
Couchbase——查詢View(詳細版)
合法的view定義必須包括一個map函式,具體來說就是包括一個可以把資訊以行為劃分進行輸出的emit()函式。emit()函式所使用的key就是這個view允許的查詢條件範圍。
Key在查詢view時作為過濾引擎使用,具體來說這麼用:
- 單獨的key ———顯示精確匹配這個key的所有結果。
-
若干key ———顯示匹配這若干個key中任意某個的所有結果 。
-
一個範圍內的key —— 顯示匹配在這個範圍內任意某個key的的所有結果。
在查詢view時,可以用一系列引數來特化view的查詢操作以及最終返回的結果,比如限定條件,限定數量,排序等等。
一個沒有任何額外引數特化的view查詢會按照以下規則執行:
-
執行完整的view查詢,比如說所有bucket下的文件都會經過view的處理。
-
Admin介面下返回結果限定10個,REST API下則無數量限制。
-
如果view內定義了reduce函式就使用它.
-
按照UTF-8的比較規則對結果按照升序返回。
view結果按照一個特定順序處理查詢時的引數。處理方式決定了view查詢的寫法和最終的返回結果。
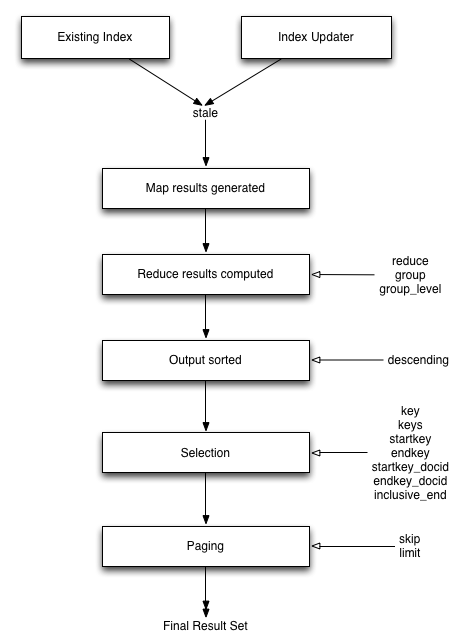
無論是REST API介面還是客戶端的SDK,查詢語句的核心引數和篩選系統都是一樣的。對這些引數的具體設定方法根據客戶端不同而有所區別,不過引數名稱以及支援型別在所有環境下都是一樣的。
使用REST API查詢view
可以通過REST API終端查詢view。REST API支援並使用HTTP協議,而客戶端也是使用相同的協議來獲取資料。
篩選資訊
Couchbase Server 支援諸多篩選方式。Key篩選是在view結果產生之後(包括redution函式),也在產生結果排序之後才開始進行。
給key篩選引擎使用的必須是JSON值。比如說,指定一個單獨的key,如果這是個字串,那麼必須包含在引號內,寫作"key"。
當使用引數進行key篩選時,key必須符合view中emit()函式所使用key的格式。比如說emit()函式使用了一個序列或者hash值之類的複合key,那麼查詢時使用的key也要匹配複合的方式。
Key篩選支援下列方式:
- 單獨的key
使用引數key指明使用單獨key。此時view查詢僅返回精確匹配這個key的結果。
比如說,你以“tomato”為key查詢,那麼就只有完全匹配“tomato”的記錄會被篩選出並返回,而“tomatoes”這種就無法匹配因而不會返回。
- Key 列表
使用引數keys指明要使用一串key篩選。此時序列中每一個key都會被當作單獨的key進行匹配,而key之間用邏輯符or連線。
比如說,keys值是["tomato","avocado"],那麼返回的結果就是精確匹配“tomato“或者”avocado“的記錄。
當使用這個查詢選項時,輸出結果並不是按照key排序的。這是因為對value進行key排序需要在返回結果前收集並排序所有記錄。(也就是排序操作在最後返回結果的那一步執行)
在使用複合key的情況下,每一個複合key都要在查詢中指明,比如說:
```
keys=[["tomato",20],["avocado",20]]
```
- Key 範圍
以startkey起始, endkey結束的key範圍。這兩個引數可以分開用或合起來用:
* `startkey` only
直到view檢索到不小於`startkey`的key值時開始輸出結果,直到view過程結束。
* `endkey` only
直到view檢索到不小於`endkey`的key值時停止輸出結果。
* `startkey` and `endkey`
從不小於`startkey`的key值開始輸出結果,從第一個不小於`endkey`的key值停止輸出結果。使用endkey時,inclusive_end選項指定了輸出是否包括最終的endkey(預設包括)。如果設定為false,輸出將在endkey之前的最後一個記錄停止輸出。
匹配演算法對於不完整key值也是生效的,這是key範圍查詢所必須的。
包括key的複合篩選
如果使用的view產生了複合key,比如說把日期劃分為年月日分別輸出,那麼篩選時候的key也必須匹配這個格式和大小。
看下面的view結果:
{"total_rows":5693,"rows":[
{"id":"1310653019.12667","key":[2011,7,14,14,16,59],"value":null},
{"id":"1310662045.29534","key":[2011,7,14,16,47,25],"value":null},
{"id":"1310668923.16667","key":[2011,7,14,18,42,3],"value":null},
{"id":"1310675373.9877","key":[2011,7,14,20,29,33],"value":null},
