
Spark任務執行詳解
在上一篇文章中,威廉展示瞭如何構建一個簡單的Spark叢集,本文將介紹如何在Spark叢集上部署執行我們的程式
首先來看下Spark的簡要工作流程
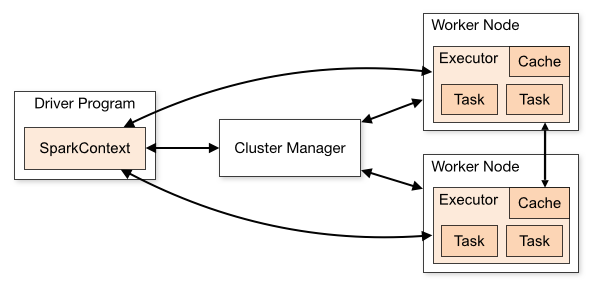
Spark應用執行在各自獨立的程序中,由主程式(也被稱為driver程式)中的SparkContext物件協調管理。SparkContext可連線到多種cluster manager,包括Spark本身提供的standalone cluster manager,以及YARN,Mesos。成功連線後,SparkContext會請求在Worker/Slave主機上執行executor程序用於管理資料,處理運算,並將JAR包或.py檔案傳送給executor
SparkContext傳送task給executor執行
以下幾點值得注意:
- 應用有各自獨立的
executor程序,多執行緒處理task,不同應用的task執行在不同的JVM中,這樣有利於不同任務的隔離,但也導致了在不同應用中,若不依靠外部資料儲存,資料將無法共享 - Spark對於
cluster manager是不可知的,不會影響到如YARN,Mesos等上執行的其他程式 driver程式監聽executor連線,介面可以通過spark.driver.port,spark.fileserver.port配置,需保證這些介面可以被executor連線到driver程式需要和executor通訊,因此最好能保證它們處於同一網段;若不得不將driver啟動在遠端主機上,最好能開啟RPC(遠端過程呼叫協議),以減少driver和executor之間的通訊時間
Spark支援執行Scala,Java及Python編寫的應用,並提供了Python及Scala的Shell
Scala Shell
./bin/spark-shell --master local[2]表示在本地使用2執行緒執行scala shell,更多引數可以通過./bin/spark-shell --help查閱
[email protected]:~/spark-1.3.1-bin-hadoop2.6 當前log level為預設的INFO,可以看到許多詳細的資訊,對於我們以後的詳細學習很有幫助;但目前我們覺得log太多了點,於是可以修改conf/log4j.properties,使warning以上級別的log才會在控制檯中顯示
log4j.rootCategory=WARN, consolePython Shell
./bin/pyspark --master local[2]與Scala Shell類似的啟動命令,修改log level之後,這次我們看到log資訊就少了許多
[email protected]:~/spark-1.3.1-bin-hadoop2.6/bin$ ./pyspark --master local[2]
Python 2.7.6 (default, Mar 22 2014, 22:59:56)
[GCC 4.8.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
15/05/13 08:44:20 WARN Utils: Your hostname, master resolves to a loopback address: 127.0.1.1; using 192.168.32.130 instead (on interface eth0)
15/05/13 08:44:20 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
15/05/13 08:44:21 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 1.3.1
/_/
Using Python version 2.7.6 (default, Mar 22 2014 22:59:56)
SparkContext available as sc, HiveContext available as sqlContext.
