)$/\2/' ori.txt > dst.txt
#說明:考察了sed中"\( \)"的含義和用法
(17), 刪除每一行的第2個單詞
$ sed 's/\([[:alpha:]]\+\)\(\ \)\([[:alpha:]]\+\)*/\1/' ori.txt > dst.txt
(18), 隔行刪除
$ sed '0~2 d' ori.txt > dst.txt
第三部分 正則表示式和grep
本章主要通過一些應用例項,來對正則表示式進行說明。
1 正則表示式
正則表示式就是字串的表示式。它能通過具有意義的特殊符號表示一列或多列字串。
grep是linux系統下常用的正則表示式工具,可以使用grep來檢索文字等輸入流的字串。
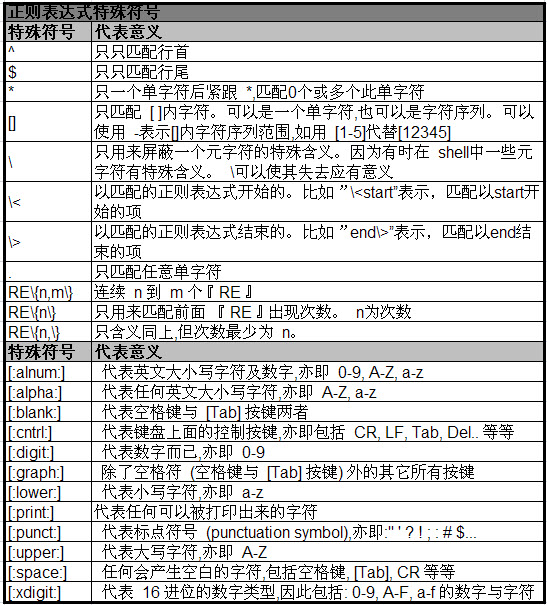
2 正則表示式特殊符號
參考下面表格
3 grep表示式
基本格式
grep [OPTIONS] PATTERN [FILE...]
格式說明
PATTERN : 匹配模式。可以是字串,也可以是正則表示式。
[FILE...] : 是grep搜尋的檔案(集)
[OPTIONS] : 是grep的選項。常用的選項有以下選項。
-c : 只輸出匹配行的計數。
-I : 不區分大 小寫(只適用於單字元)。
-h : 查詢多檔案時不顯示檔名。
-l : 查詢多檔案時只輸出包含匹配字元的檔名。
-n : 顯示匹配行及 行號。
-s : 不顯示不存在或無匹配文字的錯誤資訊。
-v : 顯示不包含匹配文字的所有行。
-r : 當FILE中包含資料夾名時,遍歷該資料夾的所有子目錄;預設情況下,不會遍歷子目錄。
4 應用例項
下面以input.txt為例,對grep進行說明。input.txt的文字內容如下:

"Open Source" is a good mechanism to develop programs. apple is my favorite food. Football game is not use feet only. this dress doesn't fit me. However, this dress is about $ 3183 dollars.^M GNU is free air not free beer.^M Her hair is very beauty.^M I can't finish the test.^M Oh! The soup taste good.^M motorcycle is cheap than car. This window is clear. the symbol '*' is represented as start. Oh! My god! The gd software is a library for drafting programs.^M You are the best is mean you are the no. 1. The world <Happy> is the same with "glad". I like dog. google is the best tools for search keyword. goooooogle yes! go! go! Let's go
(01), 查詢包含“the”的行,並顯示行號。
$ grep -n "the" input.txt
說明:-n表示顯示“行號”
(02), 不區分大小寫,查詢包括“the”的行,並顯示行號。
$ grep -in "the" input.txt
說明:-n表示顯示“行號”;-i表示不區分大小寫,即ignore大小寫。
(03), 查詢不包括“the”的行,統計行數。
$ grep -cv "the" input.txt
說明:-c表示統計(count);-v表示不匹配的項。
(04), 查詢“當前目錄”及其“所有子目錄”中包含“the”的檔案,並顯示“the”在其中的行號。
$ grep -rn "the" .
