
MySQL入門常用命令大全
1.mysql命令簡介
mysql命令是MySQL資料庫的客戶端應用程式,用於解釋執行SQL語句。
2.SQL的六種子語言
SQL(Structured Query Language)是結構化查詢語言,也是一種高階的非過程化程式語言。SQL語句可用於增刪查改資料以及管理關係型資料庫,並不侷限於資料查詢。
關於SQL的組成部分,網上的資料也是眾說紛紜,有些將SQL分為四個子語言,DQL納入DML的一部分,也有些沒有TCL,因為沒有參考到較權威的資料,目前按照百度百科的說法,SQL主要由六個子語言組成,分別是DDL、DQL、DML、DCL、TCL(TPL)和CCL,下面將一一講解。
(1)DCL(Data Control Language,資料控制語言)
用於對資料庫,資料表的訪問角色和許可權的控制等。
GRANT - 授權
REVOKE - 撤銷授權
DENY - 拒絕授權
(2)DDL(Data Definition Language,資料定義語言)
DDL用於定義資料庫的三級結構,包括外模式、概念模式、內模式及其相互之間的映像,定義資料的完整性約束、安全控制等。使我們有能力建立、修改和刪除表格。也可以定義索引和鍵,規定表之間的連結,以及施加表之間的約束。DDL不需要commit,主要操作有:
CREATE - 建立
ALTER - 修改
DROP - 刪除
TRUNCATE - 截斷
COMMENT - 註釋
RENAME - 重新命名
(3)DQL(Data Query Language,資料查詢語言)
其語句,也稱為“資料檢索語句”,用以從表中獲得資料,確定資料怎樣在應用程式給出。保留字SELECT是DQL(也是所有SQL)用得最多的動詞。常用的關鍵字有:
SELECT-從資料庫表中獲取資料
FROM - 指定從哪個資料表或者子查詢中查詢
WHERE - 指定查詢條件
GROUP BY - 結合合計函式,根據一個或多個列對結果集進行分組
HAVING - 對分組後的結果集進行篩選
ORDER BY - 對結果集進行排序
LIMIT - 對結果集進行top限制輸出
UNION - 結果集縱向聯合
JOIN - 結果集橫向拼接
(4)DML(Data Manipulation Language,資料操作語言)
供使用者對資料庫中資料的操作,包括資料的增加、刪除、更新,載入等操作。
UPDATE - 更新資料庫表中的資料
DELETE - 從資料庫表中刪除資料
INSERT INTO - 向資料庫表中插入資料
REPLACE INTO- 向資料庫表中插入資料,如果存在先刪除
LOAD - 載入資料
(5)TCL(Transaction Control Language,事務控制語言)
又名TPL(Transaction Process Language)事務處理語言,它能確保被DML語句影響的表的所有行及時得以更新。TPL語句包括:
START TRANSACTION 或 BEGIN - 開始事務
SAVEPOINT - 在事務中設定儲存點,可以回滾到此處
ROLLBACK - 回滾
COMMIT - 提交
SET TRANSACTION – 改變事務選項
(6)CCL(Cursor Control Language,遊標控制語言)
遊標(cursor)是DBMS為使用者開設的一個數據緩衝區,存放SQL語句的執行結果。遊標控制語言對遊標的操作主要有:
DECLARE CURSOR - 申明遊標
OPEN CURSOR - 開啟遊標
FETCH INTO - 取值
UPDATE WHERE CURRENT - 更新遊標所在的值
CLOSE CURSOR - 關閉遊標
下面將從上面的六個子語言來陳述MySQL的常用SQL語句和MySQL的相關命令。
3.MySQL常用命令
本人使用MySQL版本是5.1.61,下面所有的命令均在本版本MySQL測試通過,如遇到問題,請留言探討!
