
【Caffe實踐】基於Caffe的人臉檢測實現
0. 引言
深度學習可以說是在人臉分析相關領域遍地開花,近年來在人臉識別,深度學習在人臉檢測,人臉關鍵點檢測中有很廣泛的應用,這篇文章中,初步實現了基於深度學習CNN的人臉檢測。
1. 方法討論
深度學習一般沒有進行直接的檢測,現有的檢測大多都是基於分類的檢測,主要的方法有兩種:
1.1. 基於滑動視窗的分類
最典型的方法就是OverFeat那一套,其主要的方法是:對於每一個尺度、每一個可能的滑動視窗,進行分類。其主要的缺點是:對於稍微大一點的影象,滑動視窗往往有好幾百萬個之多,所以直接利用這個方法往往速度比較的慢。
如果只是對每一個滑動視窗進行分類的話,那速度的確會變得非常的慢,但是,卷積有一個顯著的優點就是權值共享,它可以很好的進行計算結果的重複利用。所以最後基於CNN的全卷積網路速度也不會特別的慢。
1.2. 基於目標顯著性方法
最典型的方法是R-CNN那一套,其主要的方法是:先快速的檢測可能的目標區域塊,然後用訓練好的深度網路模型進行特徵提取,之後再進行分類。它主要解決的問題就是基於滑動視窗的目標檢測方法視窗過多的問題。
然而這種方法可能不適合於人臉檢測,因為人臉是屬於區域性目標,而顯著目標檢測通常用來檢測通用的完整目標區域。
