
Redis中key-value實現原理
實現字典的方法有很多種:
- 最簡單的就是使用連結串列或陣列, 但是這種方式只適用於元素個數不多的情況下;
- 要兼顧高效和簡單性,可以使用雜湊表;
- 如果追求更為穩定的效能特徵, 並且希望高效地實現排序操作的話, 則可以使用更為複雜的平衡樹;
在眾多可能的實現中, Redis 選擇了高效且實現簡單的雜湊表作為字典的底層實現。
dict 型別的 API , 它們的作用及相應的演算法複雜度:
| 操作型別 | 操作 | 函式 | 演算法複雜度 |
|---|---|---|---|
| 建立 | 建立一個新字典 | dictAdd | O(1) |
| 新增或更新給定鍵的值 | dictFind | O(1) | |
| 在字典中查詢給定鍵的值 | dictGetRandomKey | O(N) | |
| 刪除 | 根據給定鍵,刪除字典中的鍵值對 | dictRelease | O(N) |
| 清空並重置(但不釋放)字典 | dictResize | O(N) | |
| 擴大字典 | dictRehash | O(N) | |
| 在給定毫秒內,對字典進行rehash | dict 型別使用了兩個指標分別指向兩個雜湊表。 其中, 0 號雜湊表(ht[1])則只有在程式對 0 號雜湊表進行 rehash 時才使用。 接下來兩個小節將對雜湊表的實現,以及雜湊表所使用的雜湊演算法進行介紹。 雜湊表實現¶字典所使用的雜湊表實現由 table 屬性是一個數組, 陣列的每個元素都是一個指向 dictEntry 都儲存著一個鍵值對, 以及一個指向另一個 next 屬性指向另一個 dictEntry 可以通過 dictht dictht 和數個 dict 型別,那麼整個字典結構可以表示如下: 在上圖的字典示例中, 字典雖然建立了兩個雜湊表, 但正在使用的只有 0 號雜湊表, 這說明字典未進行 rehash 狀態。 雜湊演算法Redis 目前使用兩種不同的雜湊演算法:
|
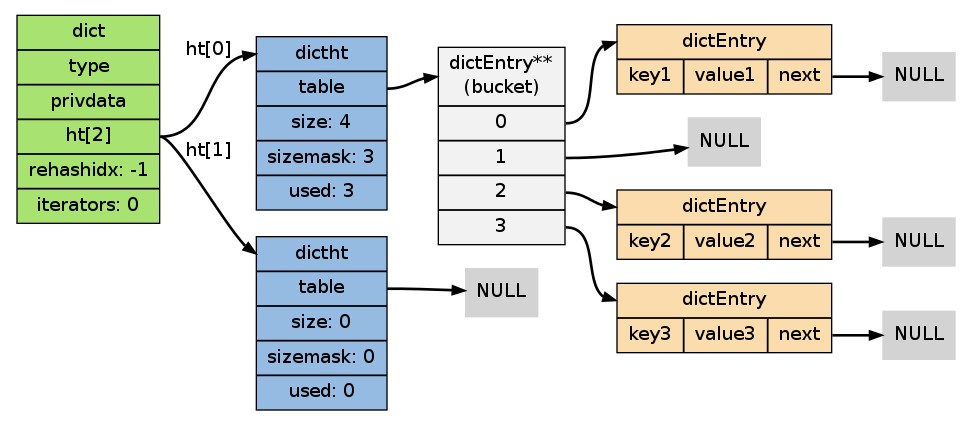
新增鍵值對到字典
根據字典所處的狀態, 將一個給定的鍵值對新增到字典可能會引起一系列複雜的操作:
- 如果字典為未初始化(也即是字典的 0 號雜湊表的
- 字典為空;
- 新增新鍵值對時發生碰撞處理;