3.1MySQL準備篇
3.1.1連線到本地MySQL
首先開啟shell命令終端或者命令列程式,鍵入命令mysql -u root -p,回車後提示輸入密碼。注意使用者名稱和密碼與命令選項之間的空格可有可無。
mysql -u[username] -p[password] -A #中括號中的變數需要替換指定值如果剛安裝好MySQL,超級使用者root沒有密碼,直接回車即可進入MySQL,MYSQL的提示符是: mysql>。mysql命令結束使用分號;或者\g。
命令選項-A(–no-auto-rehash)的作用是禁止資料表自動補全。如果資料庫資料表很多,當我們開啟資料庫時,即use dbname時,需要對資料表進行預處理以滿足自動補全的功能,將會很耗時。使用-A可禁止該操作。
3.1.2連線到遠端主機上的MySQL
假設遠端主機的IP為:110.110.110.110,使用者名稱為root,密碼為abc123。則鍵入以下命令:
mysql -h110.110.110.110 -uroot -p123;注:h與IP地址、u與root之間可以不用加空格,p也一樣。
3.1.3退出MySQL
mysql> exit;
#或者
mysql> quit;3.1.4檢視MySQL版本
mysql> select version();
#或者
mysql> status;3.2DCL篇(資料控制篇)
3.2.1新建使用者
#命令格式
mysql> create user [username]@[host] identified by [password];
#示例
mysql> create user lvlv@localhost identified by 'lvlv';
mysql> create user lvlv@192.168.1.1 identified by 'lvlv';
mysql> create user lvlv@"%" identified by 'lvlv';
mysql> CREATE USER lvlv@"%";說明:
username – 你將建立的使用者名稱;
host – 指定該使用者在哪個主機上可以登陸,如果是本地使用者可用localhost,如果想讓該使用者可以從任意遠端主機登陸,可以使用萬用字元%。
password – 該使用者的登陸密碼,密碼可以為空,如果為空則該使用者可以不需要密碼登陸MySQL伺服器。
建立的使用者使用者資訊存放於mysql.user資料表中。
3.2.2刪除使用者
#命令格式
mysql> DROP USER [username]@[host];
#示例
mysql> DROP USER lvlv@localhost;說明:刪除使用者時,主機名要與建立使用者時使用的主機名稱相同。
3.2.3給使用者授權
#命令格式
mysql> GRANT [privileges] ON [databasename].[tablename] TO [username]@[host];
#示例
mysql> GRANT select ON *.* TO [email protected]'%';
mysql> GRANT ALL ON *.* TO [email protected]'%';
#最後不要忘了重新整理許可權
mysql> flush privileges;說明:
(1)privileges – 是一個用逗號分隔的賦予MySQL使用者的許可權列表,如SELECT , INSERT , UPDATE 等(詳細列表見該文末附錄1)。如果要授予所有的許可權則使用ALL;databasename – 資料庫名,tablename-表名,如果要授予該使用者對所有資料庫和表的相應操作許可權則可用*表示,如*.*。
(2)使用GRANT為使用者授權時,如果指定的使用者不存在,則會新建該使用者並授權。設定允許使用者遠端訪問MySQL伺服器時,一般使用該命令,並指定密碼。
#示例
mysql> GRANT select ON *.* TO [email protected]'%' identified by '123456';3.2.4撤銷使用者許可權
#命令格式
mysql> REVOKE [privileges] ON [databasename].[tablename] FROM [username]@[host];
#示例
mysql> REVOKE SELECT ON *.* FROM [email protected]'%';
mysql> REVOKE ALL ON *.* FROM 'lvlv'@'%';說明:
(1)privilege, databasename, tablename – 同授權部分。
(2)假如你在給使用者'pig'@'%'授權的時候是這樣的(或類似 的):GRANT SELECT ON test.user TO 'pig'@'%’, 則在使用REVOKE SELECT ON *.* FROM ‘pig’@'%’;命令並不能撤銷該使用者對test資料庫中user表的SELECT 操作。相反,如果授權使用的是GRANT SELECT ON *.* TO 'pig'@'%’;則REVOKE SELECT ON test.user FROM 'pig'@'%';命令也不能撤銷該使用者對test資料庫中user表的select許可權。
具體資訊可以用命令SHOW GRANTS FOR 'pig'@'%'; 檢視。
3.2.5檢視使用者許可權
方法一:可以從mysql.user表中檢視所有使用者的資訊,包括使用者的許可權。
mysql>select * from mysql.user where user='username' \G方法二:檢視給使用者的授權資訊。
#命令格式
mysql> show grants for [username]@[host];
#示例
mysql> show grants for lvlv@localhost;
mysql> show grants for lvlv;說明:不指定主機名稱,預設為任意主機”%”。
3.2.6修改使用者密碼
方法一:使用SQL語句。
#命令格式:
mysql> SET PASSWORD FOR [username]@[host]= PASSWORD([newpassword]);
#示例
mysql> set password for [email protected]=password('123456');如果是當前登入使用者:
mysql> SET PASSWORD = PASSWORD("newpassword");方法二:使用服務端工具mysqladmin來修改使用者密碼。
#命令格式
mysqladmin -u[username] -p[oldpassword] password [newpassword]
#示例
mysqladmin -ulvlv -p123456 password "123321"3.3DDL篇(資料定義篇)
3.3.1 建立資料庫
#命令格式
mysql> create database [databasename];
#示例
mysql> create database Student;3.3.2 刪除資料庫
#命令格式
mysql> drop database [databasename];
#示例
mysql> drop database Student;3.3.3 檢視所有資料庫
mysql> show databases;3.3.4 檢視當前資料庫
mysql> select database();
#或者
mysql> status;3.3.5連線資料庫
#命令格式
mysql> use [databasename]
#示例
mysql> use Student;3.3.6建立資料表
命令格式:
mysql> create table [表名] ( [欄位名1] [型別1] [is null] [key] [default value] [extra] [comment],
...