說明:-r表示遞迴查詢;-n表示顯示行號。
(05), 查詢匹配“t?st”的項,其中?為任意字元。
$ grep -n "t.st" input.txt
說明:.表示匹配任意字元
(06), 查詢包含數字的行
$ grep -n "[0-9]" input.txt 或 $ grep -n "[[:digit:]]" input.txt
說明:[0-9]表示0-9之間的一個數字;[[:digit:]]也表示0-9之間的一個數字
(07), 查詢以the開頭的行
$ grep -n "^the" input.txt
說明:"^the"表示以the開頭
(08), 查詢以小寫字母結尾的行。
$ grep -n "[a-z]$" input.txt
說明:[a-z]表示一個小寫字母,$表示結束符;[a-z]$表示以小寫字母結束的項。
(09), 查詢空白行。
$ grep -n "^$" input.txt
說明:^表示開頭,如^t表示以字母t開頭;$表示結尾,如e$表示以e結尾。^$表示空白行。
(10), 查詢以字母g開頭的單詞
$ grep -n "\<g" input.txt
說明:\<表示單詞的開始,\<g表示以g開始的單詞。
(11), 查詢字串為go的單詞。注意:不能包括goo,good等字串
$ grep -n "\<go\>" input.txt
說明:\<表示單詞的開始,\>表示單詞結尾。\<go\>表示以字母g開頭,以字母o結尾。
(12), 查詢包括2-5個字母o的行。
$
相關推薦
Linux bash總結(二) 高階部分(適合初學者學習和非初學者參考)
版本號說明作者日期 1.0 新增awk和sed的說明 Sky Wang2013/05/31 1.1 (01) 新增正則表示式(第3部分)(02) 修改awk中錯誤內容 Sky Wang 2013/06/05 本文主要通過例項對bash中需要用到的一些高階工具(如awk、se
Linux bash總結(一) 基礎部分(適合初學者學習和非初學者參考)
歡迎使用Markdown編輯器
你好! 這是你第一次使用 Markdown編輯器 所展示的歡迎頁。如果你想學習如何使用Markdown編輯器, 可以仔細閱讀這篇文章,瞭解一下Markdown的基本語法知識。
新的改變
我們對Markdown編輯器進行了一些功能
linux命令總結(二)
一. vi 命令總結
vi +n filename :開啟檔案,並將游標置於第n行首
[[email protected] /]# vi +2 aaa.txt
hello world !!
hello zhengwei!! 游標在第二行,預設是第一行
t
java基礎總結(二十六)--例項化順序和載入順序總結
首先載入:載入順序:1.靜態屬性定義 2.靜態方法宣告 (定義和宣告完全結束後) 3. 靜態屬性賦值 4.靜態塊
其次例項化:例項化順序:1.普通屬性定義、2. 普通方法宣告 (定義和宣告完全結束後)3.普通屬性
遷移 Linux 系統,第 1 部分 如何遷移備份和裸機恢復 Linux 系統
當硬體升級,更換儲存裝置或是遇到硬體故障時,需要遷移原來的作業系統及應用軟體到新的硬體裝置上。這個過程包含系統的遷移備份和裸機恢復,本文詳細描述了整個過程的細節。
災
難恢復 ,
指自然或人為災害後,重新啟用資訊系統的資料、硬體及軟體裝置,恢復正常商業運作的過程。災難恢復是
利用二叉鏈表遞歸和非遞歸算法求葉子結點的數量
pop 有時 非遞歸算法 https 我的博客 tno 測試用例 節點 == 這是我的博客的第一篇文章,是學校裏布置的一道作業題。
之後有時間的話我會發布更多有意思的博客
#include<iostream>#include<stack>usin
【演算法】二叉樹的遞迴和非遞迴遍歷(轉)
原文地址
【寫在前面】
二叉樹是一種非常重要的資料結構,很多其它資料結構都是基於二叉樹的基礎演變而來的。對於二叉樹,有前序、中序以及後序三種遍歷方法。因為樹的定義本身就 是遞迴定義,因此採用遞迴的方法去實現樹的三種遍歷不僅容易理解而且程式碼很簡潔。而對於樹的遍歷若採用非遞迴的方法,就要採
c++二叉樹的遞迴和非遞迴的前序中序和後序遍歷以及層序遍歷
二叉樹的遞迴版的前序,中序和後序遍歷很簡單也很容易理解,這裡就放一個前序遍歷的例子
//前序遍歷遞迴演算法,遞迴演算法都大同小異,這裡就不一一列舉了
void binaryTree::pro_order(NodeStack::Node *t) {
NodeStack::Node *h = t;
求二叉樹深度 -- 遞迴和非遞迴實現
/*求二叉樹深度 -- 採用遞迴和非遞迴方法
**經除錯可執行原始碼及分析如下:
*/
#include <stdio.h>
#include <stdlib.h>
#inclu
二叉樹的遞迴和非遞迴遍歷
二叉樹的遍歷
前序遍歷:
遍歷順序:根節點,左子樹,右子樹
遞迴遍歷:訪問根節點,遞迴呼叫再訪問左子樹,右子樹
//前序遍歷
void PrevOrder()
{
二叉樹的遞迴和非遞迴方式的三種遍歷
二叉樹的三種遍歷方式,前序遍歷,中序遍歷,後序遍歷,中的前中後都是指的是根節點的訪問順序,這三種遍歷方式的概念在這裡就不多說了,太普遍了!
