
MapReduce輸入輸出型別、格式及例項
輸入格式
1、輸入分片與記錄
2、檔案輸入
3、文字輸入
4、二進位制輸入
5、多檔案輸入
6、資料庫格式輸入
1、輸入分片與記錄
1、JobClient通過指定的輸入檔案的格式來生成資料分片InputSplit。
2、一個分片不是資料本身,而是可分片資料的引用。
3、InputFormat介面負責生成分片。
InputFormat 負責處理MR的輸入部分,有三個作用:
驗證作業的輸入是否規範。
把輸入檔案切分成InputSplit。
提供RecordReader 的實現類,把InputSplit讀到Mapper中進行處理。
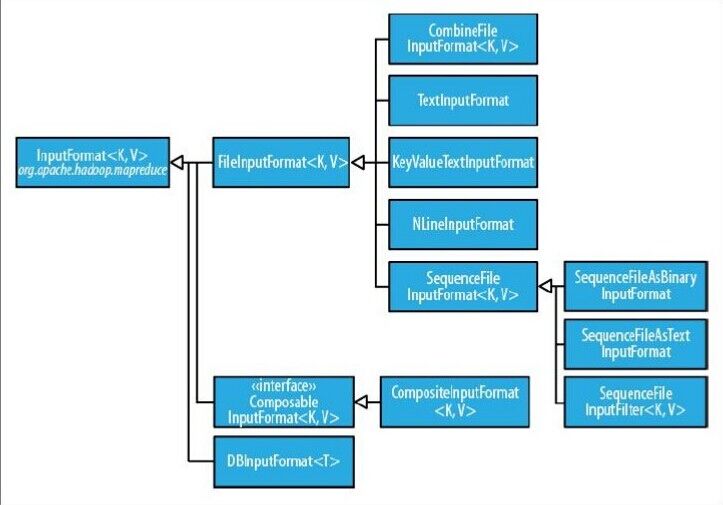
2、檔案輸入
抽象類:FilelnputFormat
1、FilelnputFormat是所有使用檔案作為資料來源的InputFormat實現的基類。
2、FilelnputFormat輸入資料格式的分片大小由資料塊大小決定。
FileInputFormat儲存作為job輸入的所有檔案,並實現了對輸入檔案計算splits的方法。至於獲得記錄的方法是有不同的子類——TextInputFormat進行實現的。
package org.apache.hadoop.mapreduce.lib.input;
public abstract class FileInputFormat<K, V> extends InputFormat<K, V> {
protected 自定義輸入格式
如果我們不需要分片,那我們就需要對isSplitable方法進行重寫
1、繼承FileInputFormat基類。
2、重寫裡面的getSplits(JobContext context)方法。
3、重寫createRecordReader(InputSplit split,TaskAttemptContext context)方法。
詳細例子:
http://blog.csdn.net/scgaliguodong123_/article/details/46492039
InputSplit
在執行mapreduce之前,原始資料被分割成若干split,每個split作為一個map任務的輸入,在map執行過程中split會被分解成一個個記錄(key-value對), map會依次處理每一個記錄。
FileInputFormat只劃分比HDFS block大的檔案,所以FileInputFormat劃分
的結果是這個檔案或者是這個檔案中的一部分。
如果一個檔案的大小比block小,將不會被劃分,這也是Hadoop處理大檔案
的效率要比處理很多小檔案的效率高的原因。
當Hadoop處理很多小檔案(檔案大小小於hdfs block大小)的時候,由於
FileInputFormat不會對小檔案進行劃分,所以每一個小檔案都會被當做一個split並分配一個map任務,導致效率底下。
例如:一個1G的檔案,會被劃分成16個64MB的split,並分配16個map任務處
理,而10000個100kb的檔案會被10000個map任務處理。
Map任務的數量?