)[engine] [charset];說明:上面的建表語句命令格式,除了表名,欄位名和欄位型別,其它都是可選引數,可有可無,根據實際情況來定。is null表示該欄位是否允許為空,不指明,預設允許為NULL;key表示該欄位是否是主鍵,外來鍵,唯一鍵還是索引;default value表示該欄位在未顯示賦值時的預設值;extra表示其它的一些修飾,比如自增auto_increment;comment表示對該欄位的說明註釋;engine表示資料庫儲存引擎,MySQL支援的常用引擎有ISAM、MyISAM、Memory、InnoDB和BDB(BerkeleyDB),不顯示指明預設使用MyISAM;charset表示資料表資料儲存編碼格式,預設為latin1。
儲存引擎是什麼?其實就是如何實現儲存資料,如何為儲存的資料建立索引以及如何更新,查詢資料等技術實現的方法。
主鍵(Primary Key)與唯一鍵(Unique Key)的區別:
(1)主鍵的一個或多個列必須為NOT NULL,而唯一鍵可以為NULL;
(2)一個表只能有一個主鍵,但可以有多個唯一鍵。
以學生表為例,演示資料表的建立。
學生表設計:
| 欄位(Field) | 型別(Type) | 可空(Null) | 鍵(Key) | 預設值(Default) | 其他(Extra) |
|---|---|---|---|---|---|
| 學號(studentNo) | INT UNSIGNED | N | PRI | NULL | auto_increment |
| 姓名(name) | VARCHAR(12) | N | N | NULL | |
| 學院(school) | VARCHAR(12) | N | N | NULL | |
| 年級(grade) | VARCHAR(12) | N | N | NULL | |
| 專業(major) | VARCHAR(12) | N | N | NULL | |
| 性別(gender) | Boolean | N | N | NULL |
建表語句是:
mysql> create table if not exists student(
studentNo int unsigned not null comment '學號' auto_increment,
name varchar(12) not null comment '姓名',
school varchar(12) not null comment '學院',
grade varchar(12) not null comment '年級',
major varchar(12) not null comment '專業',
gender boolean not null comment '性別',
primary key(studentNo)
)engine=MyISAM default charset=utf8 auto_increment=20160001;說明: 上面的建表語句需要注意三點。第一,可以使用if not exists來判斷資料表是否存在,存在則建立,不存在則不建立。第二,設定主鍵時可以將primary key放在欄位的後面來修飾,也可以另起一行單獨來指定主鍵。第三,設定自增時,可以指定自增的起始值,MySQL預設是從1開始自增,比如QQ號是從10000開始的。
關於MySQL支援的資料型別,可參考MySQL 資料型別
3.3.7檢視MySQL支援的儲存引擎和預設的儲存引擎
#檢視所支援的儲存引擎
mysql> show engines;
#檢視預設的儲存引擎
mysql> show variables like '%storage_engine';3.3.8刪除資料表
mysql> drop table [tablename];
#存資料表時才刪除,好處是不會產生warning
mysql> drop table if exists [tablename];
#同時刪除多個數據表
mysql> drop table if exists [tablename0,tablename1,...];3.3.9檢視當前資料庫有哪些資料表
mysql>show tables; #不能使用limit子句
#指定資料庫檢視資料表
mysql>show tables from [databaseName]
#或者
SELECT TABLE_NAME FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA = 'DATABASE_TO SEARCH_HERE' AND TABLE_NAME LIKE "table_here%" LIMIT 5;3.3.10檢視資料表結構
mysql> desc [tablename];
#或者
mysql> describe [tablename];檢視上面建立的student資料表的結構如下:
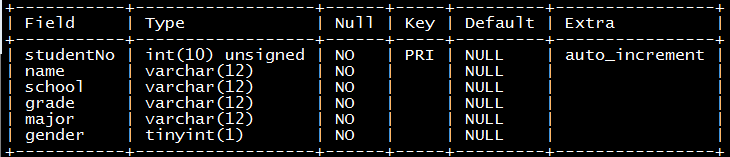
3.3.11檢視建表語句
mysql> show create table [tablename]3.3.12重新命名資料表
mysql> rename table [tablename] to [newtablename];3.3.13增加、刪除和修改欄位自增長
(1)刪除欄位自增長
#命令格式
mysql>alter table [tablename] change [columnname] [columnname] [type];
