
字串匹配之---BF演算法(暴力破解法)
寫完第一篇字串匹配文章,發現竟然沒有介紹啥是字串匹配演算法,啥是KMP,直接就開講KMP的next陣列有點唐突。而在我打算寫第二篇的時候發現,我們為什麼要有KMP演算法,它到底比普通的演算法好在哪裡?回過頭來想想應該把普通的暴力法也寫寫,這樣才能明白它們的好。同時,不要以為它是暴力法就認為它不好,你沒必要掌握它。同學,你知道嗎?幾乎所有標準庫中類似字串匹配的函式(如: java-indexof)都是採用的我們今天要將的BF(Brute Force)方法,原因見StackOverflow。
好,下面首先正式把問題擺出來,給定兩個串S="s0, s1, s2, ...., sn", T="t0, t1, t2,..., tn", 在主串S中查詢字串T的過程稱為字串匹配問題,T稱為模式串。
一、偽碼
1. 首先設定 S 和 T 的起始比較下標 i 和 j;
2. 迴圈直到 i+m>n 或者T中的字元都比較完(j==m)
2.1 如果S[i]==T[j], 繼續比較S和T的下一個字元,否則2.2 將 i 和 j 回溯,準備下一輪比較
3. 如果T中的字元都比較完(j==m),則返回比較的起始下標
否則返回-1,表示匹配失敗
二、實現
int strStr(const char *S, const char *T){ if(S==NULL||T==NULL) return -1; int n = strlen(S); int m = strlen(T); int i=0; while( i+m<=n){ int k=i, j=0; for(; j<m&&k<n&&S[k]==T[j]; ++k,++j) ; if(j==m) return i; // 匹配成功,返回比較開始位置 ++i; } return -1; // 匹配失敗 }
三、例項
假定給定主串 S="ababcabcacbab", 模式 T="abcac", BF匹配過程如下:
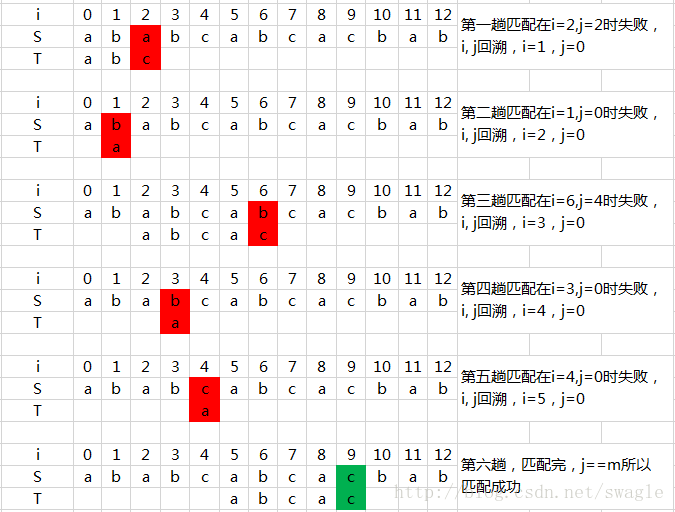
四、BF演算法的缺點
BF演算法的優點就是簡單可靠,這跟現實中的東西一樣,越簡單的東西越是信得過的(純屬娛樂:東哥也說了'她是我見過的最單純的女孩'),可見簡單就是好,而複雜的東西限制要求多。
BF演算法的確定就是一遇到比較失敗的時候就需要回退到前面重新開始比較,之前比較匹配過的資訊完全用不上,一句話就是不智慧嘛。
五、標準庫為啥要採用BF而不採用KMP,BM喃?
開啟上面StackOverflow的連結,就能見著答案,我這裡把英文貼出來,為防止有些童鞋一見English就頭大,大概翻譯了下。
The more advanced string search algorithms have a non-trivial setup time. If you are doing a once-off string search involving a not-too-large target string, you will find that you spend more time on the setup than you save during the string search.And
even just testing the lengths of the target and search string is not going to give a good answer as to whether it is "worth it" to use an advanced algorithm. The actual speedup you get from (say) Boyer-Moore depends on the values of the strings; i.e. the character
patterns.
The Java implementors have take the pragmatic approach. They cannot guarantee that an advanced algorithm will give better performance, either on average, or for specific inputs. Therefore they have left it to the programmer to deal with ... where necessary.
大概意思就是,像KMP,BM這些高階演算法的會有預處理時間和會消耗一些空間,在處理一些不是非常大的字串的時候,時間不會有太大優勢,而且還會佔用一些空間。
另外,我本人開通了微信公眾號--分享技術之美,我會不定期的分享一些我學習的東西. 你可以搜尋公眾號:swalge 或者掃描下方二維碼關注我

(轉載文章請註明出處: http://blog.csdn.net/swagle/article/details/24012567 )