一個InputSplit對應一個Map task。
InputSplit的大小是由Math.max(minSize,Math.min(maxSize, blockSize))決定。
單節點一般10-100個map task。map task執行時長不建議低於1 分鐘,否
則效率低。
抽象類:CombineFilelnputFormat
1、可以使用CombineFilelnputFormat來合併小檔案。
2、因為CombineFilelnputFormat是一個抽象類,使用的時候需要建立一個
CombineFilelnputFormat的實體類,並且實現getRecordReader()的方法。
3、避免檔案分法的方法:
A、資料塊大小盡可能大,這樣使檔案的大小小於資料塊的大小,就不用進行分片。(這種方式不太友好)
B、繼承FilelnputFormat,並且重寫isSplitable()方法。
job.setInputFormatClass(CombineTextInputFormat.class);Hadoop2.6.0 CombineTextInputFormat原始碼:
package org.apache.hadoop.mapreduce.lib.input;
/* Input format that is a <code>CombineFileInputFormat</code>-equivalent for <code>TextInputFormat</code>.*/
public class CombineTextInputFormat
extends CombineFileInputFormat<LongWritable,Text> {
public RecordReader<LongWritable,Text> createRecordReader(InputSplit split,
TaskAttemptContext context) throws IOException {
return new CombineFileRecordReader<LongWritable,Text>(
(CombineFileSplit)split, context, TextRecordReaderWrapper.class);
}
/*A record reader that may be passed to <code>CombineFileRecordReader</code> so that it can be used in a <code>CombineFileInputFormat</code>-equivalent for <code>TextInputFormat</code>.*/
private static class TextRecordReaderWrapper
extends CombineFileRecordReaderWrapper<LongWritable,Text> {
// this constructor signature is required by CombineFileRecordReader
public TextRecordReaderWrapper(CombineFileSplit split,
TaskAttemptContext context, Integer idx)
throws IOException, InterruptedException {
super(new TextInputFormat(), split, context, idx);
}
}
}
3、文字輸入
類名:TextlnputFormat
1、TextlnputFormat是預設的lnputFormat,每一行資料就是一條記錄。
2、TextlnputFormat的key是LongWritable型別的,儲存該行在整個檔案的偏移量,value是每行的資料內容,Text型別。
3、輸入分片與HDFS資料塊關係:TextlnputFormat每一條記錄就是一行,很有可能某一行跨資料塊存放。預設以\n或回車鍵作為一行記錄。
4、TextInputFormat繼承了FileInputFormat。

類名:KeyValueTextInputFormat
可以通過設定key為行號的方式來知道記錄的行號,並且可以通過key.value.separator.in.input設定key與value的分割符。
當輸入資料的每一行是兩列,並用tab分離的形式的時候,KeyValueTextInputformat處理這種格式的檔案非常適合。
如果行中有分隔符,那麼分隔符前面的作為key,後面的作為value;如果行中沒有分隔符,那麼整行作為key,value為空。
job.setInputFormatClass(KeyValueTextInputFormat.class);
//預設分隔符就是製表符
//conf.setStrings(KeyValueLineRecordReader.KEY_VALUE
_SEPERATOR, "\t")類名:NLineInputFormat
可以設定每個mapper處理的行數,可以通過mapred.line.input.format.lienspermap屬性設定。
NLineInputformat可以控制在每個split中資料的行數。
//設定具體輸入處理類
job.setInputFormatClass(NLineInputFormat.class);