#示例,取消studentNo的自增長
mysql>alter table student change studentNo studentNo int(10) unsigned;說明:注意列名稱要重複一次,即需要將列的名稱寫兩次。
(2)增加欄位自增長
#命令格式
mysql>alter table [tablename] modify [columnname] [type] auto_increment;
#或者與上面刪除欄位自增長相反
mysql>alter table [tablename] change [columnname] [columnname] [type] auto_increment;
#示例,新增studentNo自增長
mysql>alter table student modify studentNo int(10) unsigned auto_increment;說明:新增自增長的列必須為NOT NULL及PRIMARY KEY(UNIQUE)屬性。如果不是,需新增相應定義。
(3)修改自增長起始值
#命令格式
mysql> alter table [tablename] auto_increment=[value];
#示例,設定studentNo從10000開始自增
mysql> alter table [tablename] auto_increment=10000;注意:設定的起始值value只能大於已有的auto_increment的整數值,小於的值無效。
show table status like 'table_name' 或者show create table [tablename]可以看到auto_increment這一列現有的起始值。
3.3.14增加、刪除和修改資料表的列
(1)增加列
#命令格式
mysql>alter table [tablename] add column [columnname] [columdefinition] [after columnname];
#示例1,為資料表student增加家鄉hometown
mysql>alter table student add column hometown varchar(32) comment '家鄉';
#示例2,在指定列後新增列,而非預設最後一列
mysql>alter table student add column hometown varchar(32) comment '家鄉' after major;
#示例3,同時增加多個列
mysql>alter table student add hometown varchar(32) comment '家鄉' after major,add hobby varchar(128) after hometown;(2)刪除列
#刪除單個列
mysql>alter table [tablename] drop column [columnname];
#刪除多個列
mysql>alter table [tablename] drop [columnname1],drop [columnname2];(3)重新命名列
#命令格式
mysql>alter table [tablename] change [columnname] [newcolumnname] [type];(4)修改列屬性
#命令格式
mysql> alter table [tablename] modify [columnname] [newdefinition];
#示例,修改home型別為varchar(64)且不允許NULL
mysql> alter table student modify home varchar(64) not null;3.3.15新增、刪除和檢視索引
(1)新增索引
#命令格式
mysql> alter table [tablename] add index [indexname](欄位名1,欄位名2…);
#示例,為資料表student資料列studentNo新增索引
mysql> alter table student add index index_studentNo(studentNo);
#或者
mysql> alter table student add index(studentNo);說明: 上面示例的第二種方法,如果不顯示指明索引名稱的話,預設以列名稱作為索引的名稱。新增索引是為了提高查詢的速度。
(2)檢視索引
mysql> show index from [tablename];(3)刪除索引
#命令格式
mysql> alter table [tablename] drop index [indexname];
#示例
mysql> alter table student drop index index_studentNo;3.3.16建立臨時表
#命令格式
mysql> create temporary table [表名] ( [欄位名1] [型別1] [is null] [key] [default value] [extra] [comment],...);
#示例
mysql> create temporary table pig(i int);說明:
(1)建立臨時表與建立普通表的語句基本是一致的,只是多了一個temporary關鍵;
(2)臨時表的特點是:表結構和表資料都是儲存到記憶體中的,生命週期是當前MySQL會話,會話結束後,臨時表自動被drop;
(3)注意臨時表與Memory表(記憶體表)的區別是:
(3.1)Memory表的表結構儲存在磁碟,臨時表的表結構儲存在記憶體;
(3.2)show tables看不到臨時表,看得到記憶體表;
(3.3)記憶體表的生命週期是服務端MySQL程序生命週期,MySQL重啟或者關閉後記憶體表裡的資料會丟失,但是表結構仍然存在,而臨時表的生命週期是MySQL客戶端會話。
(3.4)記憶體表支援唯一索引,臨時表不支援唯一索引;
(3.5)在不同會話可以建立同名臨時表,不能建立同名記憶體表。
3.3.17建立記憶體表
與建立表的命令格式相同,只是顯示的在後面指明儲存引擎為MEMORY。
#命令格式
mysql> create table [表名] ( [欄位名1] [型別1] [is null] [key] [default value] [extra] [comment],...)engine=memory;
#示例
mysql> create table pig(i int)engine=memory;3.3.18修改資料表的儲存引擎
mysql> alter table [tablename] type|engine=[enginename];
#示例,將資料表test儲存引擎設定為InnoDB
mysql> alter table test type=InnoDB;
#或者
mysql> alter table test engine=InnoDB;3.3.19檢視資料庫資料表儲存位置
mysql> show global variables like "%datadir%";3.3.20建立merge表
MERGE儲存引擎把一組MyISAM資料表當做一個邏輯單元來對待,讓我們可以同時對他們進行增刪查改。構成一個MERGE資料表結構的各成員MyISAM資料表結構(索引、引擎、列、字符集等)必須相同。
假設你有幾個日誌資料表,他們內容分別是這幾年來每一年的日誌記錄項,他們的定義都是下面這樣,YY代表年份:
CREATE TABLE log_YY
(
dt DATETIME NOT NULL,
info VARCHAR(100) NOT NULL,
INDEX (dt)
) ENGINE = MyISAM; 假設日誌資料表的當前集合包括log_2015、log_2016、log_2017,而你可以建立一個如下所示的MERGE資料表把他們歸攏為一個邏輯單元:
CREATE TABLE log_merge
(
dt DATETIME NOT NULL,
info VARCHAR(100) NOT NULL,
INDEX(dt)
) ENGINE = MERGE UNION=(log_2015,log_2016,log_2017) INSERT_METHOD=LAST;(1)ENGINE選項的值必須是MERGE或MRG_MyISAM;
(2)UNION選項列出了將被收錄在這個MERGE資料表離得各有關資料表。把這個MERGE表創建出來後,就可以像對待任何其他資料表那樣查詢它,只是每一次查詢都將同時作用與構成它的每一個成員資料表 。下面這個查詢可以讓我們知道上述幾個日誌資料表的資料行的總數:
SELECT COUNT(*) FROM log_merge; (3)除了便於同時引用多個數據表而無需多條查詢,MERGE資料表還提供了以下一些便MERGE資料表也支援DELETE 和UPDATE操作。INSERT操作比較麻煩,因為MySQL需要知道應該把新資料行插入到哪一個成員表裡去。在MERGE資料表的定義裡可以包括一個INSERT_METHOD選項,這個選項的可取值是NO、FIRST、LAST,他們的含義依次是INSERT操作是被禁止的、新資料行將被插入到現在UNION選項裡列出的第一個資料表或最後一個數據表。
(4)對現有的merge表可以刪除或新增包好的資料表,比如新增相同結構的資料表log_2018。
CREATE TABLE log_2009 LIKE log_2008;
ALTER TABLE log_merge UNION=(log_2015, log_2016,log_2017,log_2018);3.3.21清空表內容
truncate [tablename];truncate與delete均可以刪除表記錄,區別主要有如下幾點:
(1)truncate屬於DDL,deleteDML;
(2)truncate用於刪除表中的所有行,delete可以使用where子句有選擇地進行刪除;
(3)delete每次刪除一行,並在事務日誌中為所刪除的每行記錄一項。truncate釋放儲存表資料所用的資料頁來刪除資料,並且只在事務日誌中記錄頁的釋放,所以truncate比delete使用的系統和事務日誌資源更少,效率更高;
(4)truncate導致自動增加欄位的初始值被重置,delete沒有影響,自增欄位的值還是按照最後一次插入的基礎上遞增;
(5)對於由 FOREIGN KEY 約束引用的表,不能使用 truncate,而應使用不帶where子句的delete語句。由於truncate不記錄在日誌中,所以它不能啟用觸發器。
(6)TRUNCATE TABLE 不能用於參與了索引檢視的表。
(7)對用TRUNCATE TABLE刪除資料的表上增加資料時,要使用UPDATE STATISTICS來維護索引資訊。
(8)如果有ROLLBACK語句,DELETE操作將被撤銷,但TRUNCATE不會撤銷。
請記住:當你不再需要該表時用 drop;當你仍要保留該表,但要刪除所有記錄時用 truncate;當你要刪除部分記錄時用 delete。