在這裡,我實現的是基於滑動視窗的檢測方法,利用caffe的機制,直接將訓練好了的網路模型轉換為全卷積網路,從而實現直接輸入任意影象的大小。
2. 實驗步驟
2.1. 資料生成
首先是樣本的取樣,需要的是兩類資料,人臉影象和非人臉影象。可以用自己喜歡的方法進行人臉框和非人臉框的選取,並把擷取的人臉影象塊分別放在face-images 和no-face-images 資料夾中。
在這裡需要注意的一點是:如果隨機取樣,很有可能正負資料及其的不平衡,從而導致網路無法訓練,需要特別注意。
緊接著是將資料轉換為LMDB,這一點其實挺重要的,直接的檔案列表雖然方便,但是訓練速度會比LMDB格式的低5倍左右,而且LMDB或者LevelDB支援更多的資料預處理方法。
利用如下指令碼:{convert_data_lmdb.sh},可以將資料轉化為LMDB。
略2.2. 網路配置
由於我們是用來做人臉二分類,所以沒有必要訓練一個非常大的網路,小一點的就可以,我這邊是改進DeepID的網路,採用人臉影象大小是48*48 彩色影象。當然你也可以直接那別人訓練好了的網路進行微調處理。
網路結構圖如下所示:
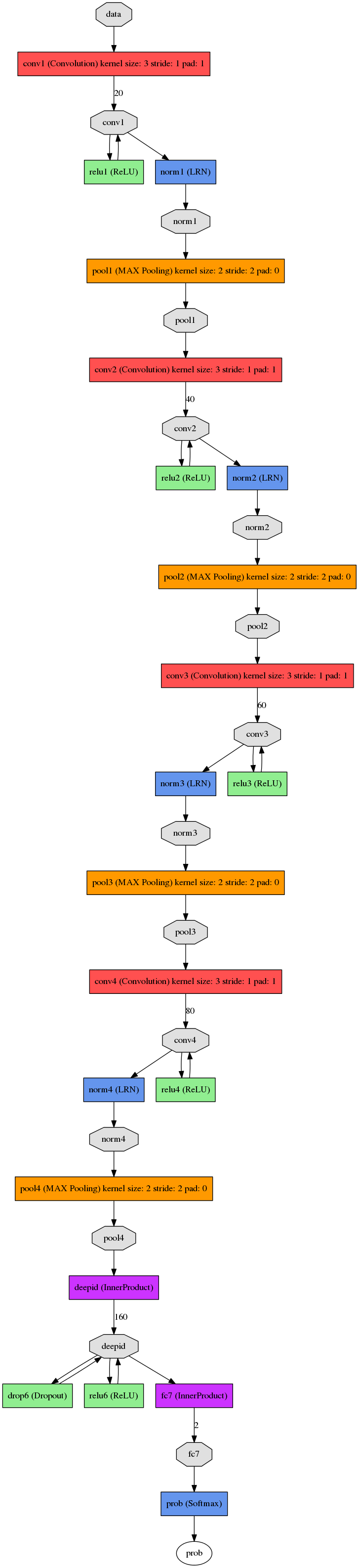
完整的訓練引數及其檔案在最後面的連結檔案給出。。
2.3. 訓練網路
訓練網路也跟普通的所有的分類網路訓練一樣。
