
STL MAP及字典樹在關鍵字統計中的效能分析
轉載請註明出處:http://blog.csdn.net/mxway/article/details/21321541
在搜尋引擎在通常會對關鍵字出現的次數進行統計,這篇文章分析下使用C++ STL中的map進行統計,及使用字典樹進行統計在執行速度,空間及適用場合進行分析。首先隨機生成100萬個3-6長度的字串。為了簡化問題,字串中僅由小寫字母組成。另外隨機生成10萬個長度3-8的字串用於測試map和字典樹在查詢方面的效率。
下面是使用map和字典樹實現的C++程式碼:
STL map實現統計的原始碼:
#include<iostream> #include<ctime> #include<fstream> #include<string> #include<map> using namespace std; int main() { clock_t start,end; map<string,int> dict; string word; ifstream in("data.dat"); start = clock(); while(in>>word) { if(dict[word] == NULL) { dict[word] = 1; } else { dict[word]++; } } in.close(); end = clock(); cout<<"STL MAP統計花費的時間為:"<<end-start<<"毫秒"<<endl; map<string,int>::iterator itr = dict.begin(); start = clock(); ofstream out("out.txt"); while(itr != dict.end() ) { out<<itr->first<<" "<<itr->second<<endl; itr++; } end = clock(); cout<<"STL MAP輸出到檔案花費時間為:"<<end-start<<"毫秒"<<endl; out.close(); start = clock(); int sum1=0,sum2=0; ifstream searchIn("search.dat"); while(searchIn>>word) { if(dict[word] != 0) { sum1++; } else { sum2++; } } end = clock(); cout<<"找到單詞:"<<sum1<<"-->"<<"沒有找到單詞:"<<sum2<<endl; cout<<"查詢花費時間:"<<end-start<<endl; return 0; }
字典樹實現原始碼:
下面是兩個程式在release版本下的執行情況:#include<iostream> #include<string.h> #include<fstream> #include<ctime> using namespace std; char str[20];//用於在輸出字典樹中的單詞時使用。 struct Node { int cnt; struct Node *child[26]; Node() { int i; for(i=0; i<26; i++) { child[i] = NULL; } cnt = 0; } }; /* * * 將一個字串插入到字典樹中 * */ void Insert(Node *root, char word[]) { Node *p = root; int i,index; int len = strlen(word); for(i=0; i<len; i++) { index = word[i] - 'a';//這裡是一個hash演算法,只考慮小寫字母的情況 if(p->child[index] == NULL) { p->child[index] = new Node(); } p = p->child[index]; } p->cnt++;//單詞數加1。 } /* * * 字串輸出到檔案 */ void OutToFile(char *word,int cnt) { ofstream out("out.txt",ios::app); out<<word<<" "<<cnt<<endl; out.close(); } /* *將字典樹中的單詞及其出現次數輸出 * */ void OutputWord(Node *p,int length) { int i; if(p->cnt != 0)//找到了一個字串 { str[length] = '\0'; OutToFile(str,p->cnt); } for(i=0; i<26; i++) { if(p->child[i] != NULL) { str[length] = i+'a';//根據下標還原字元 OutputWord(p->child[i],length+1); } } } /** * 查詢word是否在字典樹中 * */ int SearchWord(Node *p,char word[]) { int i,index; int len = strlen(word); for(i=0; i<len; i++) { index = word[i]-'a'; if(p->child[index] == NULL)//沒有找到 { return 0; } p = p->child[index]; } if(p->cnt > 0) { return 1;//找到 } else//字首字串不能算是有這個單詞 { return 0; } } /* * *銷燬字典樹 * */ void DestroyTrieTree(Node *p) { int i; for(i=0; i<26; i++) { if(p->child[i] != NULL) { DestroyTrieTree(p->child[i]); } } delete p; } int main() { Node *Root = new Node(); char word[20]; clock_t start,end; start = clock(); ifstream in("data.dat"); while(in>>word) { Insert(Root,word); } end = clock(); cout<<"使用字典樹進行統計花費時間:"<<end-start<<"毫秒"<<endl; start = clock(); OutputWord(Root,0); end = clock(); cout<<"輸出到檔案花費時間:"<<end-start<<"毫秒"<<endl; in.close(); int sum1=0,sum2=0; start = clock(); ifstream searchIn("search.dat"); while(searchIn>>word)// { if(SearchWord(Root,word) ) { sum1++; } else { sum2++; } } searchIn.close(); end = clock(); cout<<"找到單詞:"<<sum1<<"-->"<<"沒有找到單詞:"<<sum2<<endl; cout<<"查詢花費時間:"<<end-start<<endl; /** 銷燬字典樹 */ for(int i=0; i<26; i++) { if(Root->child[i] != NULL) { DestroyTrieTree(Root->child[i]);//銷燬字典樹 } } return 0; }
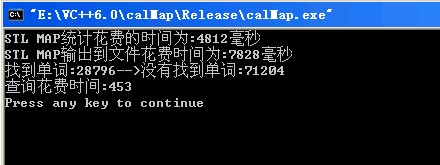

一、執行時間方面:從上面可以看出在統計和查詢過程中使用字典樹的速度明顯優於map。假設字串長度為n,共有m個關鍵字。由於map其底層是由紅黑樹(紅黑樹本質一種排序二叉樹)支援,所以將一個字串插入到map中需要log(m)次才能找到其所在位置。在這log(m)次中每次極端情況下需要進行n次比較。所以往map中插入一個字串需要O(n*log(m))的時間複雜度。對於字典樹從上面的程式中可以看出。插入一個字串只與字串的長度有關而與關鍵字的個數無關,其時間複雜度為O(n)。而在將所有的關鍵字及其出現次數寫到外部檔案時,字典樹花費了巨大的時間。這是由於字典樹的遍歷是遞迴的,大量的時間花在了棧的建立和銷燬上。
二、在記憶體空間使用方面
以插入一個字串a為例,插入到字典樹中正真儲存有用的資料只佔一個空間,另外需要26個空間的指標域。而插入到map,其底層是紅黑樹,資料佔用一個空間;另外再需兩個空間的指標指向其左右孩子。所以在空間使用方面,map使用較少的記憶體空間。
三、適用場合
(1)字典樹及map的比較:1.字典樹在插入和查詢一個的字串的的時間較map快。2.map比字典樹使用更少的記憶體空間。3.在需要在統計的資料寫到外部檔案時,map比字典樹快很多。
(2)字典樹的適用場合:
在不需要將字典樹的資料寫到外部檔案的情況,並對記憶體空間沒有太多要求以及對系統響應要求較高的系統中使用字典樹優於map。比如在12306網站的訂票頁面,在出發地框中輸入bj就會提示“北京”等資訊。
在對系統響應要求不高而對記憶體有限制的系統,以及需要將記憶體中儲存的資料寫到外部檔案的系統使用map優於字典樹。