3.4DQL篇(資料查詢篇)
3.4.1查詢記錄
#命令格式
mysql> SELECT [列名稱] FROM [表名稱] where [條件]說明:一個完整的SELECT語句包含可選的幾個子句。SELECT語句的定義如下:
<SELECT clause> [<FROM clause>] [<WHERE clause>] [<GROUP BY clause>] [<HAVING clause>] [<ORDER BY clause>] [<LIMIT clause>] (1)SELECT子句是必選的,其它子句如WHERE子句、GROUP BY子句等是可選的。
(2)一個SELECT語句中,子句的順序是固定的。例如GROUP BY子句不會位於WHERE子句的前面。
(3) SELECT語句執行順序 :
開始->FROM子句->WHERE子句->GROUP BY子句->HAVING子句->ORDER BY子句->SELECT子句->LIMIT子句->最終結果每個子句執行後都會產生一箇中間資料結果,即所謂的臨時檢視,供接下來的子句使用,如果不存在某個子句,就跳過。MySQL和標準SQL執行順序基本是一樣的。
3.4.2where子句
where子句按所需條件從表中選取資料,如法如下:
SELECT 列名稱 FROM 表名稱 WHERE 列 運算子 值下面的運算子可在 WHERE 子句中使用:
| 運算子 | 描述 |
|---|---|
| = | 等於 |
| <> | 不等於 |
| > | 大於 |
| < | 小於 |
| >= | 大於等於 |
| <= | 小於等於 |
| BETWEEN AND | 在某個範圍內 |
| LIKE | 搜尋某種模式 |
| AND | 多個條件與 |
| OR | 多個條件或 |
(1)where in的用法。
in在where子句中的用法主要有兩種:
(1.1)in 後面是子查詢產生的記錄集,注意,子查詢結果資料列只能有一列且無需給子表新增別名。如:
select * from table where uname in(select uname from user); (1.2)in 後面是資料集合,如:
select * from table where uname in('aaa',bbb','ccc','ddd','eee',ffff''); 注意:如果資料型別是字串,一定要將字串用單引號” 標註起來。
3.4.3group by子句
group by子句中的資料列應該是SELECT 列表中指定的每一列,除非這列是用於聚合函式,如sum()、avg()、count()等。但是,如果select列表中指定的資料列,沒有用於聚合函式也不在group by子句中,按理說會報錯,但是MySQL會選擇第一條顯示在結果集中。
#選擇發起加好友請求次數超過10次的QQ(uin),被加方(to_uin)只會顯示第一個
select uin,to_uin,count(*) as reqCnt from inner_raw_add_friend_20170514 group by uin having reqCnt>10 limit 10;3.4.4where子句與having子句的區別
(1)作用的物件不同。WHERE 子句作用於表和檢視,HAVING 子句作用於組;
#選取QQ 3585076592和3585075773在20170514當天發出加好友請求次數且滿足次數>10
select uin,count(*) as reqCnt from inner_raw_add_friend_20170514 where uin=3585076592 or uin=3585075773 group by uin having reqCnt>10結果:

(2)作用的階段不同。WHERE在分組和聚集計算之前選取輸入行(因此,它控制哪些行進入聚集計算),而 HAVING在分組和聚集之後選取分組。因此,WHERE 子句不能包含聚集函式,因為試圖用聚集函式判斷哪些行輸入給聚集運算是沒有意義的。 相反,HAVING子句一般包含聚集函式。當然,也可以使用 HAVING 對結果集進行篩選,但不建議這樣做,同樣的條件可以更有效地用於 WHERE 階段。
#查詢指定QQ加好友請求資訊(where作用於輸入階段的資料集)
select * from inner_raw_add_friend_20170514 where uin=3585078528;
#等同於having,作用於結果階段的結果集
select * from inner_raw_add_friend_20170514 having uin=3585078528;3.4.5order by子句
ORDER BY語句用於根據指定的列對結果集進行排序。ORDER BY語句預設按照升序對記錄進行排序。如果希望按照降序對記錄進行排序,可以使用 DESC(descend)關鍵字,升序關鍵字是ASC(ascend),隨機則無需指定資料列,使用order by rand()。
#以QQ號碼降序排序
select * from inner_raw_add_friend_20170514 order by uin descend;3.4.6limit 子句
語法格式如下:
LIMIT {[offset,] row_count | row_count OFFSET offset}LIMIT 子句可以被用於強制 SELECT 語句返回指定的記錄數。LIMIT 接受一個或兩個數值引數。引數必須是一個整數常量。如果給定兩個引數,有兩種用法。