>>> 在Spark Shell中可以進行一些互動式的操作,但更普遍的情況是打包部署完整的程式提交到Spark來執行
Spark_submit
Spark提供了spark_submit指令碼來處理程式的提交,其具體使用格式是這樣的
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # 其他選項
<application-jar> \
[application-arguments]- Python應用的提交較為簡單,只需把
.py檔案放置在<application-jar>的位置,並可以用--py-files引數來對應引用的.zip .egg .py檔案 - deploy_mode有client(預設),cluster兩種
- client:使用
spark_submit本身程序執行driver程式,控制檯進行輸入輸出,使用者需要和worker主機處在同一網段,比如直接登入到master主機進行操作的使用者,並且適合互動式操作,如Shell - cluster:
driver程式將被部署到worker主機,以減少driver與executor間的通訊成本,適用於在叢集以外的遠端主機提交應用的情況;目前不支援Mesos叢集及Python程式
- client:使用
- 使用
cluster模式部署在Spark Standalone Cluster的情況,可以新增--supervise引數來保證driver在任務失敗時自行重新提交
Spark_submit例項
# 本地8執行緒
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[8] \
/path/to/examples.jar \
100
# client deploy mode執行在Spark Standalone cluster
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# client deploy mode執行在Spark Standalone cluster,任務失敗自動重新提交
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--deploy-mode cluster
--supervise
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# 執行在YARN叢集上
export HADOOP_CONF_DIR=XXX
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn-cluster \ # can also be `yarn-client` for client mode
--executor-memory 20G \
--num-executors 50 \
/path/to/examples.jar \
1000
# 在Spark Standalone cluster上執行Python程式
./bin/spark-submit \
--master spark://207.184.161.138:7077 \
examples/src/main/python/pi.py \
1000Master URL設定
| Master URL | 含義 |
|---|---|
| local | 本地單執行緒 |
| local[K] | 本地K執行緒 |
| local[*] | 本地最大執行緒,與CPU核數相同 |
| spark://HOST:PORT | Spark Standalone Cluster,埠預設7077 |
| mesos://HOST:PORT | Mesos Cluster,埠預設5050 |
| yarn-client | YARN cluster,client模式,需配置HADOOP_CONF_DIR環境變數 |
| yarn-cluster | YARN cluster,cluster模式,需配置HADOOP_CONF_DIR環境變數 |
配置檔案
Spark-submit預設會讀取conf/spark-defaults.conf的配置資訊,也可通過--conf引數來提供,還有在程式中通過SparkConf物件設定;這幾種方法的優先順序為SparkConf > --conf > spark-defaults.conf
新增--verbose引數到Spark-submit會在log中記錄各項配置引數是從何而來的
檔案傳輸方式
Spark-submit支援以下幾種JAR,.py的URL格式,對應不同的傳輸方式
| URL | 含義 |
|---|---|
| 絕對路徑, file: | executor從driver的HTTP file server獲取檔案 |
| hdfs:, http:, https:, ftp: | executor通過相應協議從driver獲取檔案 |
| local: | executor從本地獲取檔案,需保證檔案存在於每個executor本身的檔案系統,這種模式減少了網路傳輸的成本 |
值得注意的是,隨著執行的程式增多,傳輸到executor的程式檔案會佔據越來越多的儲存空間。YARN叢集擁有自動清理的功能,Spark Standalone叢集需要通過spark.worker.cleanup.appDataTtl屬性來設定自動清理
本文所涉及資訊來源於
1. Spark官方文件 https://spark.apache.org/docs/latest/
2. OReilly Learning Spark Lightning-Fast Big Data Analysis
相關推薦
Spark任務執行詳解
在上一篇文章中,威廉展示瞭如何構建一個簡單的Spark叢集,本文將介紹如何在Spark叢集上部署執行我們的程式 首先來看下Spark的簡要工作流程 Spark應用執行在各自獨立的程序中,由主程式(也被稱為driver程式)中的SparkContext物件
Linux下的crontab定時執行任務命令詳解
crontab命令常見於Unix和類Unix的作業系統之中,用於設定週期性被執行的指令。該命令從標準輸入裝置讀取指令,並將其存放於“crontab”檔案中,以供之後讀取和執行。該詞來源於希臘語 chronos(χρνο),原意是時間。通常,crontab儲存的指令被守護
Linux下的cron定時執行任務命令詳解