{"id":"1310684917.60772","key":[2011,7,14,23,8,37],"value":null},
{"id":"1310693478.30841","key":[2011,7,15,1,31,18],"value":null},
{"id":"1310694625.02857","key":[2011,7,15,1,50,25],"value":null},
{"id":"1310705375.53361","key":[2011,7,15,4,49,35],"value":null},
{"id":"1310715999.09958","key":[2011,7,15,7,46,39],"value":null},
{"id":"1310716023.73212","key":[2011,7,15,7,47,3],"value":null}
]
}
使用key篩選就必須寫全, i.e.:
?key=[2011,7,15,7,47,3]
如果只寫了日期:
?key=[2011,7,15]此時view就不會返回任何結果,因為沒有匹配的記錄。如果其實你這麼寫是因為需要進行範圍查詢,那麼正確的方式是採用key範圍查詢的語法:
?startkey=[2011,7,15,0,0,0]&endkey=[2011,7,15,99,99,99]此時會返回符合這個範圍內的所有結果。
範圍key下的區域性篩選
對key的匹配按照從左到右的優先順序並滿足startkey和/或endkey規定的範圍。因此長度不一樣的字串也可以按照匹配規則處理了。
比如說有下面這些view資料:
"a",
"aa",
"bb",
"bbb",
"c",
"cc",
"ccc"
"dddd"
指定”aa“作為startkey,返回結果就是下面的七個記錄:
"aa",
"bb",
"bbb",
"c",
"cc",
"ccc",
"dddd"字串匹配時遵循從左到右的順序進行比較(通用的字串比較方式)。指定”d“作為startkey就會返回:
"dddd"因為第一個字元不小於”d“的只有”dddd“,所有就得到了這樣的結果。
比較更長的字串和複合值的時候也是同樣的匹配演算法。比如說在資料庫中搜索”almond“為startkey的調料,最終返回結果包括"almond","almonds"和"almond essence"。
如果需要查詢匹配某個單詞或值的整個範圍,那麼需要在endkey中加入null值。舉個例子,在所有記錄中搜索僅以單詞"almond"開頭的記錄,那就指定startkey為"almond",指定endkey為"almond\u02ad"(i.e.以最後一個拉丁字元收尾)。如果是Unicode編碼的字串,你或許應該使用"\uefff"。
startkey="almond"&endkey="almond\u02ad"這個例子中輸出從”almond“開始,在詞典排序大於almond的位置停止輸出。儘管"almond\02ad"這樣的值是永遠不會出現的,但是當key大於這個值時候就會停止輸出。
事實上,這種寫法的效果是字首查詢,也即所有匹配這個字首的記錄會被輸出。
複合key的區域性篩選
複合key(比如說序列或雜湊值)可以對view輸出進行篩選,而且匹配的優先級別可以用來產生複雜的篩選範圍。比如說如果時間按照下述方式對映:
[year,month,day,hour,minute]精確的日期時間範圍可以通過指定特定的key值完成篩選。比如說我們要獲取2011.4.1 00:00至2011.9.30 23:59之間的資料:
?startkey=[2011,4,1,0,0]&endkey=[2011,9,30,23,59]實際上key的結構是彈性的,靈活使用startkey和endkey可以幫助你完成各種方式的篩選。比如說現在我們獲取今年直到3.5的資料:
?startkey=[2011]&endkey=[2011,3,5,23,59]
也可以從某一天開始查詢直到月末:
?startkey=[2011,3,16]&endkey=[2011,3,99]在上面這個例子中,endkey中的day值是個不可能取得的值,不過結合匹配演算法就可以只輸出三月的資料了,跟字串匹配規則其實是一樣的。
這個結構也並非就毫無規則可言,我們必須確保序列中的缺少的值是集中在序列末尾,也即不能從左到右跳過某些值而設定靠後的值。比如說篩選每天從10am到2pm的記錄,你不能這麼寫:
?startkey=[null,null,null,10,0]&endkey=[null,null,null,14,0]分析一下這個邏輯,其實就是不區分年月,所以我們應該這麼寫:
?startkey=[0,0,0,10,0]&endkey=[9999,99,99,14,0]這麼寫就可以實現預期的功能了。
分頁
對返回結果的分頁可以通過使用skip和limit實現。比如說獲取view結果的前10個:
?limit=10
再獲取之後的10個:
?skip=10&limit=10在資料庫中選項skip其實就是跳過這些數量的結果後再開始返回剩餘的結果,直至返回數量達到選項limit的限制(如果設定了選項limit的話)。
當使用更大的skip值進行分頁時,跳過資料的開銷比較大。更高效的解決方法是首先結合limit選項進行第一次查詢並記錄下這次查詢中最後一個結果的document ID,然後使用startkey_docid在第二次查詢中指定從哪個文件開始,先跳過這個文件然後從下一個文件開始輸出結果。
我們來實際演示一下,目標是跳過前10個記錄,獲取之後的10個記錄。
首先進行第一次查詢,獲取第10個記錄的document ID:
?startkey="carrots"&limit=10然後使用剛才拿到的ID進行第二次查詢:
?startkey="carrots"&startkey_docid=DOCID&skip=1&limit=10使用startkey_docid時必須同時使用startkey引數。通過startkey_docid引數,資料庫會直接通過內部的B-Tree檢索到這個ID,這個速度遠快於直接使用skip和limit的方式。
聚合查詢
如果你使用序列形式的複合key來查詢view,那麼可以使用reduce()函式來對輸出結果進行一定程度的聚合。
當可以進行聚合時,view的輸出會根據key序列進行聚合,而你可以使用引數group_level指定聚合的程度。

group_level引數指定聚合在key序列的第幾位發生(位置從1開始),並且根據聚合程度分別輸出聚合後的結果集:
-
0 就是直接返回整個結果集。
-
1就是按照序列第一位將結果集區分開並返回。上面那個示意圖中這個級別就是把資料按照年區分開。
-
n級別的group level就是將結果集按照前n項的不同劃分開。
只要你使用了序列形式的複合key,那麼就可以使用聚合功能對輸出結果進行處理。
聚合篩選
如果要使用key, keys, 或 startkey / endkey進行聚合篩選,那麼最起碼查詢的key值應該符合聚合格式(以及聚合相應需要的元素數量)。
比如說使用下述的map()函式輸出以時間序列為檢索條件的資訊:
function(doc, meta)
{
emit([doc.year, doc.mon, doc.day], doc.logtype);
}如果你需要group_level=2,那麼你查詢的key至少要包含年和月的資訊。比如說你要查詢2012年8月的資訊:
?group=true&group_level=2&key=[2012,8]
你也可以查詢一個時間段內的資訊,比如說2012年2月到8月的資訊:
?group=true&group_level=2&startkey=[2012,2]&endkey=[2012,8]在進行高級別聚合時也是可以進行更細緻的查詢的,也就是先按照查詢邏輯得到一個結果集,然後再按照聚合等級把結果集區分開。比如說我們需要按照年/月的聚合度來區分兩個特定日期之間的資訊:
?group=true&group_level=2&startkey=[2012,2,15]&endkey=[2012,8,10]但是如果複合key的元素個數少於聚合程度所需要的,就會根據篩選引擎對startkey和endkey的處理方式產生無法預期的結果。
排序
所有view輸出的結果都是依據key值自動排序的,而排序主要依據下述的大小排列(由小到大):
-
null
-
false
-
true
-
Numbers
-
Text (大小寫敏感,小寫優先, UTF–8 order)
-
Arrays (按從左到右順序依次比較對應位置元素)
-
Objects (按照從左到右順序一次比較對應位置key值)
這種內建的排序方式很接近對文字和數字的通用排序方式。
沒有外語排序進行特殊處理是否正確,一樣基於UTF-8編碼排序。
你可以使用選項descending來令輸出結果按照降序排列。
因為篩選結果其實實在排序之後執行的,所以如果你設定了降序,那麼相應你的查詢語句也必須以降序為基準來指定key的起始範圍。比如說你要查詢”tomato“和”zucchini“之間的調料:
?startkey="tomato"&endkey="zucchini"
因為預設是升序,所以這麼寫我們就得到了正確的返回結果。
如果返回的結果是降序的:
?descending=true&startkey="tomato"&endkey="zucchini"此時我們就只能得到匹配”tomato“的結果了。因為此時”tomato“才是篩選時候最後看到的,以此為使自然也就只能得到它自己匹配的結果了。
正確的寫法必須交換起始key:
?descending=true&startkey="zucchini"&endkey="tomato"
這就對了。