第一種:offset,row_count,第一個引數指定返回記錄行的開始偏移量,第二個引數指定返回記錄行的最大數目。初始記錄行的偏移量是0。
第二種:[row_count] OFFSET [offset],第一個引數row_count為返回記錄行的最大數目,第二個引數offset為返回記錄行的開始偏移量。
特殊用法:
(1)只給一個引數,表示返回記錄行的TOP最大行數,起始偏移量預設為0;
(2)返回從起始偏移量開始,返回剩餘所有的記錄,可以使用一些值很大的第二個引數。如檢索所有從第96行到最後一行:
SELECT * FROM tbl LIMIT 95,18446744073709551615;注意,mysql目前不支援使用-1表示返回從偏移量開始,剩餘的所有記錄。
3.4.7distinct用法
(1)在使用mysql時,有時需要查詢出某個欄位不重複的記錄,雖然mysql提供有distinct這個關鍵字來過濾掉多餘的重複記錄只保留一條,但往往只用它來返回不重複記錄的條數。用法如下:
#選擇每一個QQ發起加好友請求涉及到的不同的QQ數
select uin,count(distinct toUin) from addFriend group by uin;(2)distinct用於選擇不同的記錄,且只能放在所選列的開頭,作用於緊隨其後的所有列。示例:
#查詢uin和toUin不重複的加好友請求
select distinct uin,toUin from addFriend;
#示例資料表
uin toUin
10000 123456
10000 121212
10001 121212
10001 131313
#結果集
uin toUin
10000 123456
10000 121212
10001 121212
10001 131313如果想使distinct的功能作用於第二列的toUin,使用distinct是無望了,因為MySQL語法尚不支援,可以使用group by取而代之。
select uin,toUin from addFriend where group by toUin;
#結果集
uin toUin
10000 123456
10000 121212
10001 131313這個奇怪的技巧只能存在於MySQL中,因為標準的SQL語法規定非聚合函式中的列一定要存在於group by子句中。MySQL規定,當非聚合函式中的列不存在於group by子句中,則選擇每個分組的第一行。
(3)count distinct統計符合條件的記錄。
找了很長時間,有兩種方法:
(3.1)可以使用count(distinct case where 條件 then 欄位 end),具體參見MySQL distinct count if conditions unique;
(3.2)使用count(distinct xx,if(use_status=1,true,null)),參見mysql count if distinct。
3.4.8檢查查詢語句的執行效率
mysql> explain [select statement];
#或者
mysql> desc [select statement];檢查的結果類似於如下形式:

如果想以列的方式展示的話,在語句之後加上\G,結果展示類似於如下形式:
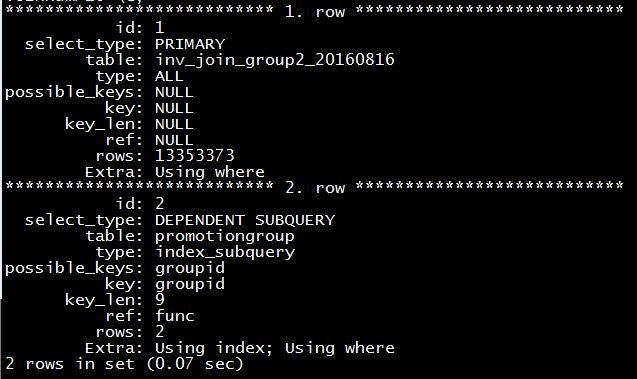
3.4.9 檢視SQL執行時的警告
mysql> show warnings;3.4.10 union的用法
union的作用是將兩次或多次查詢結果縱向聯合起來,使用過程需要注意以下幾點:
(1)union的使用條件
union作用於只要兩個結果集,不能直接作用於原表。結果集的列數相同就可以,即使欄位型別不相同也可以使用。值得注意的是union後欄位的名稱以第一條SQL為準。
(2)union與union all的區別
union用於合併兩個或多個select語句的結果集,並消去聯合後表中的重複行。union all則保留重複行。
(3)關於union的排序
有兩張表,內容如下:

對兩個結果集按照uin進行降序排序後再聯合的結果如下:

可以發現,內層排序沒有發生作用,那現在試試在外層排序。

可見外層排序發生了作用。那是不是內層排序就沒有用了呢,其實換個角度想想內層先排序,如果外層又排序,明顯內層排序顯得多餘,所以MySQL優化了SQL語句,不讓內層排序起作用。要想內層排序起作用,必須要使內層排序的結果能影響最終的結果,如加上limit。

此外,union與join在使用時,有一個本質區別我們必須知道:union只能作用於select結果集,不能直接作用於資料表,join則恰恰相反,只能作用於資料表,不能直接作用於select結果集(可以將select結果集指定別名作為派生表)。
3.4.11 join的用法
(1)select from兩個表與inner join on的區別。
實際測試一下可以看出區別,以a和b表為例:
mysql> select * from a;
+------+------+
| id | col |
+------+------+
| 1 | 11 |
| 2 | 12 |
+------+------+
mysql> select * from b;
+------+------+
| id | col |
+------+------+
| 2 | 22 |
| 3 | 23 |
+------+------+
mysql> select * from a,b;