//設定每個split的行數
NLineInputFormat.setNumLinesPerSplit(job, Integer.parseInt(args[2]));4、二進位制輸入
輸入類:
SequenceFileInputFormat 將key和value以sequencefile格式輸入。
SequenceFileAsTextInputFormat
SequenceFileAsBinaryInputFormat 將key和value以原始二進位制的格式輸入。由於SequenceFile能夠支援Splittable,所以能夠作為mapreduce輸入檔案的格式,能夠很方便的得到己經含有<key,value>的分片。
SequenceFile處理、壓縮處理。
5、多檔案輸入
類名:MultipleInputs
1、MultipleInputs能夠提供多個輸入資料型別。
2、通過addInputPath()方法來設定多路徑。
6、資料庫格式輸入
類名:DBInputFormat
1、DBInputFormat是一個使用JDBC方式連線資料庫,並且從關係型資料庫中讀取資料的一種輸入格式。
2、有多個map會去連線資料庫,有可能造成資料庫崩潰,因此,避免過多的資料庫連線。
3、HBase中的TablelnputFormat可以讓MapReduce程式訪問HBase表裡的資料。
例項單輸入路徑
[root@master liguodong]# hdfs dfs -cat /input.txt
hello you
hello everybody
hello hadoop
[root@master liguodong]# hdfs dfs -text /tmp.seq
15/06/10 21:17:11 INFO bzip2.Bzip2Factory: Successfully loaded & initialized native-bzip2 library system-native
15/06/10 21:17:11 INFO compress.CodecPool: Got brand-new decompressor [.bz2]
100 apache software
99 chinese good
98 james NBA
97 index pass
96 apache software
95 chinese good
94 james NBA
93 index pass
......package mrinputformat;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TestInputFormat {
public static class TokenizerMapper
extends Mapper<IntWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);//1
private Text word = new Text();
public void map(IntWritable key, Text value, Context context
) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
//k v
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
//1、配置
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
//2、打包執行必須執行的方法
job.setJarByClass(TestInputFormat.class);
//3、輸入路徑
//hdfs://master:8020/tmp.seq
//hdfs://master:8020/output
FileInputFormat.addInputPath(job, new Path(args[0]));
//預設是TextInputFormat
job.setInputFormatClass(SequenceFileInputFormat.class);
//4、Map
job.setMapperClass(TokenizerMapper.class);
//5、Combiner
job.setCombinerClass(IntSumReducer.class);
//6、Reducer
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
//7、 輸出路徑
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//8、提交作業
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}執行結果:
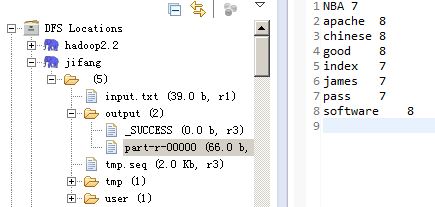
多輸入路徑方式
package mrinputformat;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.SequenceFileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class TestInputFormat {
//採用TextInputFormat