View的輸出和篩選是大小寫敏感的。如果你指明要精確匹配”Apple“,那麼就不會返回匹配到”apple“或”APPLE“之類僅在大小寫上有所區分的結果。所以對view的輸出結果和查詢時候的條件進行統一的大小寫處理會讓你省心不少,不必考慮大小寫的麻煩事。
理解view的排序規則
Couchbase Server使用基於Unicode的排序演算法,所以你應該明確具體的排序方法。大多數開發者習慣基於ASCII的位元序,當然這也是大多數程式語言在對字串排序時候的方法。
下面是ASCII中的排序優先順序:
123456890 < A-Z < a-z
這種方式意味著任何以數字開頭的記錄都會排在以字母開頭的記錄前;任何以大寫字母開頭的記錄都會排在以小寫字母開頭的記錄前。這也就是說”Apple“永遠排在”apple“前,”Zebra“也在”apple“前。我們把這種方式和couchbase所用的基於Unicode排序的方式比較一下:
123456790 < aAbBcCdDeEfFgGhH...注意這裡也是數字開頭的要排在字母開頭的前面。不過大小寫之間的排序就變化了。這也就是說”apple“會在”Apple“之前,也在”Zebra“之前。另外重音字元按照下述規則排序:
a < á < A < Á < b這也就是說所有a開頭的以及其重音變體都會出現在A開頭和其重音變體之前。
排序示例
位元組序下,索引中的key會按照下述規則排列:
"ABC123" < "ABC223" < "abc123" < "abc223" < "abcd23" < "bbc123" < "bbcd23"同樣的key在couchbase的Unicode排序下會這麼排列:
"abc123" < "ABC123" < "abc223" < "ABC223" < "abcd23" < "bbc123" < "bbcd23"這對於你理解通過startkey和endkey來獲得一個範圍內的結果非常重要。因為基於位元組序和基於Unicode序按照相同起始條件所獲得的結果是不一樣的。
排序和查詢示例
下述示例演示了Couchbase中Unicode排序在範圍查詢中的實際效果。示例基於Couchbase自帶的beer-sample資料。
假設你希望獲取所有以Y開頭的啤酒廠。那麼你的查詢語句應該是這樣的:
startkey="Y"&endkey="z"如果你希望啤酒廠的開頭是y或Y,那麼就要這麼寫:
startkey="y"&endkey="z"這將返回所有以y到z之間字元開頭的結果,但是因為不包括z,所以其實就是y和Y。如果要獲取所有以y開頭啤酒廠,那麼就終止與Y:
startkey="y"&endkey="Y"如果你實際這麼去查詢了就會發現,在beer-sample中沒有一個啤酒廠是以y開頭的。
異常處理
There are a number of parameters that can be used to help control errors and responses during a view query.
在查詢發生錯誤時有若干引數可以對此時的錯誤處理和訊息回覆進行設定。
- on_error
on_error 引數指定view的輸出結果是否遇到錯誤就停止,還是說僅在發生錯誤的節點停止輸出,其它節點正常輸出。
當返回view查詢的資訊時,預設會把查詢中產生的錯誤合併在回覆的JSON文件中,通過這種方式避免錯誤影響整個查詢操作。這樣的處理方式保證了部分節點的故障不會過分影響整個叢集的查詢操作。
為了便於理解,下面就是個把錯誤合併在回覆中的JSON文件:
{
"errors" : [
{
"from" : "http://192.168.1.80:9503/_view_merge/?stale=false",
"reason" : "req_timedout"
},
{
"from" : "http://192.168.1.80:9502/_view_merge/?stale=false",
"reason" : "req_timedout"
},
{
"from" : "http://192.168.1.80:9501/_view_merge/?stale=false",
"reason" : "req_timedout"
}
],
"rows" : [
{
"value" : 333280,
"key" : null
}
]
}如果不希望這種預設的錯誤處理方式,那麼可以修改on_error引數。這個引數的預設值是continue。如果我們把這個值設定為stop,那麼view的查詢操作一旦發生錯誤就會直接終止。此時返回的JSON文件就僅包含第一次發生錯誤的節點資訊。比如這樣子的:
```
{
"errors" : [
{
"from" : "http://192.168.1.80:9501/_view_merge/?stale=false",
"reason" : "req_timedout"
}
],
"rows" : [
{
"value" : 333280,
"key" : null
}
]
}
```