+------+------+------+------+
| id | col | id | col |
+------+------+------+------+
| 1 | 11 | 2 | 22 |
| 2 | 12 | 2 | 22 |
| 1 | 11 | 3 | 23 |
| 2 | 12 | 3 | 23 |
+------+------+------+------+
mysql> select * from a inner join b on a.id=b.id;
+------+------+------+------+
| id | col | id | col |
+------+------+------+------+
| 2 | 12 | 2 | 22 |
+------+------+------+------+從結果可以看出,select from兩個表的結果是兩張表記錄的笛卡爾乘積,inner join則只拼接含有相同欄位的記錄。
3.4.13檢視資料錶行數
主要有兩種方法。
第一種:
select count(*) from tableName;對於MyISAM資料表很快,建議使用,因為MyISAM資料表事先將行數快取起來,可直接獲取。InnoDB資料表不建議使用,當資料錶行數過大時,因需要掃描全表,查詢較慢。
第二種:
select table_name,table_rows from information_schema.tables where TABLE_SCHEMA = 'DatabaseName' and table_name='TableName'; 第三種:
show table status like 'tableName';第四種:
explain select count(*) from 'tableName';注意:由於InnoDB資料表經常更新,未事先儲存錶行數,所以方法二、三、四對InnoDB資料表所獲得的是一個估算的不精確的結果。
3.5 DML篇(資料操作篇)
3.5.1 插入記錄
(1)iinset into 有三種形式。
insert into tablename(column1,column2,...) values(value1,value2,...);
insert into tablename select...
inse into tablename set column1=value1,column2=value2...
#示例
#插入一行
insert into student(name,school,grade,major,gender) values('lvlv0','software','first year','software engineering',0);
#如果插入值剛好與資料表的所有列一一對應,那麼可以省略書寫插入的指定列
insert into student values(10000,'lvlv0','software','first year','software engineering',0);
#插入多行
insert into student values('lvlv0','software','first year','software engineering',0),('lvlv1','software','first year','software engineering',0);
#使用select結果集進行插入
insert into tablename select * from temp;
#注意,temp資料表的定義要與tablename相同,不同的話,則需要指定需要插入的列,示例如下:
insert into tablename(col0,col1,col2) select col0,col1,col2 from temp;
#使用insert into set
insert into student name='lvlv0', school='software', grade='first year',major='software engineering',gender=0(3)使用replace into進行插入。如果發現表中已經有此行資料(根據主鍵或者唯一索引判斷)則先刪除此行資料,然後插入新的資料。 2. 否則,直接插入新資料
replace into tbl_name(col_name, ...) values(...)
replace into tbl_name(col_name, ...) select ...
replace into tbl_name set col_name=value, ...注意:
(1)REPLACE語句會返回一個數,來指示受影響的行的數目。該數是被刪除和被插入的行數的和。如果對於一個單行REPLACE該數為1,則一行被插入,同時沒有行被刪除。如果該數大於1,則在新行被插入前,有一個或多箇舊行被刪除。如果表包含多個唯一索引,並且新行包含了在不同的唯一索引的舊值,則有可能是一個單一行替換了多箇舊行。
(2)頻繁的REPLACE INTO 會造成新紀錄的主鍵的值迅速增大。總有一天。達到最大值後就會因為資料太大溢位了。就沒法再插入新紀錄了。資料表滿了,不是因為空間不夠了,而是因為主鍵的值沒法再增加了。
(3)如果因唯一索引導致舊行被刪除,新紀錄與老記錄的主鍵值不同,所以其他表中所有與本表老資料主鍵id建立的關聯全部會被破壞。
3.5.2刪除記錄
#命令格式
mysql> delete from [tablename] where<