- 新增新鍵值對時觸發了 rehash 操作;
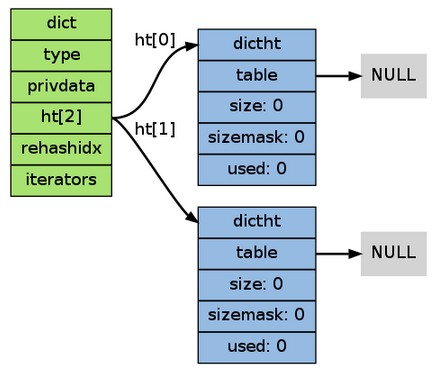
新增新元素到空白字典
當第一次往空字典裡新增鍵值對時, 程式會根據 d->ht[0]->table 分配空間 (在目前的版本中, 4 )。
以下是字典空白時的樣子:
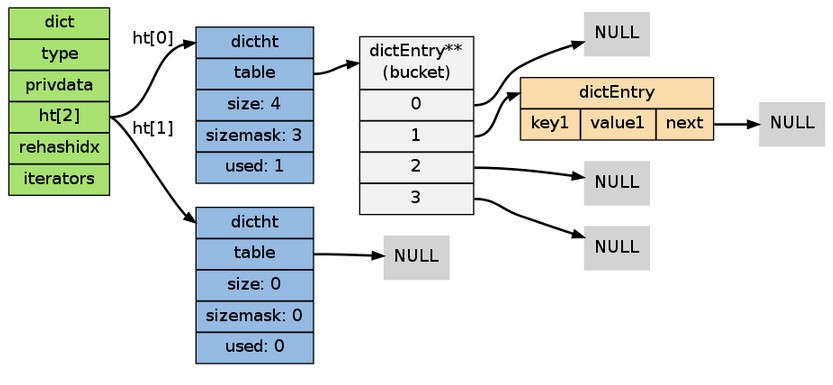
以下是往空白字典添加了第一個鍵值對之後的樣子:
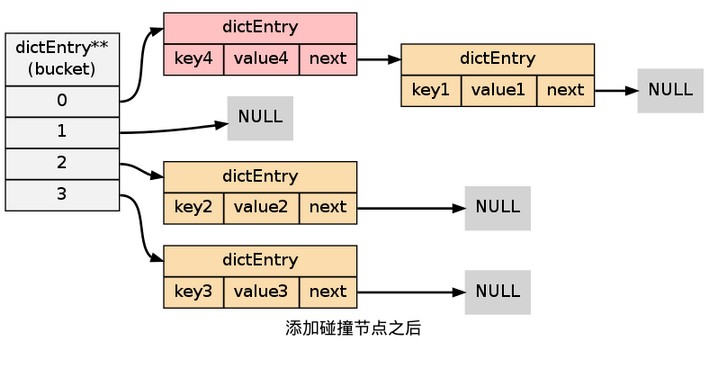
新增新鍵值對時發生碰撞處理
在雜湊表實現中, 當兩個不同的鍵擁有相同的雜湊值時, 我們稱這兩個鍵發生碰撞(collision), 而雜湊表實現必須想辦法對碰撞進行處理。
通過將 key1-value1 兩個鍵值對用連結串列連線起來, 就可以解決碰撞的問題:
新增新鍵值對時觸發了 rehash 操作
對於使用鏈地址法來解決碰撞問題的雜湊表 size屬性)和它所儲存的節點的數量(ht[0])進行 rehash 操作: 在不修改任何鍵值對的情況下,對雜湊表進行擴容, 儘量將比率維持在 1:1 左右。
ht[0] 進行檢查, 對於 size 和 ratio =used / size 滿足以下任何一個條件的話,rehash 過程就會被啟用:
- ratio >= 1 ,且變數
什麼時候 BGSAVE 或 copy on write 機制, 程式會會暫時將 dict_can_resize 會重新被設為真。
另一方面, 當字典滿足了強制 rehash 的條件時, 即使 BGSAVE 或
建立一個比 ht[1]->table ;將 ht[1]->table ;將原有 ht[1] 替換為新的 設定字典的 0 ,標識著 rehash 的開始;為 ht[0]->used 的兩倍;這時的字典是這個樣子:
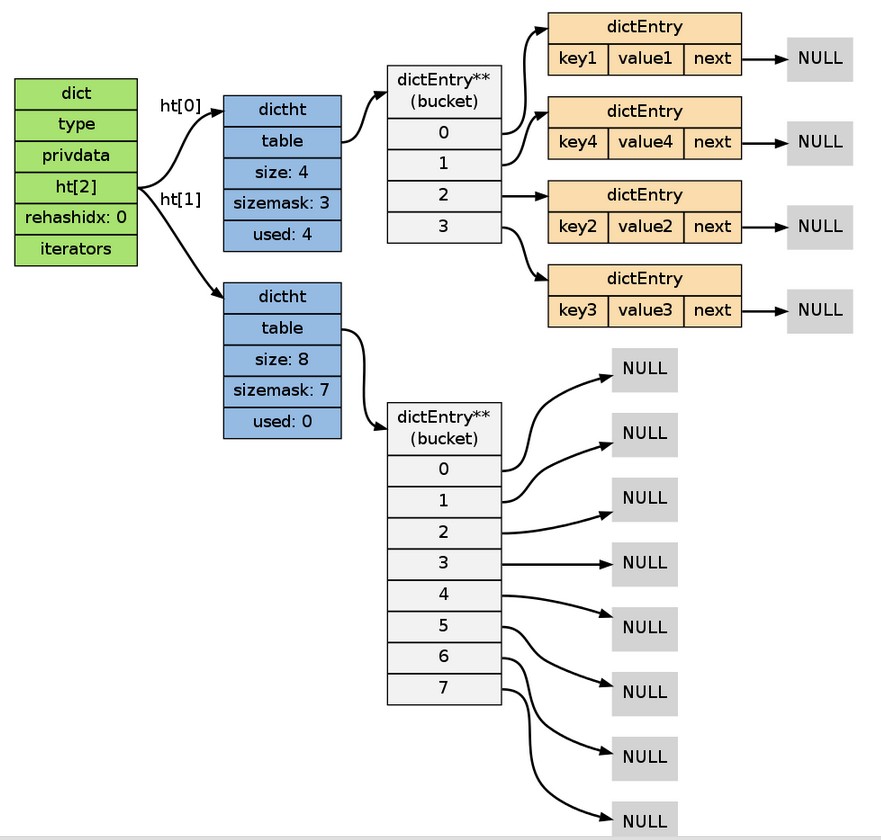
2. Rehash 進行中
在這個階段, ht[1]->table , 因為 rehash 是分多次進行的(細節在下一節解釋), 字典的 ht[0] 的哪個索引位置上。
以下是 2 時,字典的樣子:
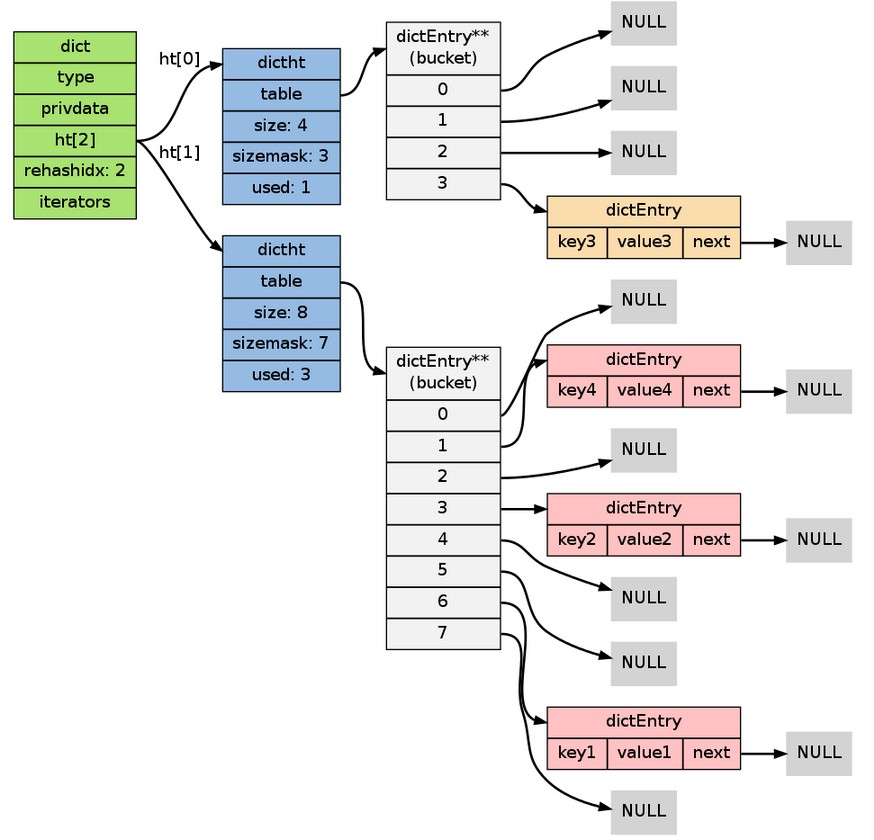