二叉樹的建立
我們這裡以前序遍歷為例:
我們先定義好結構體
struct Tree{
Tr
java版 二叉樹 所有遞迴和非遞迴遍歷演算法
通過陣列構造二叉樹,所有遍歷演算法以及求二叉樹深度的遞迴演算法import java.util.LinkedList;
public class BinaryTree {
//根節點
private Node<Integer> root;
//二
Linux命令總結(部分說明)
linux命令總結(部分說明) 1、登陸和開關機 關機 halt poweroff init 0 重啟 reboot init 6 shutdown shutdown -r 重啟 shutodwn -h 關機
linux知識總結(二)
知識總結 zhang 小括號 ted 小s etc 查看權限 不同的 rmi linux知識總結(二)
目錄:
1.知識總結圖
2.一些較為模糊命令的回顧
3.正則表達式與擴展正則表達式
一.知識總結圖
二. 模糊命令回顧
1.chown
chown 可以改變文件的所
Linux學習總結(二十七)任務計劃,系統服務管理
crontab chkconfig systemctl unit target 1 任務計劃
說白了就是運行命令或者腳本的一個定時器,他可以讓我們在休息時間自動給我們執行任相關任務。來看下它的配置文件:cat /etc/crontab第一行定義了 shell環境第二行定義 環境變量第三行定
Linux Bash Shell學習(十二) 流程控制——select
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow
也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
《5.linux驅動開發-第3部分-5.3.字元裝置驅動高階》
《5.linux驅動開發-第3部分-5.3.字元裝置驅動高階》
第一部分、章節目錄 5.3.1.註冊字元裝置驅動新介面1 5.3.2.註冊字元裝置驅動新介面2 5.3.3.註冊字元裝置驅動新介面3 5.3.4.註冊字元裝置驅動新介面4 5.3.5.字元裝置驅動註冊程式碼分析1 5.3.6
Linux bash篇(二 操作環境)
1.命令執行的順序
(1).相對/絕對路徑
(2).由alias找到的命令
(3).由bash內建的命令
(4).通過$PATH變數找到的第一個命令
2.第一篇講到的bash在登出後就會無效,如果想保留需要寫在配製檔案裡面
3.取得bash有兩種方式,登入和不
(二)裝置結構模型_高階部分(Bus、Class、Device、Driver)
高階部分(Bus、Class、Device、Driver)
深入,並且廣泛
-沉默犀牛
這篇文章只分析Bus、Class的作用,和表示它們的結構體。不分析介面函式
Bus
Bus是處理器與一個或者多個device之間的通道。在裝置模型中,所有的devi
linux常用命令總結二(chown/sed/echo/ls/vim/scp/awk)
####chown
通過chmod可以修改一個檔案的許可權,也可以修改檔案所有者及使用者組。chown是change owner 的縮寫。chown -R用來同時修改目錄下的子目錄和檔案(-R表示遞迴)。
建立使用者
useradd changhf
passwd