配置好相對應的路徑和超引數,在當前路徑下,執行
./train.sh由於是二分類,網路收斂的很快,差不多幾萬個迭代就可以達到99%以上的二分類精度。
3. 測試
3.1. 網路轉換
訓練好了的人臉二分類器,不能直接應用於人臉檢測,需要進行轉換為全卷積網路的格式,具體的方法在Caffe官網上有詳細的說明,這裡不再贅述。
關鍵程式碼如下:
略3.2. 非極大值閾值
直接使用了這個程式碼,已經實現了非極大值閾值。
3.3. 人臉檢測
主要程式碼如下:
略4. 實驗結果
4.1. 響應圖
其中,顏色越紅的地方出現就是檢測器判斷人臉出現的地方。
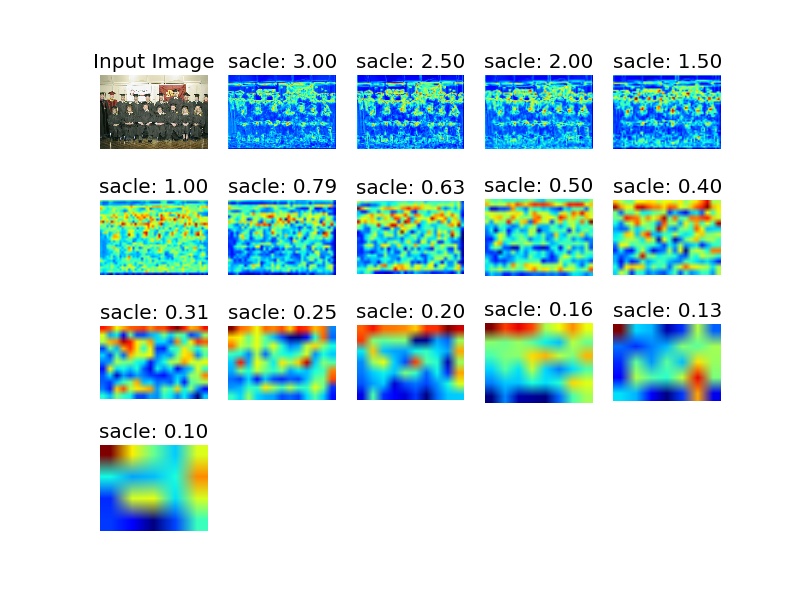
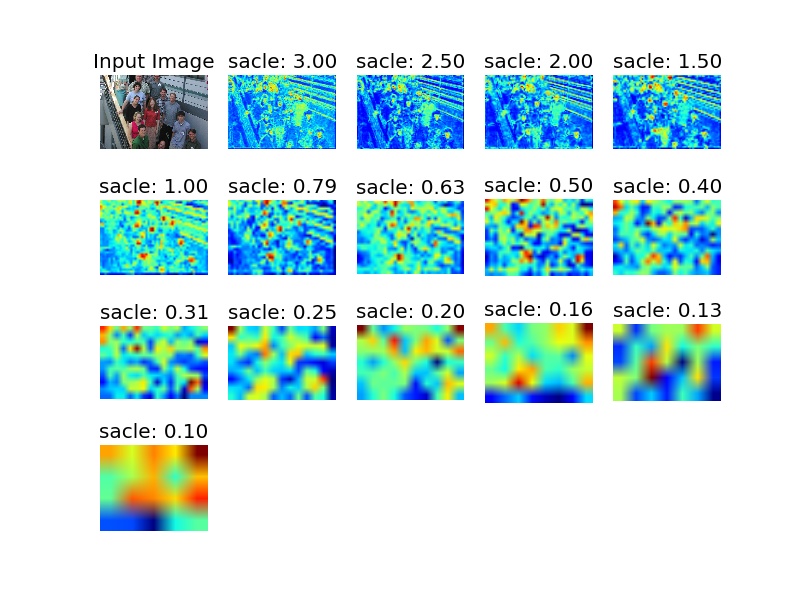
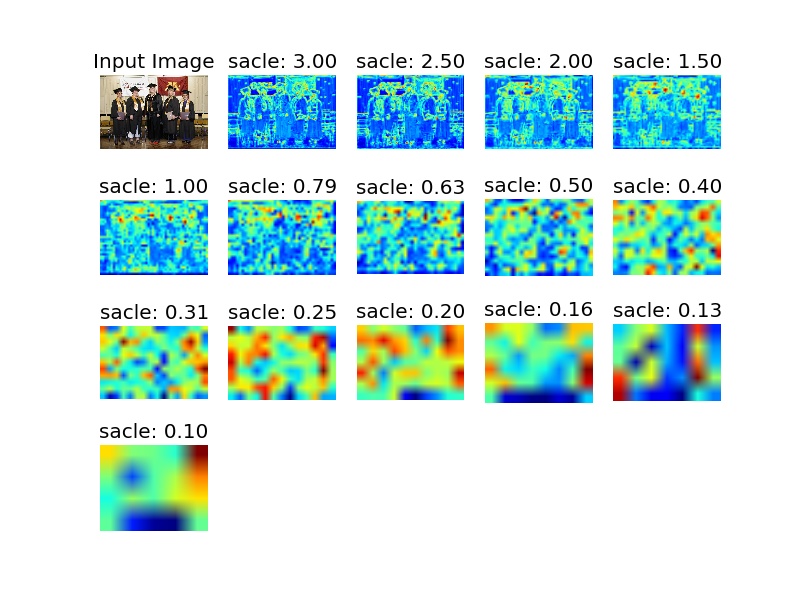
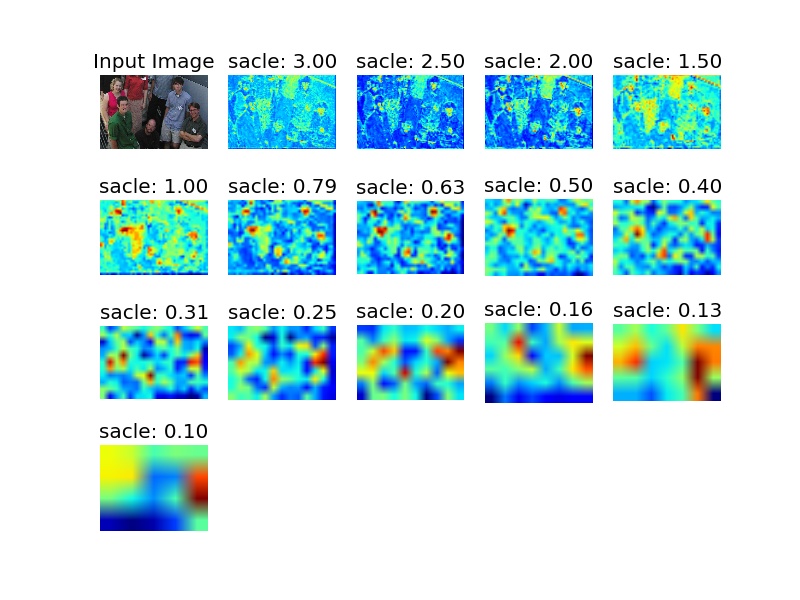
4.2 檢測結果圖

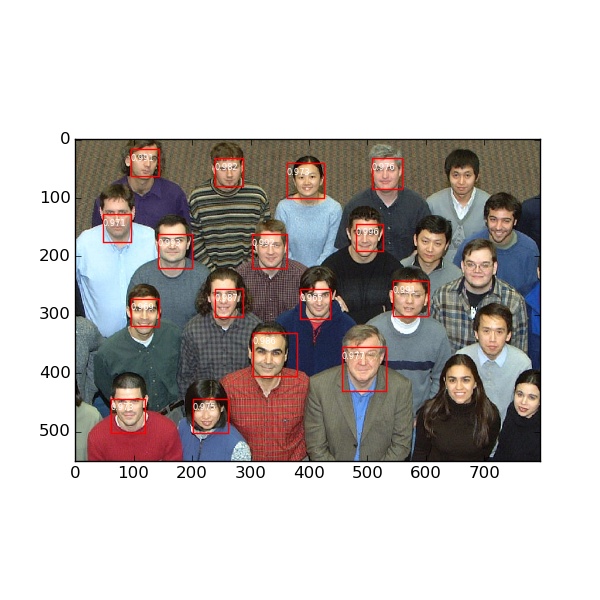


這裡面已經設定了比較高的閾值,不然誤檢率會很高。
5. 討論
1,閾值的設定,是在準確率和召回率之前的權衡。
2,基於以上方法,定位還不夠準確。
所有程式碼
PS: 如果對你有幫助,還請點個star吧