注意除了節點的移動外, 字典的 ht[0]->used 和 ht[0] 遷移到
釋放 ht[1] 來代替 ht[1] 成為新的 ht[1] ;將字典的 -1 ,標識 rehash 已停止;以下是字典 rehash 完畢之後的樣子:
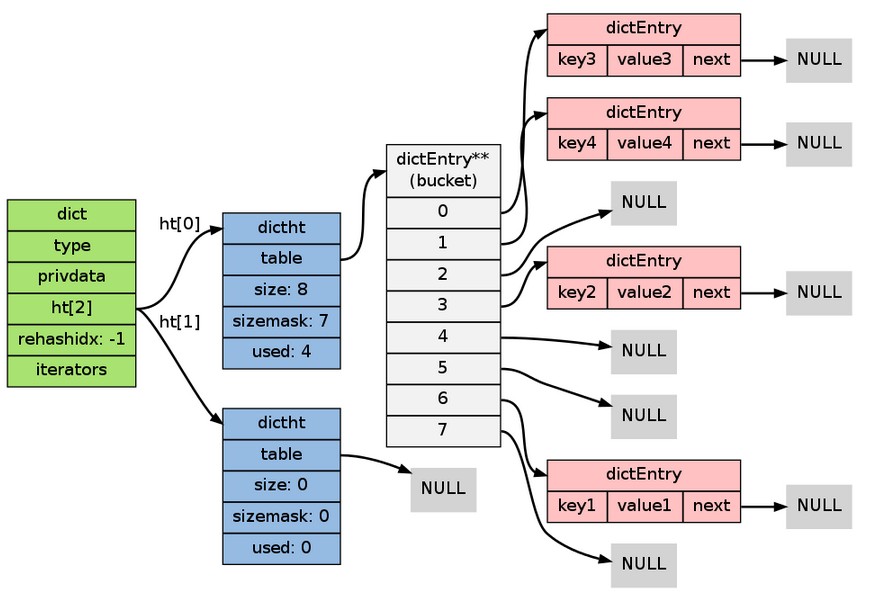
對比字典 rehash 之前和 rehash 之後, 新的 _dictRehashStep 和 _dictRehashStep 用於對資料庫字典、以及雜湊鍵的字典進行被動 rehash ;
_dictRehashStep , ht[1]->table 。在 rehash 開始進行之後(-1), 每次執行一次新增、查詢、刪除操作, dictRehashMilliseconds 可以在指定的毫秒數內, 對字典進行 rehash 。
當 Redis 的伺服器常規任務執行時, ht[0] 上進行,還需要在 ht[1] 而不是 ht[0] 的節點數量在整個 rehash 過程中都只減不增。
字典的收縮
上面關於 rehash 的章節描述了通過 rehash 對字典進行擴充套件(expand)的情況, 如果雜湊表的可用節點數比已用節點數大很多的話, 那麼也可以通過對雜湊表進行 rehash 來收縮(shrink)字典。
收縮 rehash 和上面展示的擴充套件 rehash 的操作幾乎一樣,它執行以下步驟:
- ht[0]->table 小的
擴充套件 rehash 和收縮 rehash 執行完全相同的過程, 一個 rehash 是擴充套件還是收縮字典, 關鍵在於新分配的 ht[1]->table 比 ht[1]->table 比 資料庫》一章的《迭代器實現 —— 對字典進行迭代實際上就是對字典所使用的雜湊表進行迭代:
- 迭代器首先迭代字典的第一個雜湊表, 然後,如果 rehash 正在進行的話, 就繼續對第二個雜湊表進行迭代。
- 當迭代雜湊表時, 找到第一個不為空的索引, 然後迭代這個索引上的所有節點。
- 當這個索引迭代完了, 繼續查詢下一個不為空的索引, 如此迴圈, 一直到整個雜湊表都迭代完為止。
整個迭代過程可以用偽程式碼表示如下:
def iter_dict(dict):# 迭代 0 號雜湊表
iter_table(ht[0]->table)