public static class Mapper1
extends Mapper<LongWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);//1
private Text word = new Text();
public void map(LongWritable key, Text value, Context context
) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
//k v
context.write(word, one);
}
}
}
//SequenceFileInputFormat
public static class Mapper2
extends Mapper<IntWritable, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);//1
private Text word = new Text();
public void map(IntWritable key, Text value, Context context
) throws IOException, InterruptedException
{
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
//k v
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values)
{
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
//1、配置
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
//2、打包執行必須執行的方法
job.setJarByClass(TestInputFormat.class);
//3、輸入路徑
//hdfs://master:8020/tmp.seq
//hdfs://master:8020/output
//單個輸入路徑
//FileInputFormat.addInputPath(job, new Path(args[0]));
//預設是TextInputFormat
//job.setInputFormatClass(SequenceFileInputFormat.class);
//4、Map
//job.setMapperClass(TokenizerMapper.class);
//多個輸入路徑
Path path1 = new Path("hdfs://master:8020/input.txt");
Path path2 = new Path("hdfs://master:8020/tmp.seq");
MultipleInputs.addInputPath(job, path1, TextInputFormat.class,Mapper1.class);
MultipleInputs.addInputPath(job, path2, SequenceFileInputFormat.class,Mapper2.class);
//5、Combiner
job.setCombinerClass(IntSumReducer.class);
//6、Reducer
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//7、 輸出路徑
FileOutputFormat.setOutputPath(job, new Path("hdfs://master:8020/output"));
//8、提交作業
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}執行結果:
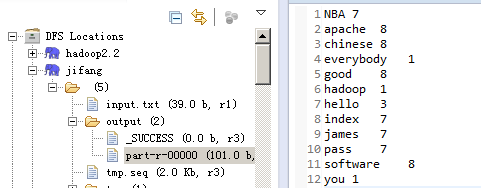
輸出格式
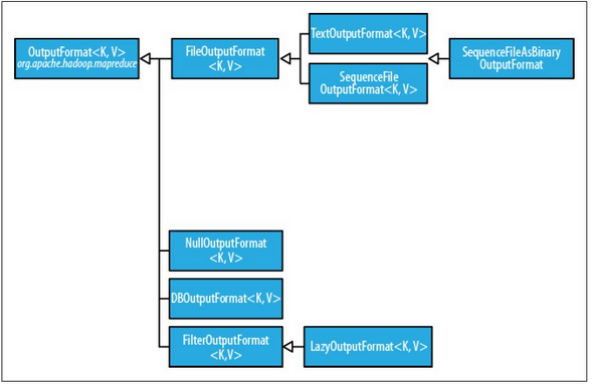
文字輸出
TextOutputFormat
預設的輸出格式,key是LongWritable,value是Text型別, key和value中間值用tab隔開的。
二進位制輸出
SequenceFileOutputFormat
將key和value以sequencefile格式輸出。
SequenceFileAsBinaryOutputFormat
將key和value以原始二進位制的格式輸出。
MapFileOutputFormat
將key和value寫入MapFile中。由於MapFile中的key是有序的,所以寫入的時候必須保證記錄是按key值順序寫入的。

多檔案輸出
MultipleOutputFormat
MultipleOutputs預設情況下一個reducer會產生一個輸出,但是有些時候我們想一個reducer產生多個輸出, MultipleOutputFormat和MultipleOutputs可以實現這個功能。
區別:MultipleOutputs可以產生不同型別的輸出。
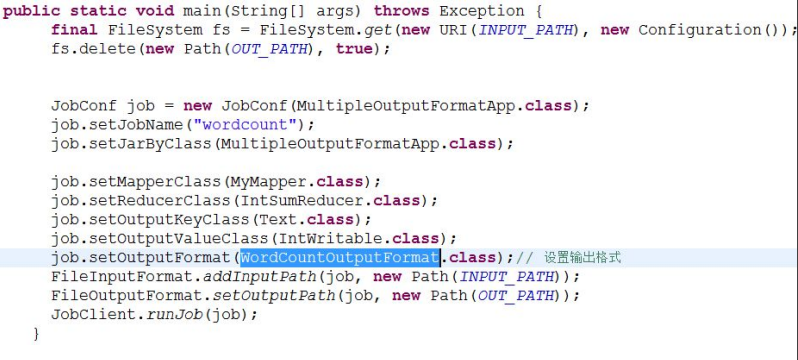
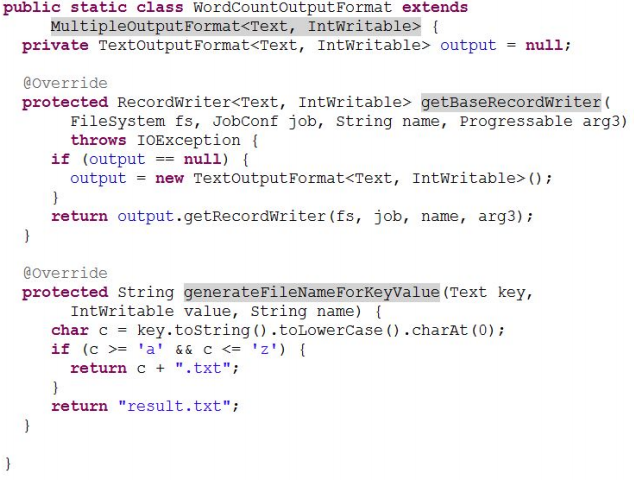
資料庫格式輸出
DBOutputFormat