部落格引用處(以下內容在原有部落格基礎上進行補充或更改,謝謝這些大牛的部落格指導): Linux下的crontab定時執行任務命令詳解 在LINUX中,週期執行的任務一般由cron這個守護程序來處理[ps -ef|grep cron]。cron讀取一個或多個配置檔案,這些配置檔案中包含了
Spark on yarn Intellij ide 安裝,編譯,打包,叢集執行 詳解
說明:已經安裝好hadoop2.2.0 完全分佈,scala,spark已安裝好,環境配置完畢;主機為hadoop-master,hadoop-slave 一.intellij 安裝(centos6.5系統) 步驟一。 1.將上述兩個安裝
【Spark工作機制詳解】 執行機制
Spark主要包括 排程與任務分配、I/O模組、通訊控制模組、容錯模組 、 Shuffle模組。 Spark 按照 ①應用 application ②作業 job ③ stage ④ task 四個層次進行排程,採用經典的FIFO和FAIR等排程演
spring框架使用Quartz執行定時任務例項詳解
Quartz簡介 1.Quartz,是一個完全由java編寫的開源作業排程框架。它包含了排程器監聽、作業和觸發器監聽,而我們在專案中最常用到的就是它可以作為一個定時器,可以隨時配置監聽、觸發任務進行作業。 2.在Spring的框架裡,Quartz已經
通過Spark Rest 服務監控Spark任務執行情況
com 理想 ask cin *** lib add pan etime 1、Rest服務 Spark源為了方便用戶對任務做監控,從1.4版本啟用Rest服務,用戶可以通過訪問地址,得到application的運行狀態。 Spark的REST API返回的信息是JS
Linux定時任務cron詳解
setenv 這樣的 設置 結果 詳解 ron editor tor 其他 摘要:相信不少linux愛好者們或開發過程中都在使用Linux環境吧。其中crontab就是一個非常強大的定時任務執行器。比如我們可以設置好何時執行任務的腳本,系統會在指定的時間內開始任務
Linux crontab 定時任務命令詳解
-1 data new ubuntu 時間間隔 服務 run back use Linux Crontab 定時任務 命令詳解 [日期:2016-02-13] 來源:Linux社區 在工作中需要數據庫在每天零點自動備份所以需要建立一個定時任務.我選擇在Linux下使用
spark on yarn詳解
.sh 提交 cut com blog sta clu ... client模式 1、參考文檔: spark-1.3.0:http://spark.apache.org/docs/1.3.0/running-on-yarn.html spark-1.6.0:http://s
linux定時任務crontab詳解
將不 絕對路徑 lin csdn 似的 文件內容 關閉 HERE 自動啟動 1、Crontab程序 crontab命令常見於Unix和類Unix的操作系統之中,用於設置周期性被執行的指令。 crontab文件包含送交cron守護進程的一系列作業和指令。每個用戶可以擁
spark的rdd詳解1
操作 spa img cal 選擇 分享圖片 分區 並行 方式 1,rdd的轉換和行動操作 2,創建rdd的2種方式 1,通過hdfs支持的文件系統,沒有真正把數據放rdd,只記錄了一下元數據 2,通過scala的集合或者數組並行化的創建rdd 3,
Java定時任務工具詳解之Timer篇
java 定時任務 定時 任務調度 什麽 出身 需要 bsp 機制 Java定時任務調度工具詳解 什麽是定時任務調度? ◆ 基於給定的時間點,給定的時間間隔或者給定的執行次數自動執行的任務。 在Java中的定時調度工具? ◆ Timer ◆Quartz Time
Spark函數詳解系列之RDD基本轉換
9.png cal shuff reac 數組a water all conn data 摘要: RDD:彈性分布式數據集,是一種特殊集合 ? 支持多種來源 ? 有容錯機制 ? 可以被緩存 ? 支持並行操作,一個RDD代表一個分區裏的數據集 RDD有兩種操作算子: Tra
深入理解spark-rdd詳解
彈性 gem exc .com drive image 都是 spa ima 1.我們在使用spark計算的時候,操作數據集的感覺很方便是因為spark幫我們封裝了一個rdd(彈性分布式數據集Resilient Distributed Dataset); 那麽rdd
saltstack安裝及遠端執行詳解
salt安裝 第一步 主機名區分好,十分關鍵 centos7 設定主機名方式 hostnamectl set-hostname centos7 1 在master節點上 192.168.255.128 curl -o /etc/yum.repos.d/epel-
大資料篇:Spark入門第一個Spark應用程式詳解:WordCount
任務要求 編寫一個Spark應用程式,對某個檔案中的單詞進行詞頻統計。 備註:本文spark的根目錄名:spark-1.6.3-bin-hadoop2.6 #準備工作 cd /usr/local/spark-1.6.3-bin-hadoop2.6 mkdir mycode
CUDA之Thread、Wrap執行詳解
從硬體角度分析,支援CUDA的NVIDIA 顯示卡,都是由多個multiprocessors 組成。每個 multiprocessor 裡包含了8個stream processors,其組成是四個四個一組,也就是兩組4D的處理器。每個 multiprocessor 還具有 很多個(比如8192個)暫
Spark常用運算元詳解彙總 : 實戰案例、Java版本、Scala版本
官網API地址: JavaRDD:http://spark.apache.org/docs/latest/api/scala/index.html#org.apache.spark.api.java.JavaRDD JavaPairRDD:http://spark.apache.or
【小家java】Java定時任務ScheduledThreadPoolExecutor詳解以及與Timer、TimerTask的區別
相關閱讀 【小家java】java5新特性(簡述十大新特性) 重要一躍 【小家java】java6新特性(簡述十大新特性) 雞肋升級 【小家java】java7新特性(簡述八大新特性) 不溫不火 【小家java】java8新特性(簡述十大新特性) 飽受讚譽 【小家java】java9