# 如果正在執行 rehash ,那麼也迭代 1 號雜湊表
if dict.is_rehashing(): iter_table(ht[1]->table)
def iter_table(table):
# 遍歷雜湊表上的所有索引
for index in table:
# 跳過空索引
if table[index].empty():
continue
# 遍歷索引上的所有節點
for node in table[index]:
# 處理節點
do_something_with(node)
字典的迭代器有兩種:
- 安全迭代器:在迭代進行過程中,可以對字典進行修改。
- 不安全迭代器: 在迭代進行過程中,不對字典進行修改。
以下是迭代器的資料結構定義:
/** 字典迭代器
*/
typedef struct dictIterator {
dict *d; // 正在迭代的字典int table, // 正在迭代的雜湊表的號碼(0 或者 1) index, // 正在迭代的雜湊表陣列的索引 safe; // 是否安全?
dictEntry *entry, // 當前雜湊節點*nextEntry; // 當前雜湊節點的後繼節點
} dictIterator;
以下函式是這個迭代器的 API ,它們的作用及相關演算法複雜度:
| 函式 | 作用 | 演算法複雜度 |
|---|---|---|
| dictGetSafeIterator | 建立一個安全迭代器。 | O(1) |
| NULL 。 | O(1) | |
| <tt literal"="" style="background-color: transparent; color: rgb(34, 34, 34); font-size: 1.1em;">dictReleaseIterator | 釋放迭代器。 | O(1) |
小結¶
- 字典由鍵值對構成的抽象資料結構。
- Redis 中的資料庫和雜湊鍵都基於字典來實現。
- Redis 字典的底層實現為雜湊表,每個字典使用兩個雜湊表,一般情況下只使用 0 號雜湊表,只有在 rehash 進行時,才會同時使用 0 號和 1 號雜湊表。
- 雜湊表使用鏈地址法來解決鍵衝突的問題。
- Rehash 可以用於擴充套件或收縮雜湊表。
- 對雜湊表的 rehash 是分多次、漸進式地進行的。